迁移学习(TSRP)《Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation》
论文信息
论文标题:Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation
论文作者:Jie Wang, Xiaoli Zhang
论文来源:
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
问题:
- 首先,伪标签主要是通过源域和目标域之间的良好对齐获得的,而伪标签的准确性对性能的影响没有深入研究。通常在源域上训练分类器生成伪标签时,在每次优化迭代中都可能出现一些错误的伪标签,如 Figure1 所示。由于错误的累积,不正确的伪标签会极大地影响最终的性能;
- 其次,大多数方法主要集中在挖掘源域以提高目标域伪标签的准确性,目标域样本之间的内在关系似乎还没有被探索;
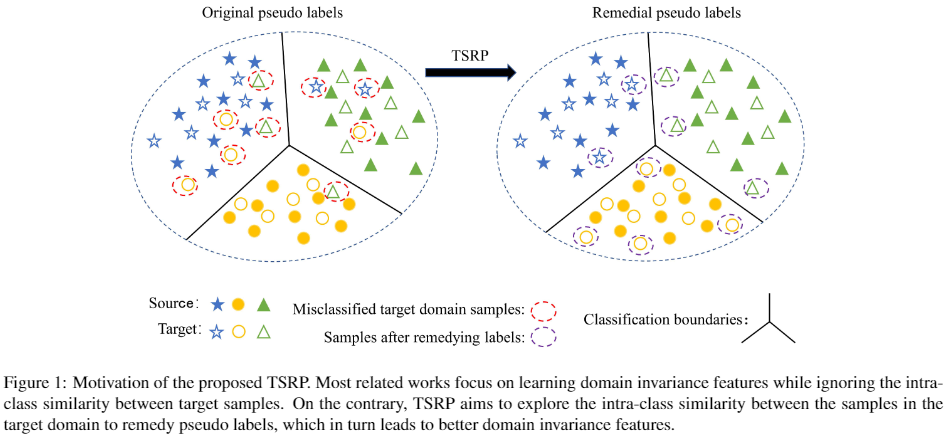
为了解决上述两个问题,在本文中,提出挖掘目标域类内相似性来修复目标域中的伪标签(TSRP),以提高伪标签的准确性。 TSRP 的核心思想是使用目标相似性通过生成树 [22] 来选择具有高置信度的伪标签(UTSP)。 然后,使用选择的高置信度伪标记样本和源数据来训练强分类器。 强分类器用于纠正部分错误标记的具有低置信度伪标签的目标样本。 我们称之为伪标签的补救过程。 通常,我们的方法可以集成到任何通过使用在源域上训练的分类器生成目标域的伪标签的方法。
2 相关工作
在 [37] 中,Saito 等人。 使用三个非对称分类器来提高伪标签的准确性,其中两个分类器用于选择置信伪标签,第三个旨在学习目标域的判别数据表示。 [18]通过结构化预测探索目标域的结构信息,并结合最近的类原型和结构化预测来提升伪标签的准确性。 [38]将目标域中同一簇的样本视为一个整体而不是个体。 它通过类质心匹配为目标集群分配伪标签。 [39]提出了一种从易到难的策略,将目标样本分为三类,即简单样本、困难样本和不正确的简单样本。 它倾向于为简单的样本生成伪标签,并尽量避免困难的样本。 从易到难的策略可能偏向于简单的类。 为了解决这个问题,[40] 中提出了一种置信度感知的伪标签选择策略。 它根据伪标签的概率独立地从每个类中选择样本。 在 [39, 40] 中,他们使用目标样本到源样本中心的距离作为选择标准来选择高度置信度的伪标签。 在 [18, 38] 中,他们迭代地生成可信的伪标签。 但是,他们没有考虑如何纠正错误生成的伪标签。 与上述方法不同,在本文中,我们建议通过探索目标域中的类内相似性来纠正错误生成的伪标签。
3 方法
整体框架:

整体算法:

UTSP 如下:

UTSP 图解如下:
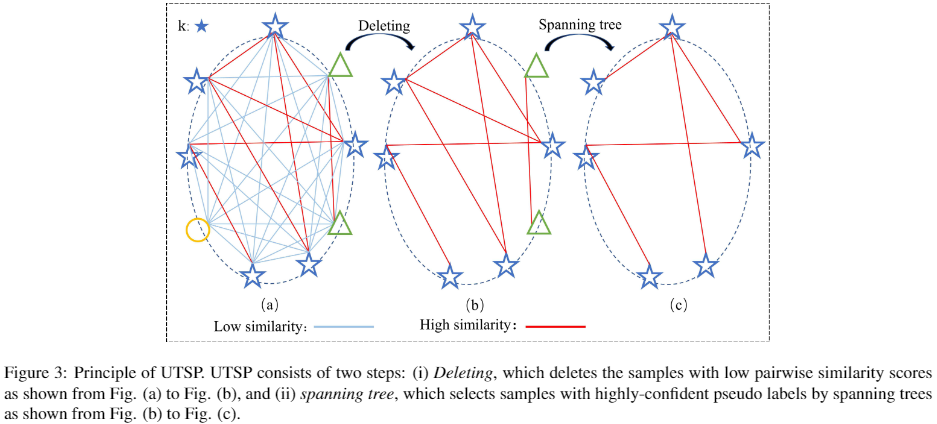
公式:
$\hat{\mathbf{y}}_{l, \text { remedy }}^{T}=f_{\text {strong }}\left(\mathbf{Z}_{l}^{T}\right) \quad\quad\quad(1)$
