Apache Hudi 流转批 场景实践
背景
在某些业务场景下,我们需要一个标志来衡量hudi数据写入的进度,比如:Flink 实时向 Hudi 表写入数据,然后使用这个 Hudi 表来支持批量计算并通过一个 flag 来评估它的分区数据是否完整从而进一步写入分区数据进行分区级别的ETL,这也就是我们通常说的流转批。
EventTime计算原理

图中Flink Sink包含了两个算子。第一个writer 算子,它负责把数据写入文件,writer在checkpoint触发时,会把自己写入的最大的一个时间传到commit算子中,然后commit算子从多个上游传过来的时间中选取一个最小值作为这一批提交数据的时间,并写入HUDI表的元数据中。
案例使用
我们的方案是将这个进度值(EventTime)存储为 hudi 提交(版本)元数据的属性里,然后通过访问这个元数据属性获取这个进度值。在下游的批处理任务之前加一个监控任务去监控最新快照元数据。如果它的时间已经超过了当前的分区时间,就认为这个表的数据已经完备了,这个监控任务就会成功触发下游的批处理任务进行计算,这样可以防止在异常场景下数据管道或者批处理任务空跑的情况。
下图是一个flink 1分钟级别入库到HUDI ODS表, 然后通过流转批计算写入HUDI DWD表的一个执行过程。
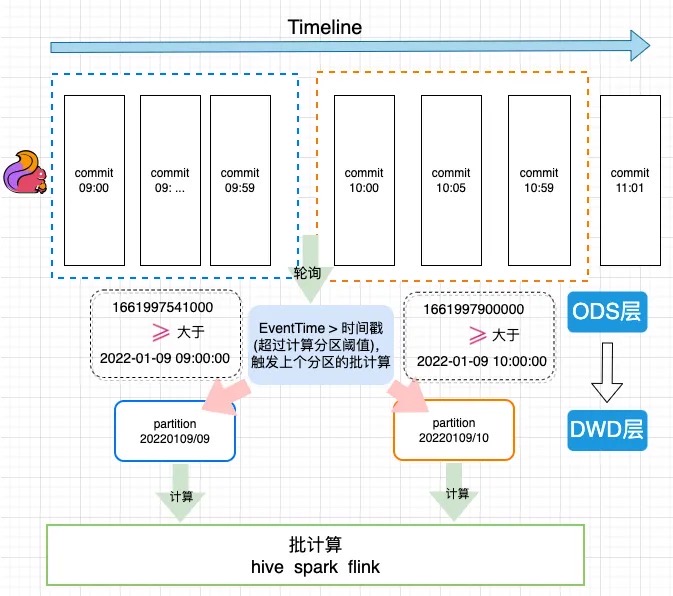
US调度系统轮询逻辑
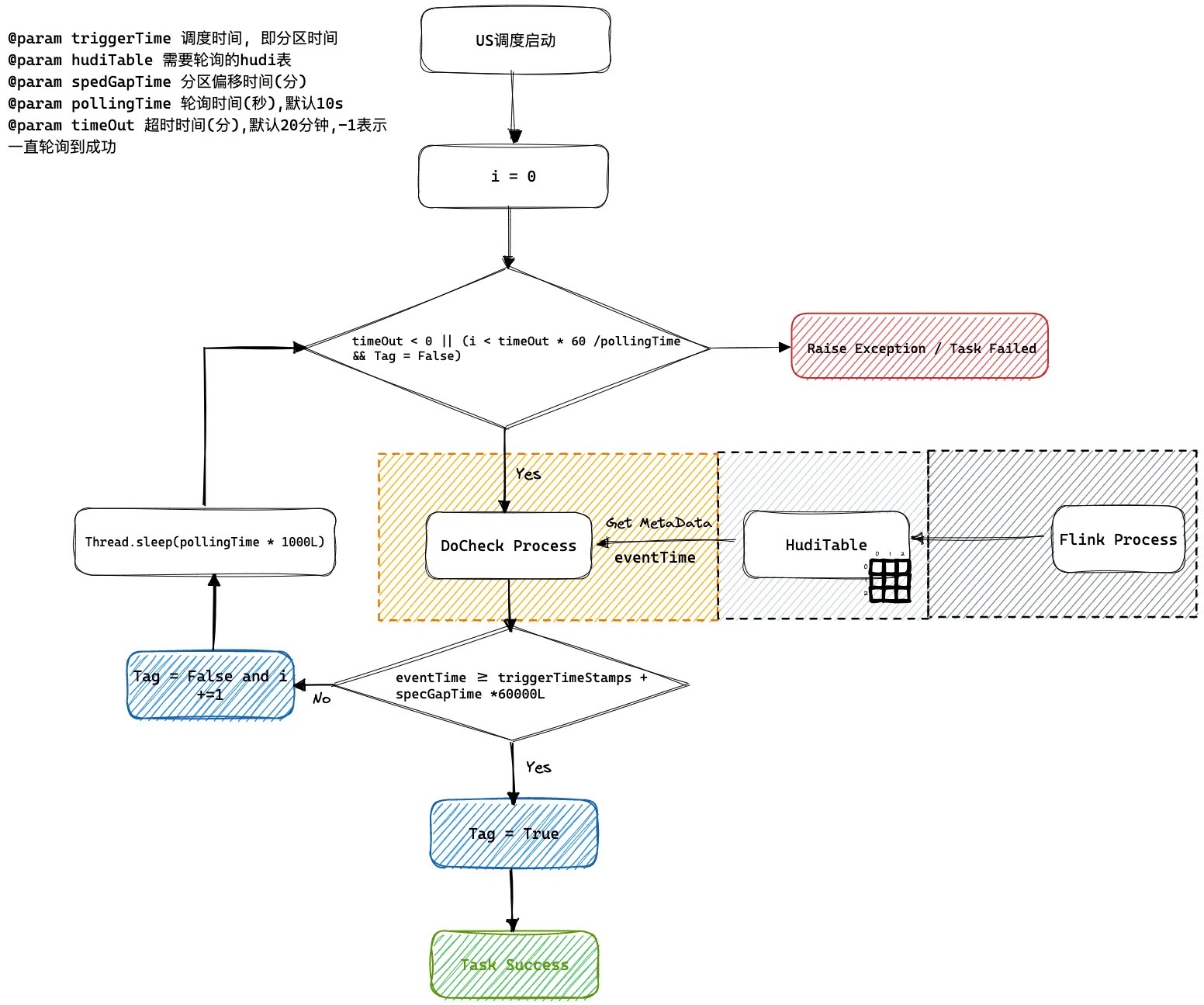
如何解决乱序到来问题, 我们可以通过设置spedGapTime来设置允许延迟到来的范围默认是0 不会延迟到来。
Maven pom 依赖
针对此功能特性的Hudi依赖版本如下
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.13-bundle</artifactId>
<version>0.12.1</version>
</dependency>
</dependencies>
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.15-bundle</artifactId>
<version>0.12.1</version>
</dependency>
</dependencies>
如何设置EventTime
能够解析的字段类型及格式如下:
| 类型 | 示例 |
|---|---|
| TIMESTAMP(3) | 2012-12-12T12:12:12 |
| TIMESTAMP(3) | 2012-12-12 12:12:12 |
| DATE | 2012-12-12 |
| BIGINT | 100L |
| INT | 100 |
Flink API
用户只需要设置flink conf指定时间字段作为时间推进字段
Map<String, String> options = new HashMap<>();
// 这里省略其他表字段
