到底为什么不建议使用SELECT *?
“不要使用SELECT *”几乎已经成为了MySQL使用的一条金科玉律,就连《阿里Java开发手册》也明确表示不得使用*作为查询的字段列表,更是让这条规则拥有了权威的加持。

不过我在开发过程中直接使用SELECT *还是比较多的,原因有两个:
- 因为简单,开发效率非常高,而且如果后期频繁添加或修改字段,SQL语句也不需要改变;
- 我认为过早优化是个不好的习惯,除非在一开始就能确定你最终实际需要的字段是什么,并为之建立恰当的索引;否则,我选择遇到麻烦的时候再对SQL进行优化,当然前提是这个麻烦并不致命。
但是我们总得知道为什么不建议直接使用SELECT *,本文从4个方面给出理由。
1. 不必要的磁盘I/O
我们知道 MySQL 本质上是将用户记录存储在磁盘上,因此查询操作就是一种进行磁盘IO的行为(前提是要查询的记录没有缓存在内存中)。
查询的字段越多,说明要读取的内容也就越多,因此会增大磁盘 IO 开销。尤其是当某些字段是 TEXT、MEDIUMTEXT或者BLOB 等类型的时候,效果尤为明显。
那使用SELECT *会不会使MySQL占用更多的内存呢?
理论上不会,因为对于Server层而言,并非是在内存中存储完整的结果集之后一下子传给客户端,而是每从存储引擎获取到一行,就写到一个叫做net_buffer的内存空间中,这个内存的大小由系统变量net_buffer_length来控制,默认是16KB;当net_buffer写满之后再往本地网络栈的内存空间socket send buffer中写数据发送给客户端,发送成功(客户端读取完成)后清空net_buffer,然后继续读取下一行并写入。