$S_{i, j}^{k}=\left\{\begin{array}{ll}0, & i=j \\\frac{\left\langle\mathbf{z}_{i}^{T k}, \mathbf{z}_{j}^{T k}\right\rangle}{\left\|\mathbf{z}_{i}^{T i}\right\|\left\|\mathbf{z}_{j}^{T k k}\right\|}, & \text { otherwise }\end{array}, \forall k=1,2, \ldots, C_{y}\right. \quad\quad\quad(2)$
$S_{\text {rank }}^{k}=\left\{S_{\operatorname{rank}(1)}^{k}, S_{\operatorname{rank}(2)}^{k}, \ldots, S_{\operatorname{rank}\left(n_{p}\right)}^{k}\right\} \quad\quad\quad(3)$
$\delta=S_{\left.\operatorname{rank}\left(\mid \rho n_{p}\right\rfloor\right)}^{k} \quad\quad\quad(4)$
$M_{i j}^{k}=\left\{\begin{array}{ll}1, & S_{i, j}^{k} \geq \delta \\0, & \text { otherwise }\end{array}\right. \quad\quad\quad(5)$
$D_{i i}^{k}=\sum\limits _{j} M_{i j}^{k} \quad\quad\quad(6)$
$m=\arg \underset{i}{\text{max}} D_{i i}^{k} \quad\quad\quad(7)$
Note:为防止类不平衡问题,将某类 $i$ 样本数少于 $3$ 的全部视为高置信度样本;
4 实验
Performance

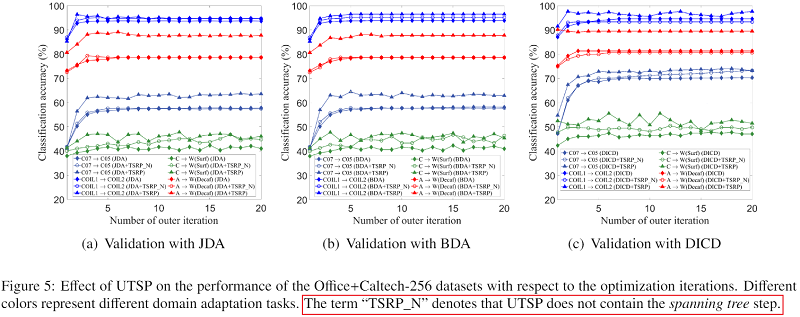
消融实验
5 总结
论文:
标签生成策略:硬标签[19、35、17] 和 软标签[36]
伪标签产生负面影响:[18]
迁移学习(TSRP)《Improving Pseudo Labels With Intra-Class Similarity for Unsupervised Domain Adaptation》的更多相关文章
- 迁移学习(IIMT)——《Improve Unsupervised Domain Adaptation with Mixup Training》
论文信息 论文标题:Improve Unsupervised Domain Adaptation with Mixup Training论文作者:Shen Yan, Huan Song, Nanxia ...
- 中文NER的那些事儿2. 多任务,对抗迁移学习详解&代码实现
第一章我们简单了解了NER任务和基线模型Bert-Bilstm-CRF基线模型详解&代码实现,这一章按解决问题的方法来划分,我们聊聊多任务学习,和对抗迁移学习是如何优化实体识别中边界模糊,垂直 ...
