【Python3之常用模块】
一、time
1.三种表达方式
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。命令如下:
import time
print(time.time())
输出
1496667277.8989
- 格式化的时间字符串(Format String)
import time
print(time.strftime("%Y-%m-%d %X"))
输出
2017-06-05 20:55:48
补充:
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时),分为本地时区的struct_time和UTC时区的struct_time
世界标准时间,国际协调时间,简称UTC,不属于任意时区,中国大陆、中国香港、中国澳门、中国台湾、蒙古国、新加坡、马来西亚、菲律宾、西澳大利亚州的时间与UTC的时差均为+8,也就是UTC+8。
import time print(time.localtime())
print(time.gmtime())
输出
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=5, tm_hour=20, tm_min=57, tm_sec=51, tm_wday=0, tm_yday=156, tm_isdst=0)
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=5, tm_hour=12, tm_min=57, tm_sec=51, tm_wday=0, tm_yday=156, tm_isdst=0)
补充:
很多Python函数用一个元组装起来的9组数字处理时间:
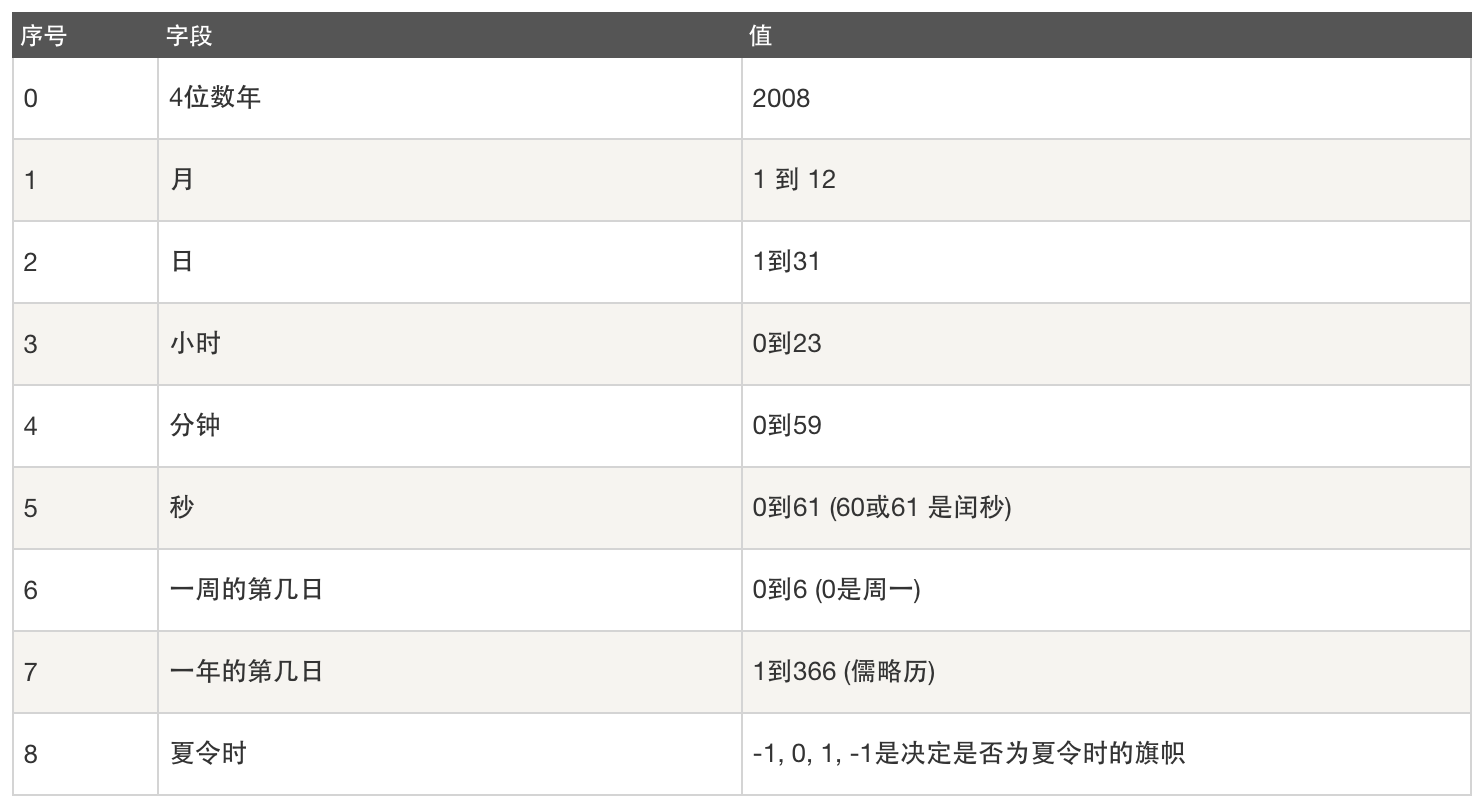
对应的属性:

2.三种方式间互相转换
其中计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间' ,于是有了下图的转换关系
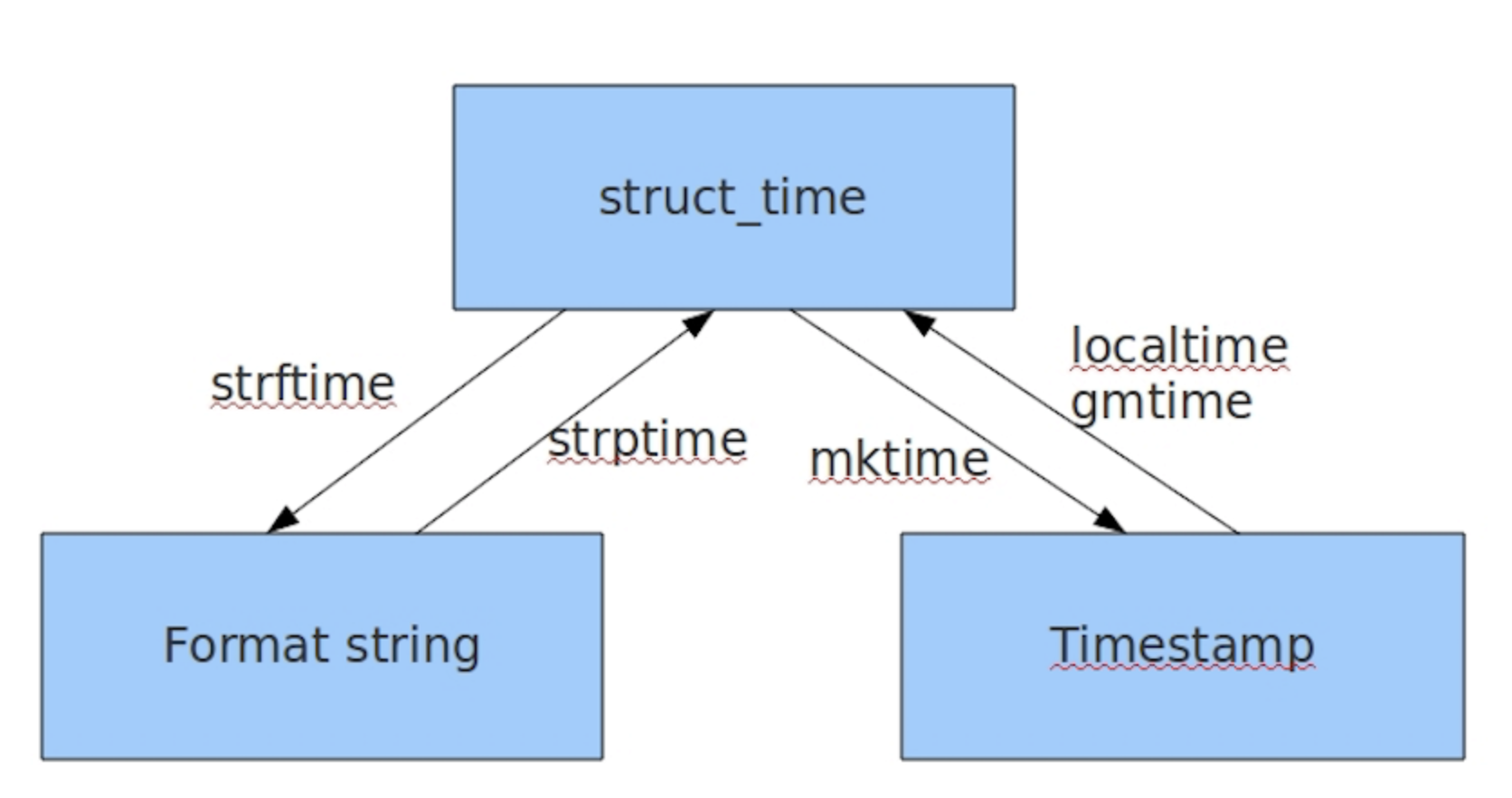
具体如下:
- time.localtime([secs]
接收时间辍(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。
import time
print(time.time())
print(time.localtime(1496669119.460393))
输出
1496669128.140584
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=5, tm_hour=21, tm_min=25, tm_sec=19, tm_wday=0, tm_yday=156, tm_isdst=0)
- time.gmtime([secs])
接收时间辍(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0
import time
print(time.time())
print(time.gmtime(1496669119.460393))
输出
1496669289.290523
time.struct_time(tm_year=2017, tm_mon=6, tm_mday=5, tm_hour=13, tm_min=25, tm_sec=19, tm_wday=0, tm_yday=156, tm_isdst=0)
- time.mktime(t)
mktime() 函数执行与gmtime(), localtime()相反的操作,它接收struct_time对象作为参数,返回用秒数来表示时间的浮点数。如果输入的值不是一个合法的时间,将触发 OverflowError 或 ValueError。
import time t = (2017, 6, 5, 22, 3, 38, 1, 48, 0)
secs = time.mktime( t )
print ("time.mktime(t) : %f" % secs)
print ("asctime(localtime(secs)): %s" % time.asctime(time.localtime(secs)))
输出
time.mktime(t) : 1496671418.000000
asctime(localtime(secs)): Mon Jun 5 22:03:38 2017
- time.strftime(fmt[,tupletime])
接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。
