Apache Hudi 流转批 场景实践
背景
在某些业务场景下,我们需要一个标志来衡量hudi数据写入的进度,比如:Flink 实时向 Hudi 表写入数据,然后使用这个 Hudi 表来支持批量计算并通过一个 flag 来评估它的分区数据是否完整从而进一步写入分区数据进行分区级别的ETL,这也就是我们通常说的流转批。
EventTime计算原理

图中Flink Sink包含了两个算子。第一个writer 算子,它负责把数据写入文件,writer在checkpoint触发时,会把自己写入的最大的一个时间传到commit算子中,然后commit算子从多个上游传过来的时间中选取一个最小值作为这一批提交数据的时间,并写入HUDI表的元数据中。
案例使用
我们的方案是将这个进度值(EventTime)存储为 hudi 提交(版本)元数据的属性里,然后通过访问这个元数据属性获取这个进度值。在下游的批处理任务之前加一个监控任务去监控最新快照元数据。如果它的时间已经超过了当前的分区时间,就认为这个表的数据已经完备了,这个监控任务就会成功触发下游的批处理任务进行计算,这样可以防止在异常场景下数据管道或者批处理任务空跑的情况。
下图是一个flink 1分钟级别入库到HUDI ODS表, 然后通过流转批计算写入HUDI DWD表的一个执行过程。
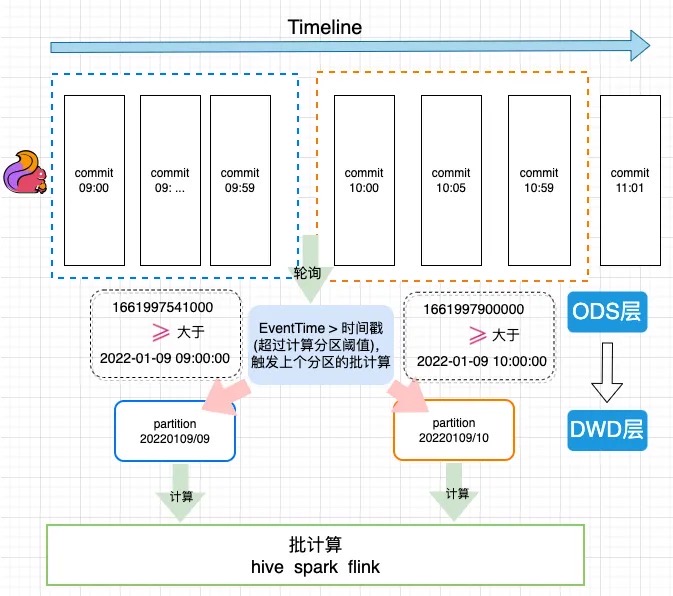
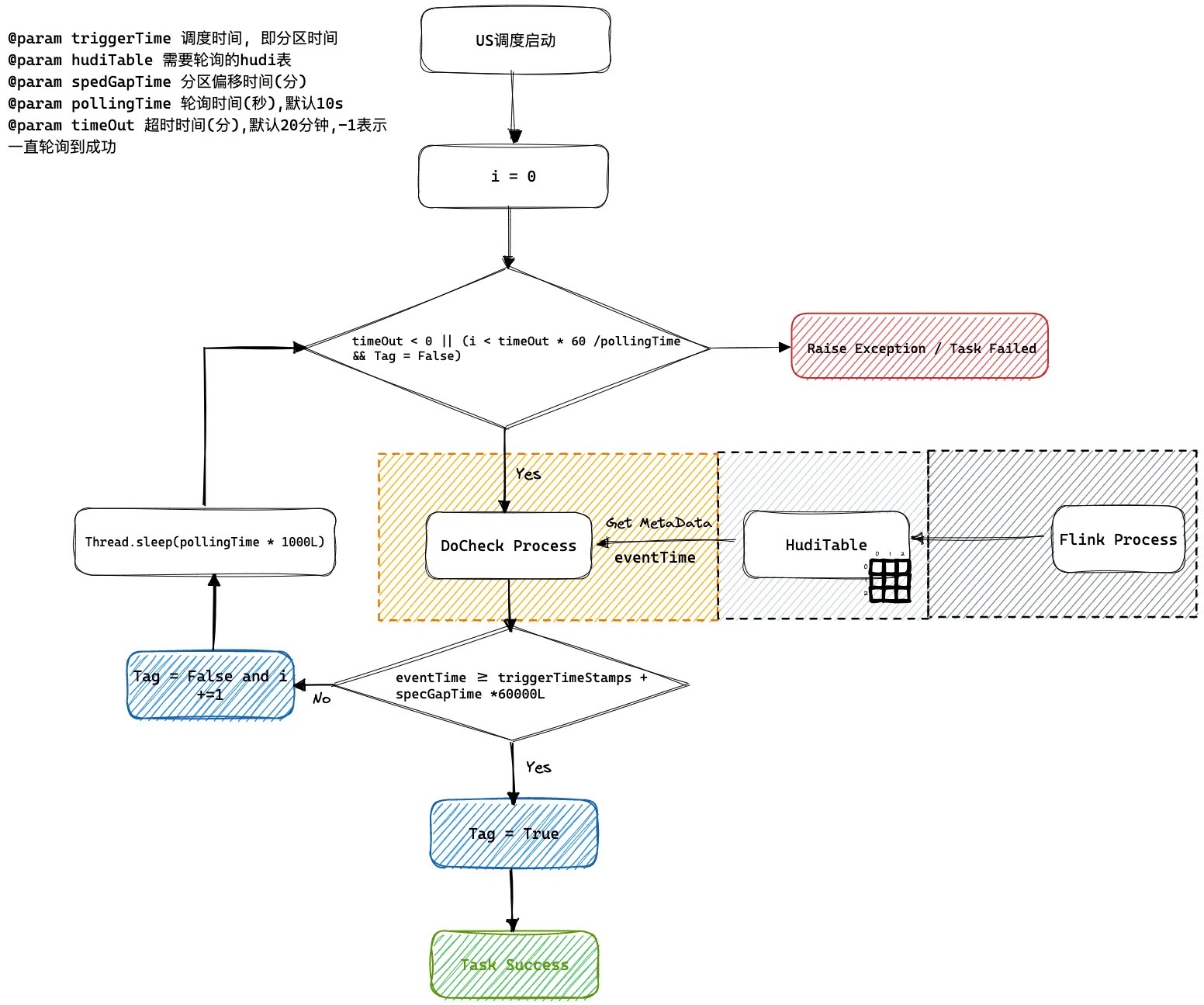
US调度系统轮询逻辑
如何解决乱序到来问题, 我们可以通过设置spedGapTime来设置允许延迟到来的范围默认是0 不会延迟到来。
Maven pom 依赖
针对此功能特性的Hudi依赖版本如下
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.13-bundle</artifactId>
<version>0.12.1</version>
</dependency>
</dependencies>
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.15-bundle</artifactId>
<version>0.12.1</version>
</dependency>
</dependencies>
如何设置EventTime
能够解析的字段类型及格式如下:
| 类型 | 示例 |
|---|---|
| TIMESTAMP(3) | 2012-12-12T12:12:12 |
| TIMESTAMP(3) | 2012-12-12 12:12:12 |
| DATE | 2012-12-12 |
| BIGINT | 100L |
| INT | 100 |
Flink API
用户只需要设置flink conf指定时间字段作为时间推进字段
Map<String, String> options = new HashMap<>();
// 这里省略其他表字段
