论文阅读笔记(三)【AAAI2017】:Learning Heterogeneous Dictionary Pair with Feature Projection Matrix for Pedestrian Video Retrieval via Single Query Image
Introduction
(1)IVPR问题:
根据一张图片从视频中识别出行人的方法称为 image to video person re-id(IVPR)
应用:
① 通过嫌犯照片,从视频中识别出嫌犯;
② 通过照片,寻找走失人口.
(2)图片-视频行人匹配问题的描述:
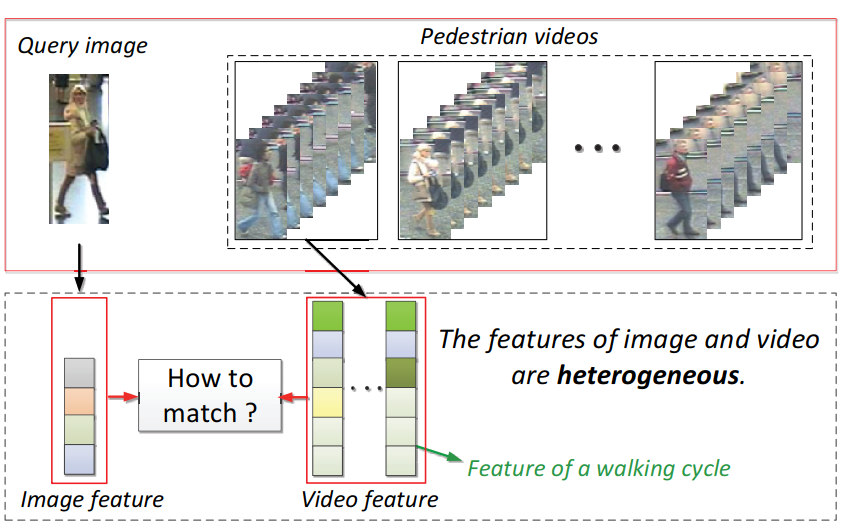
(3)IVPR的难点:
① 图像、视频的特征不同:视频包含视觉外貌特征(visual appearance features)和时空特征(spatial-temporal features),而图片只包含视觉外貌特征;
② IVPR是一个点到集合的匹配问题(point-to-set),每一段视频的不同帧或者步行周期都有较大的变化.
(4)Motivation:
现存的行人重识别方法需要两个对象提供同类的特征,然而在IVPR问题中,只有视觉外貌特征能够从两个对象中提取出,而时空特征只能在视频提取,因此无法应用到现存的方法中. 在视频行人重识别中,时空特征和视觉外貌特征是互补的,不可或缺,仅仅使用视觉外貌特征会限制识别性能. 并且现有的算法并不适用于点到集合的匹配问题.
(5)Contribution:
① 首次对图像-视频匹配问题进行研究.
② 提出了一个联合特征投影矩阵和异构字典对学习方法(PHDL),特征投影矩阵(joint feature projection matrix)使得同一个视频之间的变化降低,异构字典对(heterogeneous dictionary pair)使得异构的图片和视频的特征转换成相同维度的编码;设计了一个点到集合的系数区分度项,确保特征编码有较好的区分度.
③ 设计了一个视频聚集项,来降低视频内部的变化,提高视频的紧凑型.
The Proposed Approach
(1)问题定义:
① 参数及变量定义:
X = {x1, ..., xi, ..., xn}:训练图像特征集,xi 表示第 i 个行人图片,规格为 p 维(其中 n 为行人数量);
Y = {Y1, ..., Yi, ..., Yn}:训练视频特征集,Yi = {yi,1, ..., yi,j, ..., yi,ni} 表示第 i 个行人视频,yi,j 表示第 i 个视频的第 j 个步态周期提取的特征,规格为 q 维(其中 ni 为第 i 个行人的步态周期数);
W:学习得到的特征压缩矩阵(feature projection matrix FPM),规格为 q*q1(其中q1为压缩后的特征维度);
DI:学习得到的图片字典,规格为 p*m(其中 m 为原子数量);
DV:学习得到的视频字典,规格为 q1*m;
A = {a1, ..., ai, ..., an}:X 通过 DI 得到的编码系数矩阵(coding coefficient matrix);
B = {B1, ..., Bi, ..., Bn}:Y 通过 DV 得到的编码系数矩阵,其中 Bi = {bi,1, ..., bi,j, ... bi,ni}.