import time
print (time.strftime("%Y-%m-%d %H:%M:%S"))
- time.strptime(str,fmt='%a %b %d %H:%M:%S %Y')
根据fmt的格式把一个时间字符串解析为时间元组。
import time
print (time.strptime("30 Nov 00", "%d %b %y"))
输出
time.struct_time(tm_year=2000, tm_mon=11, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=335, tm_isdst=-1)
补充:
- time.sleep(secs)
推迟调用线程的运行,secs指秒数。
import time
print ("Start : %s" % time.ctime())
time.sleep( 5 )
print ("End : %s" % time.ctime())
输出
Start : Mon Jun 5 21:45:13 2017
End : Mon Jun 5 21:45:18 2017

- time.asctime([tupletime])
接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。
import time
t = time.localtime()
print ("time.asctime(t): %s " % time.asctime(t))
输出
time.asctime(t): Mon Jun 5 21:52:55 2017
- time.ctime([secs])
作用相当于asctime(localtime(secs)),未给参数相当于asctime()
import time
print ("time.ctime() : %s" % time.ctime())
输出
time.ctime() : Mon Jun 5 21:54:49 2017
二、random
- 从一个序列中随机的抽取一个元素,可以使用
random.choice() - 为了提取出N个不同元素的样本用来做进一步的操作,可以使用
random.sample() - 如果你仅仅只是想打乱序列中元素的顺序,可以使用
random.shuffle() - 生成随机整数,请使用
random.randint() - 生成0到1范围内均匀分布的浮点数,使用
random.random()
例:
import random print(random.random())#大于0且小于1之间的小数
print(random.randint(1,3)) #大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #大于等于1且小于3之间的整数
print(random.choice([1,'',[4,5]]))
print(random.sample([1,'',[4,5]],2))#列表元素任意2个组合
print(random.uniform(1,3))#大于1小于3的小数 item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌"
print(item)
输出
0.23127504367736695
1
2
[4, 5]
[1, '']
2.202096727179022
[9, 5, 7, 1, 3]
应用:生成随机验证码
import random
def v_code():
code = ''
for i in range(5):
num=random.randint(0,9)
alf=chr(random.randint(65,90))
add=random.choice([num,alf])
code += str(add)
return code
print(v_code())
输出
KDZSY
三、OS
os模块是与操作系统交互的一个接口
os.access(path, mode) # 检验权限模式
os.chdir(path) # 改变当前工作目录
os.chflags(path, flags) # 设置路径的标记为数字标记。
os.chmod(path, mode) # 更改权限
os.chown(path, uid, gid) # 更改文件所有者
os.chroot(path) # 改变当前进程的根目录
os.close(fd) # 关闭文件描述符 fd
os.closerange(fd_low, fd_high) # 关闭所有文件描述符,从 fd_low (包含) 到 fd_high (不包含), 错误会忽略
os.curdir # 返回当前目录:('.')