options.put(FlinkOptions.EVENT_TIME_FIELD.key(), "ts");
HoodiePipeline.Builder builder = HoodiePipeline.builder(targetTable)
.column("id int not null")
.column("ts string")
.column("dt string")
.pk("id")
.partition("dt")
.options(options);
Flink SQL
通过设置hoodie.payload.event.time.field指定需要计算的eventtime的字段
create table hudi_cow_01(\n" +
" uuid varchar(20),\n" +
" name varchar(10),\n" +
" age int,\n" +
" ts timestamp(3),\n" +
" PRIMARY KEY(uuid) NOT ENFORCED\n" +
")\n" +
" with (\n" +
// 这里省略其他参数
" 'hoodie.payload.event.time.field' = 'ts'\n"
")
如何读取EventTime
Spark SQL
call show_commit_extra_metadata(table => 'hudi_tauth_test.hudi_cow_01', metadata_key => 'hoodie.payload.event.time.field');

Java API
代码获取片段如下
Option<HoodieCommitMetadata> commitMetadataOption = MetadataConversionUtils.getHoodieCommitMetadata(metaClient, currentInstant);
if (!commitMetadataOption.isPresent()) {
throw new HoodieException(String.format("Commit %s not found commitMetadata in Commits %s.", currentInstant, timeline));
}
// 获取到当前版本的时间进度
String eventTime = commitMetadataOption.get().getExtraMetadata().get(FlinkOptions.EVENT_TIME_FIELD.key());
System.out.println("current eventTime: " + eventTime);
输出结果如下
current eventTime: 1667971364742
Apache Hudi 流转批 场景实践的更多相关文章
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- Apache Hudi典型应用场景知多少?