options.put(FlinkOptions.EVENT_TIME_FIELD.key(), "ts");
HoodiePipeline.Builder builder = HoodiePipeline.builder(targetTable)
.column("id int not null")
.column("ts string")
.column("dt string")
.pk("id")
.partition("dt")
.options(options);
Flink SQL
通过设置hoodie.payload.event.time.field指定需要计算的eventtime的字段
create table hudi_cow_01(\n" +
" uuid varchar(20),\n" +
" name varchar(10),\n" +
" age int,\n" +
" ts timestamp(3),\n" +
" PRIMARY KEY(uuid) NOT ENFORCED\n" +
")\n" +
" with (\n" +
// 这里省略其他参数
" 'hoodie.payload.event.time.field' = 'ts'\n"
")
如何读取EventTime
Spark SQL
call show_commit_extra_metadata(table => 'hudi_tauth_test.hudi_cow_01', metadata_key => 'hoodie.payload.event.time.field');

Java API
代码获取片段如下
Option<HoodieCommitMetadata> commitMetadataOption = MetadataConversionUtils.getHoodieCommitMetadata(metaClient, currentInstant);
if (!commitMetadataOption.isPresent()) {
throw new HoodieException(String.format("Commit %s not found commitMetadata in Commits %s.", currentInstant, timeline));
}
// 获取到当前版本的时间进度
String eventTime = commitMetadataOption.get().getExtraMetadata().get(FlinkOptions.EVENT_TIME_FIELD.key());
System.out.println("current eventTime: " + eventTime);
输出结果如下
current eventTime: 1667971364742
Apache Hudi 流转批 场景实践的更多相关文章
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- Apache Hudi典型应用场景知多少?