os.dup(fd) # 复制文件描述符 fd
os.dup2(fd, fd2) # 将一个文件描述符 fd 复制到另一个 fd2
os.environ # 获取系统环境变量
os.fchdir(fd) # 通过文件描述符改变当前工作目录
os.fchmod(fd, mode) # 改变一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限。
os.fchown(fd, uid, gid) # 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定。
os.fdatasync(fd) # 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息。
os.fdopen(fd[, mode[, bufsize]]) # 通过文件描述符 fd 创建一个文件对象,并返回这个文件对象
os.fpathconf(fd, name) # 返回一个打开的文件的系统配置信息。name为检索的系统配置的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定(POSIX.1, Unix 95, Unix 98, 和其它)。
os.fstat(fd) # 返回文件描述符fd的状态,像stat()。
os.fstatvfs(fd) # 返回包含文件描述符fd的文件的文件系统的信息,像 statvfs()
os.fsync(fd) # 强制将文件描述符为fd的文件写入硬盘。
os.ftruncate(fd, length) # 裁剪文件描述符fd对应的文件, 所以它最大不能超过文件大小。
os.getcwd() # 返回当前工作目录
os.getcwdu() # 返回一个当前工作目录的Unicode对象
os.isatty(fd) # 如果文件描述符fd是打开的,同时与tty(-like)设备相连,则返回true, 否则False。
os.lchflags(path, flags) # 设置路径的标记为数字标记,类似 chflags(),但是没有软链接
os.lchmod(path, mode) # 修改连接文件权限
os.lchown(path, uid, gid) # 更改文件所有者,类似 chown,但是不追踪链接。
os.link(src, dst) # 创建硬链接,名为参数 dst,指向参数 src
os.listdir(path) # 返回path指定的文件夹包含的文件或文件夹的名字的列表。
os.lseek(fd, pos, how) # 设置文件描述符 fd当前位置为pos, how方式修改: SEEK_SET 或者 0 设置从文件开始的计算的pos; SEEK_CUR或者 1 则从当前位置计算; os.SEEK_END或者2则从文件尾部开始. 在unix,Windows中有效
os.lstat(path) # 像stat(),但是没有软链接
os.linesep # 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.major(device) # 从原始的设备号中提取设备major号码 (使用stat中的st_dev或者st_rdev field)。
os.makedev(major, minor) # 以major和minor设备号组成一个原始设备号
os.makedirs(path[, mode]) # 递归文件夹创建函数。像mkdir(), 但创建的所有intermediate-level文件夹需要包含子文件夹。
os.minor(device) # 从原始的设备号中提取设备minor号码 (使用stat中的st_dev或者st_rdev field )。
os.mkdir(path[, mode]) # 以数字mode的mode创建一个名为path的文件夹.默认的 mode 是 0777 (八进制)。
os.mkfifo(path[, mode]) # 创建命名管道,mode 为数字,默认为 0666 (八进制)
os.mknod(filename[, mode=0600, device]) # 创建一个名为filename文件系统节点(文件,设备特别文件或者命名pipe)。
os.open(file, flags[, mode]) # 打开一个文件,并且设置需要的打开选项,mode参数是可选的
os.openpty() # 打开一个新的伪终端对。返回 pty 和 tty的文件描述符。
os.pathconf(path, name) # 返回相关文件的系统配置信息。
os.pathsep # 用于分割文件路径的字符串
os.pardir # 获取当前目录的父目录字符串名:('..')