也就是说,默认情况下,结果集占用的内存空间最大不过是net_buffer_length大小罢了,不会因为多几个字段就占用额外的内存空间。
2. 加重网络时延
承接上一点,虽然每次都是把socket send buffer中的数据发送给客户端,单次看来数据量不大,可架不住真的有人用*把TEXT、MEDIUMTEXT或者BLOB 类型的字段也查出来了,总数据量大了,这就直接导致网络传输的次数变多了。
如果MySQL和应用程序不在同一台机器,这种开销非常明显。即使MySQL服务器和客户端是在同一台机器上,使用的协议还是TCP,通信也是需要额外的时间。
3. 无法使用覆盖索引
为了说明这个问题,我们需要建一个表
CREATE TABLE `user_innodb` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`gender` tinyint(1) DEFAULT NULL,
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我们创建了一个存储引擎为InnoDB的表user_innodb,并设置id为主键,另外为name和phone创建了联合索引,最后向表中随机初始化了500W+条数据。
InnoDB会自动为主键id创建一棵名为主键索引(又叫做聚簇索引)的B+树,这个B+树的最重要的特点就是叶子节点包含了完整的用户记录,大概长这个样子。
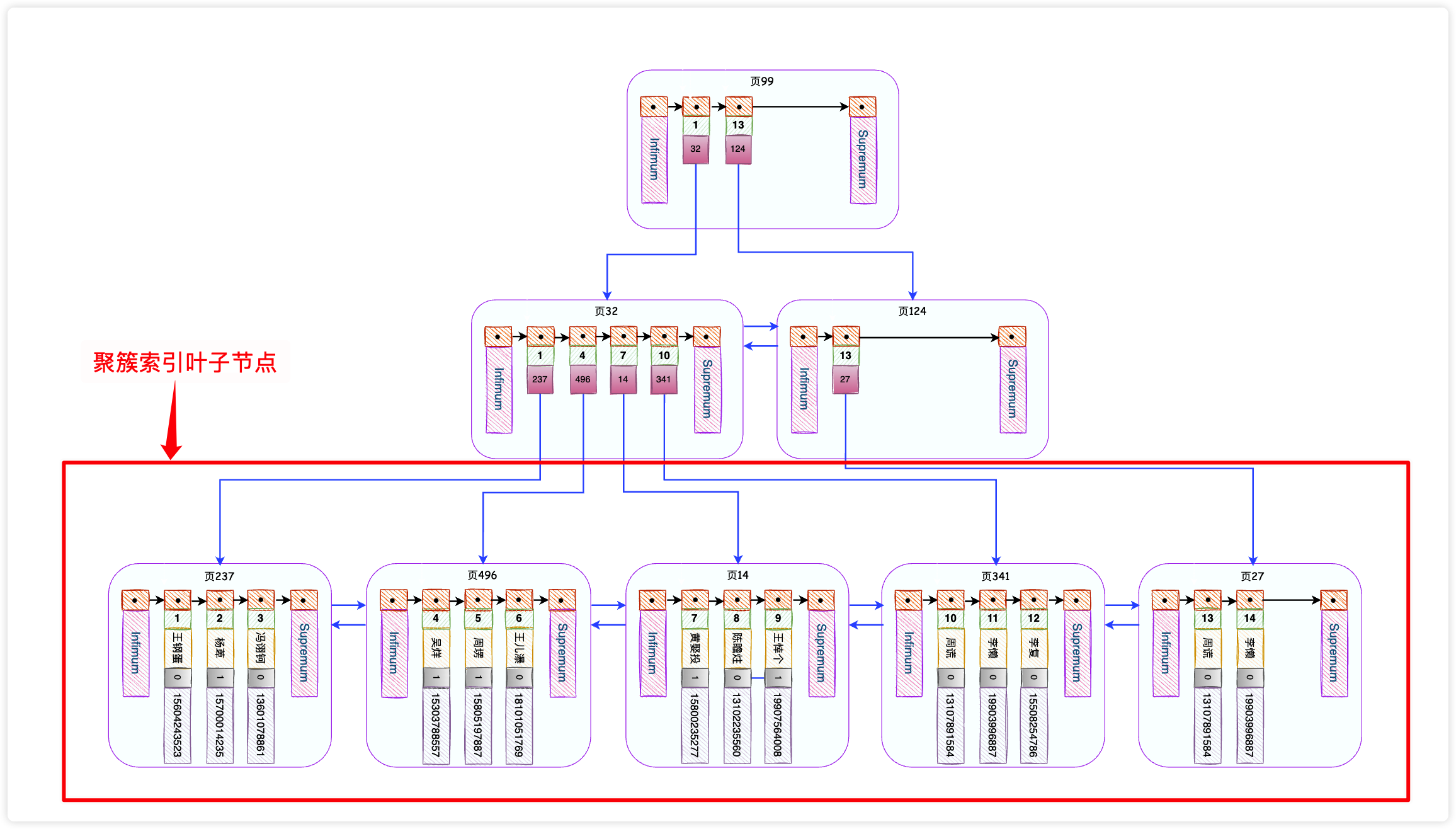