② PHDL方法介绍:(文中使用到了字典学习,相关知识参考【传送门】)
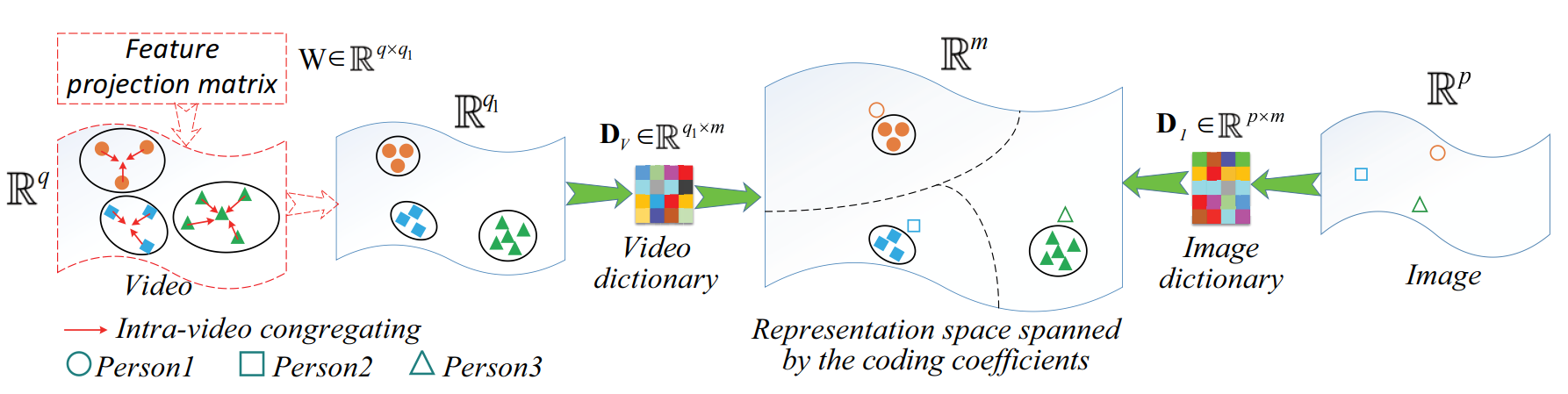
③ 问题定义:
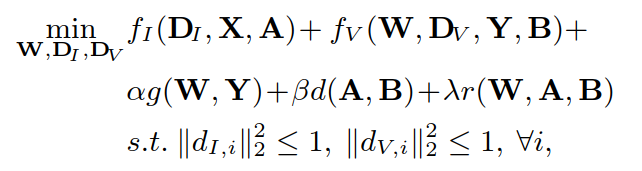
其中的参数和函数:
α、β、γ 是平衡因子(balancing factor),
dI,i、dV,i 是 DI、DV 的第 i 个原子.
 :图片重构保真度项(image reconstruction fidelity term),个人理解:衡量原始数据集和字典矩阵编码后的差异,尽量要缩小两者间的差距,使得编码结果与原始数据更贴近.
:图片重构保真度项(image reconstruction fidelity term),个人理解:衡量原始数据集和字典矩阵编码后的差异,尽量要缩小两者间的差距,使得编码结果与原始数据更贴近.
 :视频重构保真项(video reconstruction fidelity term).
:视频重构保真项(video reconstruction fidelity term).
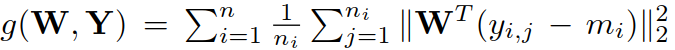 :视频聚合项(video congregating term),理解为所有视频的每个特征与特征均值 m 的距离.
:视频聚合项(video congregating term),理解为所有视频的每个特征与特征均值 m 的距离.