os.pipe() # 创建一个管道. 返回一对文件描述符(r, w) 分别为读和写
os.popen(command[, mode[, bufsize]]) # 从一个 command 打开一个管道
os.path.abspath(path) # 返回path规范化的绝对路径
os.path.split(path) # 将path分割成目录和文件名二元组返回
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) # 如果path是绝对路径,返回True
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
os.name # 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.read(fd, n) # 从文件描述符 fd 中读取最多 n 个字节,返回包含读取字节的字符串,文件描述符 fd对应文件已达到结尾, 返回一个空字符串。
os.readlink(path) # 返回软链接所指向的文件
os.remove(path) # 删除路径为path的文件。如果path 是一个文件夹,将抛出OSError; 查看下面的rmdir()删除一个 directory。
os.removedirs(path) # 递归删除目录。若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.rename(src, dst) # 重命名文件或目录,从 src 到 dst
os.renames(old, new) # 递归地对目录进行更名,也可以对文件进行更名。
os.rmdir(path) # 删除path指定的空目录,如果目录非空,则抛出一个OSError异常。
os.sep # 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.stat(path) # 获取path指定的路径的信息,功能等同于C API中的stat()系统调用。
os.stat_float_times([newvalue]) # 决定stat_result是否以float对象显示时间戳
os.statvfs(path) # 获取指定路径的文件系统统计信息
os.symlink(src, dst) # 创建一个软链接
os.system("bash command") # 运行shell命令,直接显示
os.tcgetpgrp(fd) # 返回与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组
os.tcsetpgrp(fd, pg) # 设置与终端fd(一个由os.open()返回的打开的文件描述符)关联的进程组为pg。
os.tempnam([dir[, prefix]]) # 返回唯一的路径名用于创建临时文件。
os.tmpfile() # 返回一个打开的模式为(w+b)的文件对象 .这文件对象没有文件夹入口,没有文件描述符,将会自动删除。
os.tmpnam() # 为创建一个临时文件返回一个唯一的路径
os.ttyname(fd) # 返回一个字符串,它表示与文件描述符fd 关联的终端设备。如果fd 没有与终端设备关联,则引发一个异常。
os.unlink(path) # 删除文件路径
os.utime(path, times) # 返回指定的path文件的访问和修改的时间。
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]]) # 输出在文件夹中的文件名通过在树中游走,向上或者向下。
os.write(fd, str) # 写入字符串到文件描述符 fd中. 返回实际写入的字符串长度
四、sys
sys模块用于提供对python解释器的相关操作。
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
sys.modules.keys() 返回所有已经导入的模块名
sys.modules.values() 返回所有已经导入的模块
sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) 退出程序,正常退出时exit(0)
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version 获取Python解释程序的
sys.api_version 解释器的C的API版本
sys.version_info
‘final’表示最终,也有’candidate’表示候选,serial表示版本级别,是否有后继的发行
sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout,并且将他保存进__builtin__._.指在python的交互式解释器里,’_’ 代表上次你输入得到的结果,hook是钩子的意思,将上次的结果钩过来
sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式
sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字
sys.setdefaultencoding(name)用来设置当前默认的字符编码,如果name和任何一个可用的编码都不匹配,抛出 LookupError,这个函数只会被site模块的sitecustomize使用,一旦别site模块使用了,他会从sys模块移除
sys.builtin_module_names Python解释器导入的模块列表
sys.executable Python解释程序路径
sys.getwindowsversion() 获取Windows的版本
sys.copyright 记录python版权相关的东西
sys.byteorder 本地字节规则的指示器,big-endian平台的值是’big’,little-endian平台的值是’little’
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix 返回平台独立的python文件安装的位置
sys.stderr 错误输出
sys.stdin 标准输入
sys.stdout 标准输出
sys.platform 返回操作系统平台名称
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.maxunicode 最大的Unicode值
sys.maxint 最大的Int值
sys.version 获取Python解释程序的版本信息
sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0
例
进度条(注意:在pycharm中执行无效,请到命令行中以脚本的方式执行)
import sys,time for i in range(50):
sys.stdout.write('%s\r' %('#'*i))
sys.stdout.flush()
time.sleep(0.1)
五、shutil
高级的文件、文件夹、压缩包处理模块
- shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
- shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
- shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
- shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
- shutil.copy(src, dst)
拷贝文件和权限
import shutil
shutil.copy('f1.log', 'f2.log')