如果我们执行这个语句
SELECT * FROM user_innodb WHERE name = '蝉沐风';
使用EXPLAIN查看一下语句的执行计划:

发现这个SQL语句会使用到IDX_NAME_PHONE索引,这是一个二级索引。二级索引的叶子节点长这个样子:
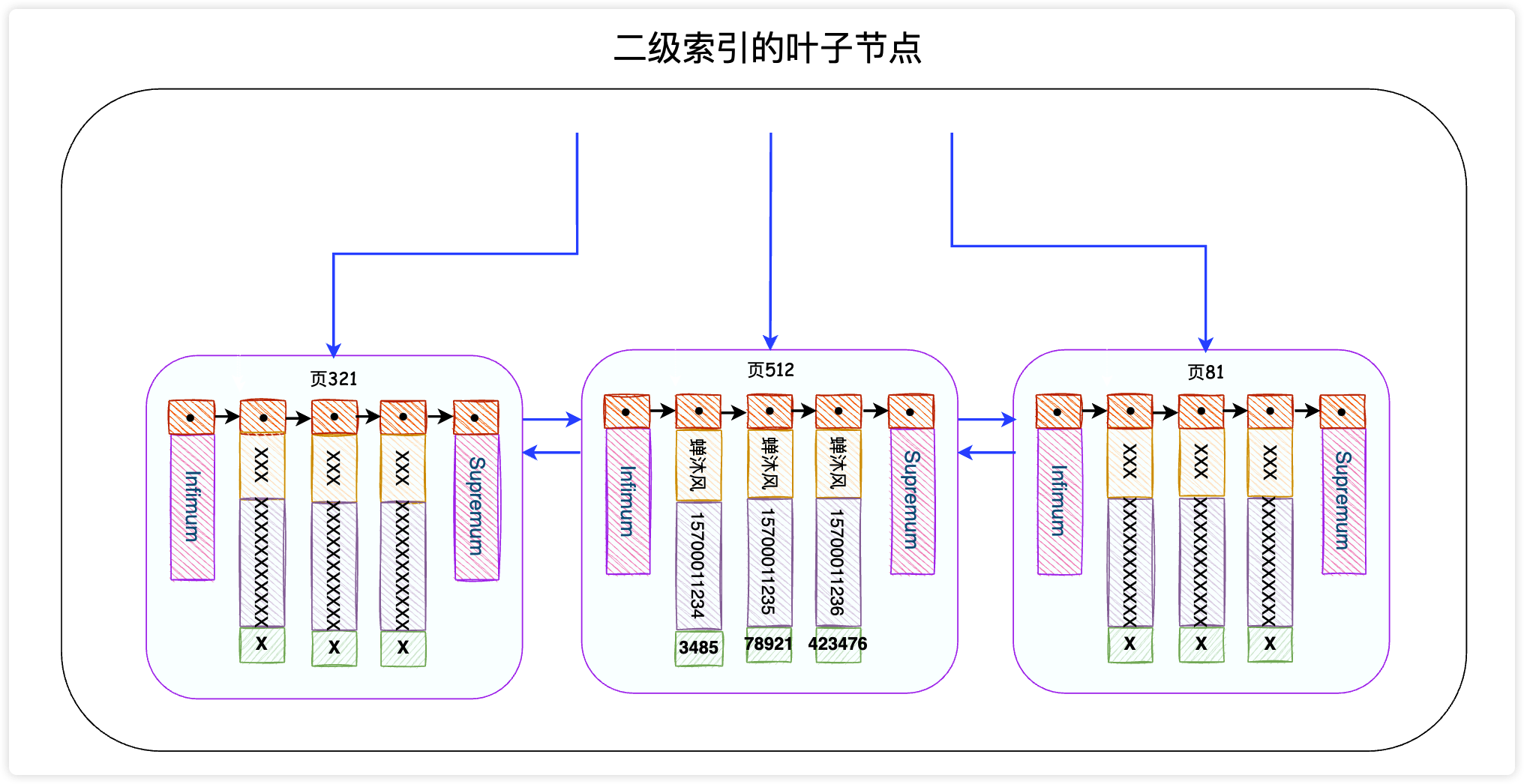
InnoDB存储引擎会根据搜索条件在该二级索引的叶子节点中找到name为蝉沐风的记录,但是二级索引中只记录了name、phone和主键id字段(谁让我们用的是SELECT *呢),因此InnoDB需要拿着主键id去主键索引中查找这一条完整的记录,这个过程叫做回表。
想一下,如果二级索引的叶子节点上有我们想要的所有数据,是不是就不需要回表了呢?是的,这就是覆盖索引。
举个例子,我们恰好只想搜索name、phone以及主键字段。
SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` (
`id` int NOT NULL,
`m` int DEFAULT NULL,
`n` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT;
CREATE TABLE `t2` (
`id` int NOT NULL,
`m` int DEFAULT NULL,
`n` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。由于已经强制确定了驱动表和被驱动表,下面我们说一下两表连接的本质:
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;- 对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}
这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
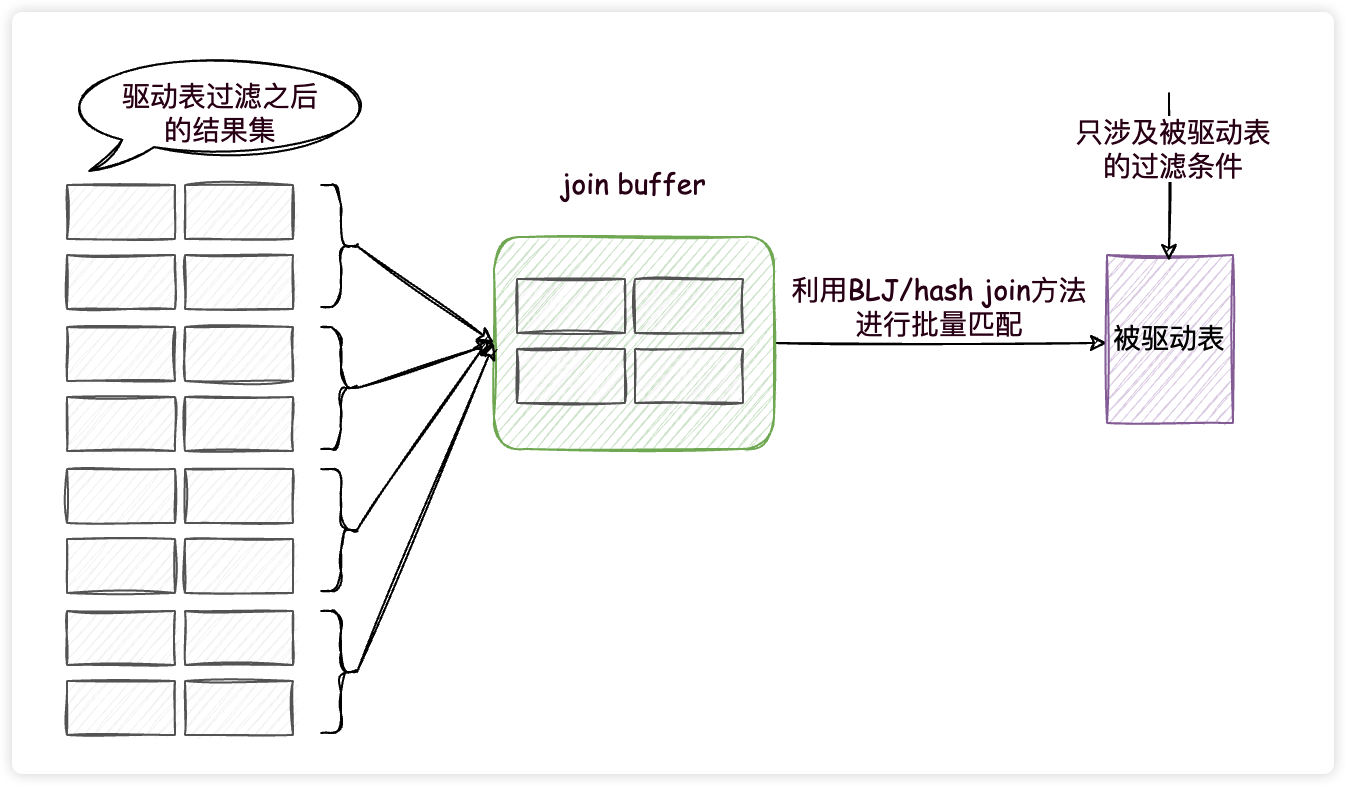
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数。
推荐阅读
到底为什么不建议使用SELECT *?的更多相关文章
- 从原理上理解MySQL的优化建议
从原理上理解MySQL的优化建议 预备知识 B+树索引 mysql的默认存储引擎InnoDB使用B+树来存储数据的,所以在分析优化建议之前,了解一下B+树索引的基本原理. 上图是一个B+树索引示意图, ...
- Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议
Mysql查询优化汇总 order by优化例子,group by优化例子,limit优化例子,优化建议 索引 索引是一种存储引擎快速查询记录的一种数据结构. 注意 MYSQL一次查询只能使用一个索引 ...
- 最全的ORACLE-SQL笔记
-- 首先,以超级管理员的身份登录oracle sqlplus sys/bjsxt as sysdba --然后,解除对scott用户的锁 alter user scott account unloc ...