1.近实时摄取 将数据从外部源如事件日志.数据库提取到Hadoop数据湖 中是一个很常见的问题.在大多数Hadoop部署中,一般使用混合提取工具并以零散的方式解决该问题,尽管这些数据对组织是非常有价值 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
随机推荐
- kubernetes笔记-2-基本操作
一.kubectl的基本操作 语法: kubectl [command] [type] [name] [flags] 语法说明: command:对资源执行相应操作的子命令,如:get.cre ...
- 2.10:数据加工与展示-pandas清洗、Matplotlib绘制
〇.目标 1. 使用pandas完成基本的数据清洗加工处理: 2. 使用Matplotlib进行简单的数据图形化展示. 一.用pandas清洗处理数据 1.判断是否存在空值 数据缺失在很多数据中存在, ...
- CORS与CSRF在Spring Security中的使用
背景 在项目使用了Spring Security之后,很多接口无法访问了,从浏览器的网络调试窗看到的是CORS的报错和403的报错 分析 我们先来看一下CORS是什么,和它很相似的CSRF是什么,在S ...
- 开局一张图,构建神奇的 CSS 效果
假设,我们有这样一张 Gif 图: 利用 CSS,我们尝试来搞一些事情. 图片的 Glitch Art 风 在这篇文章中 --CSS 故障艺术,我们介绍了利用混合模式制作一种晕眩感觉的视觉效果.有点类 ...
- [OpenCV实战]17 基于卷积神经网络的OpenCV图像着色
目录 1 彩色图像着色 1.1 定义着色问题 1.2 CNN彩色化结构 1.3 从 中恢复彩色图像 1.4 具有颜色再平衡的多项式损失函数 1.5 着色结果 2 OpenCV中实现着色 2.1 模型下 ...
- Web3区块链DAS域名注册教程 tron trx链波卡钱包地址解析 用户名转账 ENS
而在去中心化系统中,大部分人充值.转账时,使用的都是区块链原生的长地址,比如: ETH 的地址: 0x9euo8sHip*******dHld90 CKB 的地址: ckHUEI829D******* ...
- (6)go-micro微服务consul配置、注册中心
目录 一 Consul介绍 1. 注册中心Consul基本介绍 2.注册中心Consul关键功能 3.注册中心Consul两个重要协议 二 Consul安装 1.使用docker拉取镜像 三 Conf ...
- [超详细] [效能工具]Typora+PicGo+Github免费图床快速搭建,提升技术文档输出效率
一.前言 在我们日常的学习和工作中,我们经常需要进行写作.尤其对于我们程序技术人员而言,工作中的技术方案文档或者接口文档等,都是经常需要用上的. 那么如果没有一个高效的工具,去帮助我们记录和创作,这将 ...
- 数据结构——八大排序算法(java部分实现)
java基本排序算法 1.冒泡排序 顶顶基础的排序算法之一,每次排序通过两两比较选出最小值(之后每个算法都以从小到大排序举例)图片取自:[小不点的博客](Java的几种常见排序算法 - 小不点丶 - ...
- 《Effective C++》实现 章节
Item26:尽可能延后变量定义式的出现时间 Item27:尽量少做转型动作 关于这一点,专门开了一个新的总结: http://blog.csdn.net/m0_37316917/article/de ...