- shutil.copy2(src, dst)
拷贝文件和状态信息
import shutil
shutil.copy2('f1.log', 'f2.log')
- shutil.ignore_patterns(*patterns)
- shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
- shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
import shutil
shutil.rmtree('folder1')
- shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
import shutil
shutil.move('folder1', 'folder3')
- shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar” root_dir: 要压缩的文件夹路径(默认当前目录) owner: 用户,默认当前用户 group: 组,默认当前组 logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') #将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
- shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
- zipfile压缩解压缩
import zipfile # 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close() # 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
- tarfile压缩解压缩
import tarfile # 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close() # 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()
六、json&pickle
1.序列化定义
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
2.序列化的好处
- 持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
- 跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
3.json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。
json模块主要用于处理json格式的数据,可以将json格式的数据转化为python的字典,便于python处理,同时也可以将python的字典或列表等对象转化为json格式的数据,便于跨平台或跨语言进行数据交互。
Python 编码为 JSON 类型转换对应表:

- JSON 解码为 Python 类型转换对应表:

- Json模块提供了四个功能:dumps、dump、loads、load
- dumps 和 loads 用于python对象和字符串间的序列化和反序列化
dumps:将python 基本数据类型转化为json格式数据类型
loads:将json格式数据类型转化为python数据类型
import json
s1 = '{"key1":"value1"}' #字符串只能是这个格式的,才能被json转换 通过loads进行反序列化时,必须使用双引号
d1 = {'key2':'value2'}
s2 = json.loads(s1) #使用loads反序列化
print('s1的内容:',s1)
print("s1的类型:",type(s1))
print('s2的内容:',s2)
print("s2的类型:",type(s2))
d2 = json.dumps(d1)
print('d1的内容:',d1)
print("d1的类型:",type(d1))
print('d2的内容:',d2)
print("d2的类型",type(d2))
输出
s1的内容: {"key1":"value1"}
s1的类型: <class 'str'>
s2的内容: {'key1': 'value1'}
s2的类型: <class 'dict'> #经loads处理之后,str变味dict
d1的内容: {'key2': 'value2'}
d1的类型: <class 'dict'>
d2的内容: {"key2": "value2"}
d2的类型 <class 'str'> #经dumps处理之后,dict变为str
- dump 和load 用于对文件进行序列化和反序列化
dump:主要用于json文件的读写,json.dump(x,f),x是对象,f是一个文件对象,这个方法可以将json字符串写入到文本文件中
load:加载json文件
import json
s1 = '{"key1":"value1"}' #字符串只能是这个格式的,才能被json转换 通过loads进行反序列化时,必须使用双引号
d1 = {'key2':'value2'}
json.dump(d1,open('序列化.txt','w')) #将s1序列化,并写入文件
e1 = json.load(open('序列化.txt','r')) #读取json文件
print("e1的类型:",type(e1))
print('e1的内容:',e1)
输出
e1的类型: <class 'dict'>
e1的内容: {'key2': 'value2'}
注意:
json 不认单引号;
无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads;
4.pickle
pickle模块实现了基本的数据序列和反序列化,和json的功能类似。
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储,也可以简单的将字符进行序列化
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象,也可以将字符进行反序列化。
和json不同的是:json 更适合跨语言 可以处理字符串,基本数据类型;pickle python专有,更适合处理复杂类型的序列化
- pikle模块提供 dumps loads dump load四个基本功能
- dumps 和loads 用于python对象和字符串间的序列化和反序列化
dumps 和json.dumps功能一样,但是以字节对象形式返回封装的对象
loads和json.loads功能一样,从字节对象中读取被封装的对象,并返回
import pickle
s1 = '{"key1":"value1"}' #字符串只能是这个格式的,才能被转换 通过loads进行反序列化时,必须使用双引号
d1 = {'key2':'value2'}
s3 = pickle.dumps(s1)
print('s1的内容:',s1)
print("s1的类型:",type(s1))
print('s3的内容:',s3)
print("s3的类型:",type(s3))
d3 = pickle.loads(s3)
print('d1的内容:',d1)
print("d1的类型:",type(d1))
print('d3的内容:',d3)
print("d3的类型",type(d3))
输出
s1的内容: {"key1":"value1"}
s1的类型: <class 'str'>
s3的内容: b'\x80\x03X\x11\x00\x00\x00{"key1":"value1"}q\x00.'