- mysql优化----explain的列分析
sql语句优化: : sql语句的时间花在哪儿? 答: 等待时间 , 执行时间. 等待时间:看是不是被锁住了,那就不是语句层面了是服务端层面了,看连接数内存. 执行时间:到底取出多少行,一次性取出1万 ...
- WHERE、ORDER BY、GROUP BY、HAVING语句解析(二十八)
之前啊,我们提及到,对于update和delete,若不带where条件,则对所有记录都有效. 一.WHERE条件表达式 (1)对记录进行过滤,如果没有指定WHERE子句,则显示所有记录. (2)在W ...
- mysql设计与优化以及数据库表设计与表开发规范
一.设计问题? 1.主键是用自增还是UUID ? Innodb 中的主键是聚簇索引. 如果主键是自增的,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的 ...
- 不要再问我 in,exists 走不走索引了
微信搜『烟雨星空』,获取最新好文. 前言 最近,有一个业务需求,给我一份数据 A ,把它在数据库 B 中存在,而又比 A 多出的部分算出来.由于数据比较杂乱,我这里简化模型. 然后就会发现,我去,这不 ...
- 【转】使用SQL Tuning Advisor STA优化SQL
SQL优化器(SQL Tuning Advisor STA)是Oracle10g中推出的帮助DBA优化工具,它的特点是简单.智能,DBA值需要调用函数就可以给出一个性能很差的语句的优化结果.下面介绍一 ...
- 从AdventureWorks学习数据库建模——实体分析
最近打算写写数据库建模的文章,所以打算分析微软官方提供的SQL Server示例数据库AdventureWorks,看看这个数据库中有哪些值得学习的地方. 首先我们需要下载安装一个SQL Server ...
随机推荐
- Hive之同比环比的计算
Hive系列文章 Hive表的基本操作 Hive中的集合数据类型 Hive动态分区详解 hive中orc格式表的数据导入 Java通过jdbc连接hive 通过HiveServer2访问Hive Sp ...
- Spring AOP基础概念及自定义注解式AOP初体验
对AOP的理解开始是抽象的,看到切点的匹配方式其实与正则表达式性质大致一样就基本了解AOP是基本是个什么作用了.只是整个概念更抽象,需要具化理解.下图列表是AOP相关概念解释,可能也比较抽象^_^ 比 ...
- archery关闭导出功能
https://github.com/hhyo/Archery/issues/1367 进入docker容器,找到sqlquery.html.修改showExport相关配置为以下内容. {% if ...
- Python培训:绘制饼图或圆环图
使用pyplot的pie()函数可以快速地绘制饼图或圆环图,pie()函数的语法格式如下所示: 该函数常用参数的含义如下. ·x:表示扇形或楔形的数据. ·explode:表示扇形或楔形离开圆心的距离 ...
- m0n0wall安装教程
m0n0wall的镜像链接:https://pan.baidu.com/s/1soIw7cS1Tv180fbo2655UA 提取码:dpon 一.新建虚拟机 新建虚拟机我想大家都会,详细步骤我就不陈述 ...
- PON/产线测试解决方案
第一章 方案背景与概述1.1 方案背景随着网络的高速发展与网络速率的不断提升,用户对网络产品的可靠性要求也越来 越高.网络产品的故障符合"浴盆曲线"规律,生产过程中的严格测试能够及 ...
- Excel数据可视化图表设计需要注意的几个问题
大数据发展迅速的时代,数据分析驱动商业决策.对于庞大.无序.复杂的数据要是没经过合适的处理,价值就无法体现. 可以想象一本没有图片的教科书.没有图表.图形或是带有箭头和标签的插图或流程图,那么这门学 ...
- C# 成员访问修饰符protected internal等
1.C#4个修饰符的权限修饰符 级别 适用成员 解释public 公开 类及类成员的修饰符 对访问成员没有级别限制private 私有 类成员的修饰符 只能在类的内部访问protected 受保护 ...
- Java课程设计---代码及数据库
点击下载: 代码:StudentSystem 数据库名:db_student 数据表:tb_student tb_class admin
- JZ-046-圆圈中最后剩下的数
圆圈中最后剩下的数 题目描述 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏. 其中,有个游戏是这样的:首先,让小朋友们围成一 ...