- 【深度学习系列】迁移学习Transfer Learning
在前面的文章中,我们通常是拿到一个任务,譬如图像分类.识别等,搜集好数据后就开始直接用模型进行训练,但是现实情况中,由于设备的局限性.时间的紧迫性等导致我们无法从头开始训练,迭代一两百万次来收敛模型, ...
- 迁移学习(DANN)《Domain-Adversarial Training of Neural Networks》
论文信息 论文标题:Domain-Adversarial Training of Neural Networks论文作者:Yaroslav Ganin, Evgeniya Ustinova, Hana ...
- 迁移学习(JDDA) 《Joint domain alignment and discriminative feature learning for unsupervised deep domain adaptation》
论文信息 论文标题:Joint domain alignment and discriminative feature learning for unsupervised deep domain ad ...
- Gluon炼丹(Kaggle 120种狗分类,迁移学习加双模型融合)
这是在kaggle上的一个练习比赛,使用的是ImageNet数据集的子集. 注意,mxnet版本要高于0.12.1b2017112. 下载数据集. train.zip test.zip labels ...
- TensorFlow迁移学习的识别花试验
最近学习了TensorFlow,发现一个模型叫vgg16,然后搭建环境跑了一下,觉得十分神奇,而且准确率十分的高.又上了一节选修课,关于人工智能,老师让做一个关于人工智能的试验,于是觉得vgg16很不 ...
- 第二十四节,TensorFlow下slim库函数的使用以及使用VGG网络进行预训练、迁移学习(附代码)
在介绍这一节之前,需要你对slim模型库有一些基本了解,具体可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用.数据集处理,这一节我们会详细介绍slim模型库下面的一些函数的使用 ...
- 图像识别 | AI在医学上的应用 | 深度学习 | 迁移学习
参考:登上<Cell>封面的AI医疗影像诊断系统:机器之心专访UCSD张康教授 Identifying Medical Diagnoses and Treatable Diseases b ...
- 『MXNet』第九弹_分类器以及迁移学习DEMO
解压文件命令: with zipfile.ZipFile('../data/kaggle_cifar10/' + fin, 'r') as zin: zin.extractall('../data/k ...
随机推荐
- 注释中的Unicode编码也会被转义
现象 public class Unicode { public static void main(String[] args) { // \u000d System.out.println(&quo ...
- 20200925--矩阵乘法(奥赛一本通P94 多维数组)
计算两个矩阵的乘法.n*m阶的矩阵A乘以m*k阶的矩阵B得到的矩阵C是n*k阶的,且C[i][j]=A[i][0]*B[0][j]+A[i][1]*B[1][j]+...+A[i][m-1]*B[m- ...
- Spring Cloud学习记录
Eureka和zookeeper都是注册中心为什么zookeeper不适合? 1.CAP原则.一致性,可用性,分区容错性,最多满足两种.zookeeper遵循CP原则,实际项目中不应该为了一致性失去可 ...
- 解决IOS上传竖向照片会旋转90度的问题
// 解决IOS上传竖向照片会旋转90度的问题 rotate() { const that = this; that.imgOrientation = 1; let Orientation = nul ...
- 十大经典排序之快速排序(C++实现)
快速排序 通过一趟排序将待排序列分割成两部分,其中一部分记录的关键字均比另一部分记录的关键字小.之后分别对这两部分记录继续进行排序,以达到整个序列有序的目的. 思路: (1)选择基准:从数列中挑出一个 ...
- OSIDP-文件管理-12(end)
概述 文件特性:可长期存储:可在进程间共享:有特定结构. 文件系统提供对文件操作的功能接口:创建.删除.打开.关闭.读和写. 域(field):基本数据单元,一个域包含一个值. 记录(record): ...
- toString能转换number类型吗
let num = 60console.log(toString(num)) // [object Undefined] console.log(String(num)) // 60
- Linux CentOS Docker 安装、加载配置
Docker Version:2.10.2 OS: CentOS 7 1.卸载 $ sudo yum remove docker \ docker-client \ docker-client-lat ...
- 【jupyter notebook】设置jupyter notebook自动补全功能
安装插件 pip install jupyter_contrib_nbextensions jupyter contrib nbextension install --user 重启jupyter,在 ...
- 7.webpack与vue-cli
一.模块化相关规范 1.1 模块化概述 传统开发模式的主要问题 命名冲突:多个JS文件之间,如果存在重名的变量,会发生变量覆盖问题 文件依赖:JS文件无法实现相互的引用 通过模块化解决上述问题 模块化 ...