s3的类型: <class 'bytes'> #dumps处理之后返回的是字节类型
d1的内容: {'key2': 'value2'}
d1的类型: <class 'dict'>
d3的内容: {"key1":"value1"}
d3的类型 <class 'str'>
- dump 和load 用于对文件进行序列化和反序列化.python数据持久化用的比较多
pickle.dump(obj, file, [,protocol])
注解:将对象obj保存到文件file中去。
protocol为序列化使用的协议版本,0:ASCII协议,所序列化的对象使用可打印的ASCII码表示;
1:老式的二进制协议;
2:2.3版本引入的新二进制协议,较以前的更高效。其中协议0和1兼容老版本的python。protocol默认值为0。
file:对象保存到的类文件对象。file必须有write()接口, file可以是一个以'w'方式打开的文件或者一个StringIO对象或者其他任何实现write()接口的对象。如果protocol>=1,文件对象需要是二进制模式打开的。
pickle.load(file)
注解:从file中读取一个字符串,并将它重构为原来的python对象。 file:类文件对象,有read()和readline()接口
import pickle
s1 = '{"key1":"value1"}' #字符串只能是这个格式的,才能被json转换 通过loads进行反序列化时,必须使用双引号
d1 = {'key2':'value2'}
pickle.dump(s1,open('序列化.txt','wb')) #注意需使用二进制方式写入文件
e2 = pickle.load(open('序列化.txt','rb')) #需使用二进制方式读取文件
print("e2的类型:",type(e2))
print('e2的内容:',e2)
输出
e2的类型: <class 'str'>
e2的内容: {"key1":"value1"}
七、shelve
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
八、xml
xml是实现不同语言或程序之间进行数据交换的协议,可扩展标记语言,标准通用标记语言的子集。是一种用于标记电子文件使其具有结构性的标记语言。
xml格式如下,是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data> xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
print(root.iter('year')) #全文搜索
print(root.find('country')) #在root的子节点找,只找一个
print(root.findall('country')) #在root的子节点找,找所有
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print('========>',child.tag,child.attrib,child.attrib['name'])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')
node.set('version','1.0')
tree.write('test.xml')
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')
创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = ''
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = ''
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
九、configparser
configparser用于配置文件解析,可以解析特定格式的配置文件,多数此类配置文件名格式为XXX.ini,例如mysql的配置文件。
配置文件如下:
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31 [section2]
k1 = v1
读取:
import configparser config=configparser.ConfigParser()
config.read('a.cfg') #查看所有的标题
res=config.sections() #['section1', 'section2']
print(res) #查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary'] #查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')] #查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon #查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) # #查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True #查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0
修改
import configparser config=configparser.ConfigParser()
config.read('a.cfg') #删除整个标题section2
config.remove_section('section2') #删除标题section1下的某个k1和k2
config.remove_option('section1','k1')
config.remove_option('section1','k2') #判断是否存在某个标题
print(config.has_section('section1')) #判断标题section1下是否有user
print(config.has_option('section1','')) #添加一个标题
config.add_section('egon') #在标题egon下添加name=egon,age=18的配置
config.set('egon','name','egon')
config.set('egon','age',18) #报错,必须是字符串 #最后将修改的内容写入文件,完成最终的修改