1.近实时摄取 将数据从外部源如事件日志.数据库提取到Hadoop数据湖 中是一个很常见的问题.在大多数Hadoop部署中,一般使用混合提取工具并以零散的方式解决该问题,尽管这些数据对组织是非常有价值 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
随机推荐
- [论文阅读] 颜色迁移-N维pdf迁移
[论文阅读] 颜色迁移-N维pdf迁移 文章: N-Dimensional Probability Density Function Transfer and its Application to C ...
- jsp 页面返回、本页面刷新
返回上一页面: window.history.go(-1); //返回上一页window.history.back(); //返回上一页 返回上一页面并对上一页面刷新: history.go(-1 ...
- 【Java SE进阶】Day07 等待与唤醒案例、线程池、Lamdba表达式
一.等待唤醒机制 1.线程间通信 多个线程处理同一个资源,就存在线程通信问题(线程间存在竞争与协作机制) 为什么处理:为了 保证多个线程有规律地完成同一任务 如何处理:避免对共享变量争夺,需要等待唤醒 ...
- 全都会!预测蛋白质标注!创建讲义!解释数学公式!最懂科学的智能NLP模型Galactica尝鲜 ⛵
作者:韩信子@ShowMeAI 机器学习实战系列:https://www.showmeai.tech/tutorials/41 深度学习实战系列:https://www.showmeai.tech/t ...
- 【机器学习】李宏毅——Unsupervised Learning
读这篇文章之间欢迎各位先阅读我之前写过的线性降维的文章.这篇文章应该也是属于Unsupervised Learning的内容的. Neighbor Embedding Manifold Learnin ...
- 图计算引擎分析——Gemini
前言 Gemini 是目前 state-of-art 的分布式内存图计算引擎,由清华陈文光团队的朱晓伟博士于 2016 年发表的分布式静态数据分析引擎.Gemini 使用以计算为中心的共享内存图分布式 ...
- csp-j 游记
### 初赛 day -7 ~ day -1 赛前集训,都很简单,什么二叉树,图论呀,轻松搞定.做了 $2008$ 至 $2015$ 年的普及组真题,都在 $50$ 分以上,感觉初赛稳了(坐标 $HN ...
- Redis 如何批量设置过期时间?PIPLINE的使用
合理的使用缓存策略对开发同学来讲,就好像孙悟空习得自在极意功一般~ 抛出问题 Redis如何批量设置过期时间呢? 不要说在foreach中通过set()函数批量设置过期时间 给出方案 我们引入redi ...
- CH432,CH438,CH9434串口扩展芯片常见问题
目前WCH有三款串口扩展芯片CH432,CH438以及CH9434. 型号 CH432 CH438 CH9434 扩展串口数量 2 8 4 通讯接口 并口/SPI(具体需要看芯片封装) 并口 SPI ...
- 如何使用 Blackbox Exporter 监控 URL?
前言 监控域名和 URL 是可观察性的一个重要方面,主要用于诊断可用性问题.接下来会详细介绍如何使用 Blackbox Exporter 和 Prometheus 在 Kubernetes 中实现 U ...