config.write(open('a.cfg','w'))
十、hashlib
用于加密相关的操作,代替了md5模块和sha模块,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法。
在python3中已经废弃了md5和sha模块。
摘要算法又称为哈希算法,散列算法。它通过一个函数,把任意长度的数据转换为一个长度固顶的数据串(通常用16进制的字符串表示)用于加密相关的操作。
MD5 算法 三个特点:
1.内容相同则hash运算结果相同,内容稍微改变则hash值则变;
2.不可逆推;
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
md5加密
import hashlib
hash = hashlib.md5()
hash.update('admin'.encode('utf-8'))
print(hash.hexdigest())
输出
21232f297a57a5a743894a0e4a801fc3
sha256加密
import hashlib
hash = hashlib.sha256()
hash.update('admin'.encode('utf-8'))
print(hash.hexdigest())
输出
8c6976e5b5410415bde908bd4dee15dfb167a9c873fc4bb8a81f6f2ab448a918
以上加密算法虽然很厉害,但仍然存在缺陷,通过撞库可以反解。所以必要对加密算法中添加自定义key再来做加密。
‘加盐’加密
import hashlib
hash = hashlib.md5('exin'.encode('utf-8')) #加盐
hash.update('admin'.encode('utf-8'))
print(hash.hexdigest())
输出
39bbf89fa70b780d40d7125ff3c6f434
hmac加密
hmac内部对我们创建的key和内容进行处理后在加密
import hmac
h = hmac.new('python'.encode('utf-8'))
h.update('helloworld'.encode('utf-8'))
print(h.hexdigest())
输出
b3b867248bb4cace835b59562c39fd55
十一、suprocess
subprocess最早在2.4版本引入。用来生成子进程,并可以通过管道连接他们的输入/输出/错误,以及获得他们的返回值。
subprocess提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。
import subprocess '''
sh-3.2# ls /Users/egon/Desktop |grep txt$
mysql.txt
tt.txt
事物.txt
''' res1=subprocess.Popen('ls /Users/jieli/Desktop',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('grep txt$',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE) print(res.stdout.read().decode('utf-8')) #等同于上面,但是上面的优势在于,一个数据流可以和另外一个数据流交互,可以通过爬虫得到结果然后交给grep
res1=subprocess.Popen('ls /Users/jieli/Desktop |grep txt$',shell=True,stdout=subprocess.PIPE)
print(res1.stdout.read().decode('utf-8')) #windows下:
# dir | findstr 'test*'
# dir | findstr 'txt$'
import subprocess
res1=subprocess.Popen(r'dir C:\Users\Administrator\PycharmProjects\test\函数备课',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('findstr test*',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE) print(res.stdout.read().decode('gbk')) #subprocess使用当前系统默认编码,得到结果为bytes类型,在windows下需要用gbk解码
十二、logging
用于便捷记录日志且线程安全的模块
logging.basicConfig(filename='access.log',
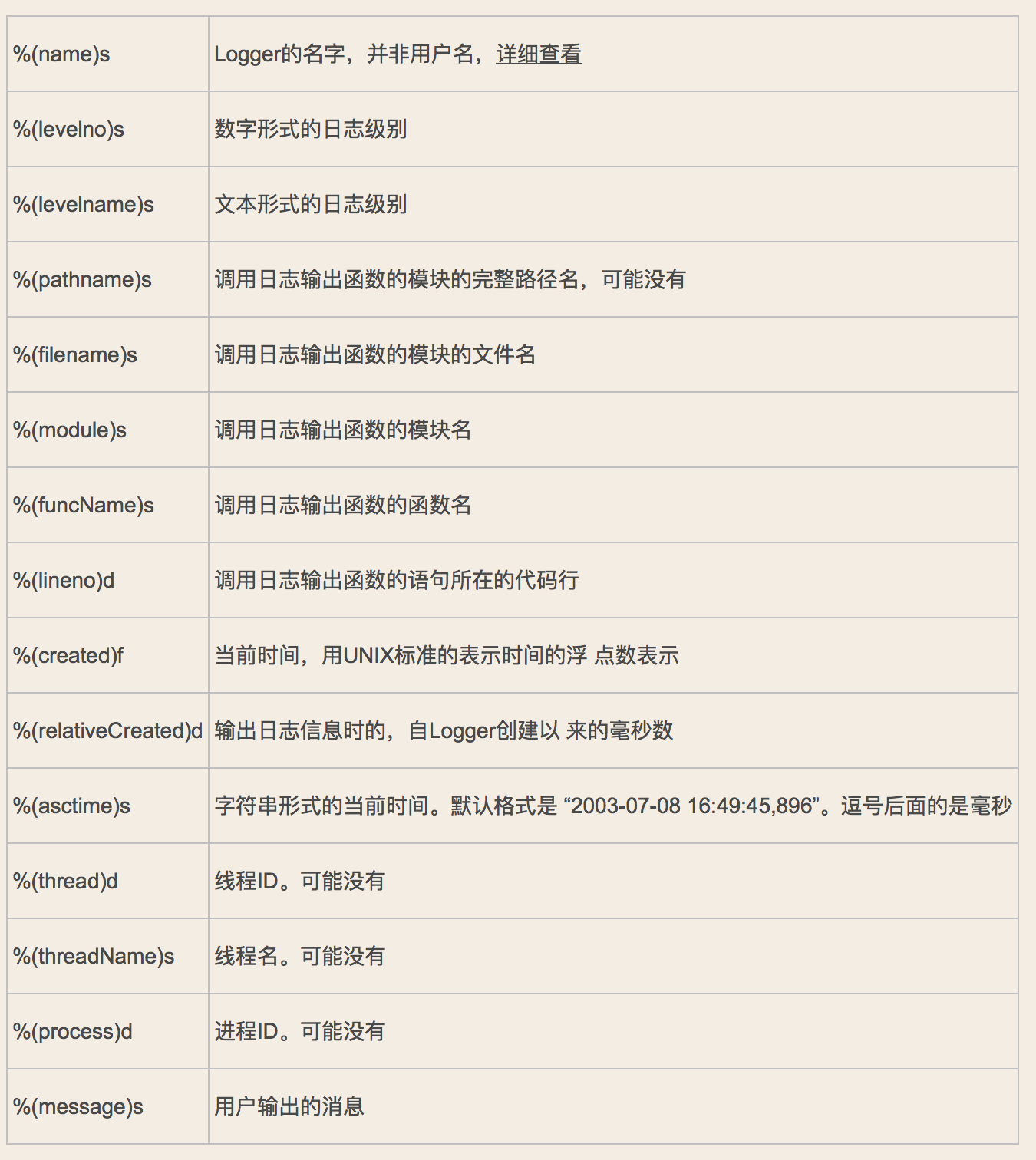
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10) logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.error('error')
logging.critical('critical')
logging.log(10,'log') #如果level=40,则只有logging.critical和loggin.error的日志会被打印
一:如果不指定filename,则默认打印到终端
二:指定日志级别:
指定方式:
1:level=10
2:level=logging.ERROR 日志级别种类:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 三:指定日志级别为ERROR,则只有ERROR及其以上级别的日志会被打印

- logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,
可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
- 日志格式
【Python3之常用模块】的更多相关文章
- 09 . Python3之常用模块
模块的定义与分类 模块是什么? 一个函数封装一个功能,你使用的软件可能就是由n多个函数组成的(先备考虑面向对象).比如抖音这个软件,不可能将所有程序都写入一个文件,所以咱们应该将文件划分,这样其组织结 ...
- [Python3] 032 常用模块 random
目录 random 1. random.random() 2. random.choice() 3. random.shuffle() 4. random.randint() 5. random.ra ...
- [Python3] 031 常用模块 shutil & zipfile
目录 shutil 1. shutil.copy() 2. shutil.copy2() 3. shutil.copyfile() 4. shutil.move() 5. 归档 5.1 shutil. ...
- [Python3] 030 常用模块 os
目录 os 1. os.getcwd() 2. os.chdir() 3. os.listdir() 4. os.makedir() 5. os.system() 6. os.getenv() 7. ...
- [Python3] 028 常用模块 datetime
目录 datetime 1. datetime.date 2. datetime.time 3. datetime.datetime 4. datetime.timedelta 补充 datetime ...
- [Python3] 029 常用模块 timeit
目录 timeit 直接举例 1. 测量生成列表的时间 2. 测量函数运行时间(一) 3. 测量函数运行时间(二) timeit 直接举例 必要的导入 import timeit 1. 测量生成列表的 ...
- [Python3] 027 常用模块 time
目录 time 1. 时间戳 2. UTC 时间 3. 夏令时 4. 时间元组 5. 举例 5.1 例子1 例子2 例子3 例子4 例子5 例子6 例子7 time 1. 时间戳 一个时间表示,根据不 ...
- [Python3] 026 常用模块 calendar
目录 calendar 1. calendar.calendar(year, w, l, c, m) 2. calendar.prcal(year, w, l, c, m) 3. calendar.m ...
- python3 常用模块详解
这里是python3的一些常用模块的用法详解,大家可以在这里找到它们. Python3 循环语句 python中模块sys与os的一些常用方法 Python3字符串 详解 Python3之时间模块详述 ...
随机推荐
- 基于Maven的SSM整合的web工程
此文章主要有以下几个知识点: 一.如何创建 Maven的Web 工程 二.整合SSM(Spring,SpringMvc,Mybatis),包括所有的配置文件 三.用 mybatis 逆向工程生成对应的 ...
- 数据可视化之MarkPoint
MarkPoint是什么效果?如上图,一闪一闪亮晶晶的效果,这是在Echarts中对应的效果.我最早看到的是腾讯的一个Flash的版本,显示当前QQ在线人数的全国分布效果,感觉效果很炫,当时也在想,怎 ...
- 【渗透测试】PHPCMS9.6.0 任意文件上传漏洞+修复方案
这个漏洞是某司的一位前辈发出来的,这里只是复现一下而已. 原文地址:https://www.t00ls.net/thread-39226-1-1.html 首先我们本地搭建一个phpcms9.6.0的 ...
- bzoj4810 [Ynoi2017]由乃的玉米田
Description 由乃在自己的农田边散步,她突然发现田里的一排玉米非常的不美.这排玉米一共有N株,它们的高度参差不齐. 由乃认为玉米田不美,所以她决定出个数据结构题 这个题是这样的: 给你一 ...
- 关于li标签之间的间隔如何消除!
问题:li标签用了display:inline之后虽然成功的合并在一行,但是li标签之间出现了间距. 原因:按enter键换行之后li标签之间存在着空格,正是这些空格占据了li标签之间的空间. 解决方 ...
- 2017TSC世界大脑与科技峰会,多角度深入探讨关于大脑意识
TSC·世界大脑与科技峰会是全世界范围内的集会,多角度深入探讨关于大脑意识体验来源这一根本话题,我们是谁,现实的本质是什么,我们所处宇宙空间的本质为何.该峰会由亚利桑那大学意识研究中心主办. 会议时间 ...
- 《快学Scala》——数组、映射和元组
数组 定长数组:在Scala中可以用Array,初始化一个定长数组.例如: val nums = new Array[Int](10) //10个整数的数组,所有元素初始化为0 val a = new ...
- hdu1068 Girls and Boys 二分匹配
题目链接: 二分匹配的应用 求最大独立集 最大独立集等于=顶点数-匹配数 本体中由于男孩和女孩的学号是不分开的,所以匹配数应是求得的匹配数/2 代码: #include<iostream> ...
- 浅谈 Java Xml 底层解析方式
XML 使用DTD(document type definition)文档类型来标记数据和定义数据,格式统一且跨平台和语言,已成为业界公认的标准. 目前 XML 描述数据龙头老大的地位渐渐受到 Jso ...
- Java 程序员快速上手 Kotlin 11 招
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:霍丙乾 近经常会收到一些 "用 Kotlin 怎么写" 的问题,作为有经验的程序员, ...