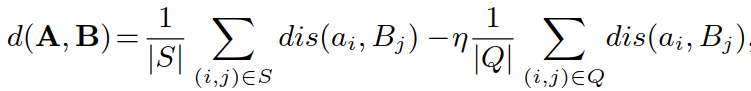 :点到集合编码差异项(point-to-set coefficient discriminant term),对于匹配成功的 image-video pair 距离更短,对于匹配失败的 image-video pair 距离更长,其中
:点到集合编码差异项(point-to-set coefficient discriminant term),对于匹配成功的 image-video pair 距离更短,对于匹配失败的 image-video pair 距离更长,其中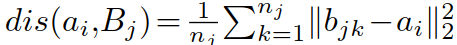 ,S 为匹配成功的集合,Q 为匹配失败的集合,η 为平衡因子.
,S 为匹配成功的集合,Q 为匹配失败的集合,η 为平衡因子.
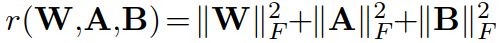 :正则化项(regularization term),个人的理解是正则化项通常用于防止过拟合.
:正则化项(regularization term),个人的理解是正则化项通常用于防止过拟合.
(2)优化算法:
将目标函数分为三个子问题:编码系数更新(A、B更新)、字典矩阵更新(DI、DV更新)、特征投影矩阵更新(W更新).
① 初始化 W、DI、DV、A、B:
首先通过下式的优化,初始化W:
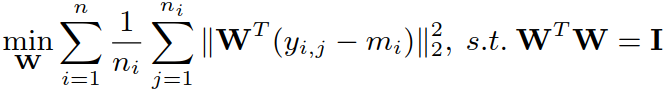
【使用特征分解的方法,同论文笔记二中的推导】
再用随机矩阵的方法对字典矩阵进行初始化;
最后对A、B的初始化可以视为岭回归(ridge regression)问题:
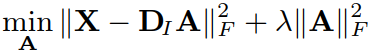

分析得出:

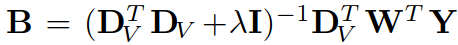
(上式为岭回归问题,参考内容【传送门】)
② W、DI、DV确定,更新A、B:
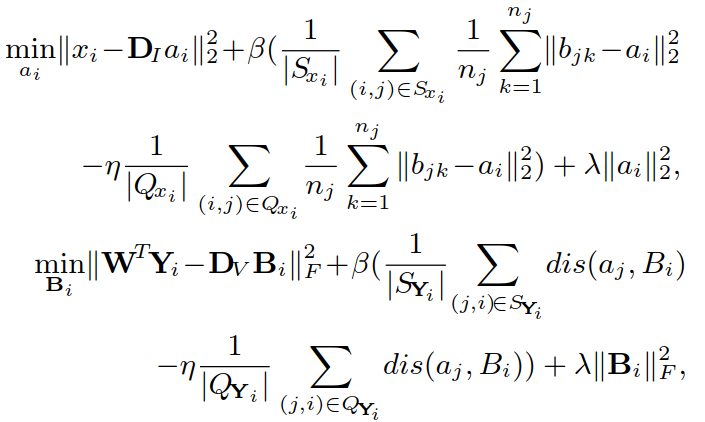
采用求导的方式得到结果(其中 Cj,i 的每一列是 aj):
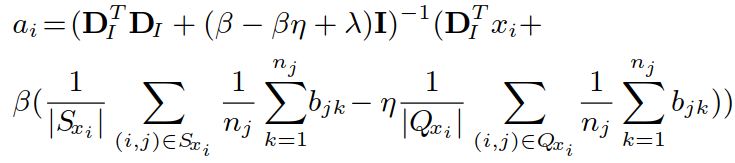
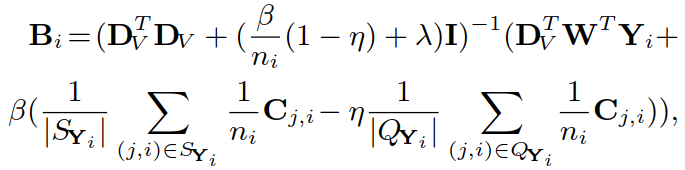
推导过程如下( Bi 类似)

③ 确定 A、B、W,更新 DI 和 DV:
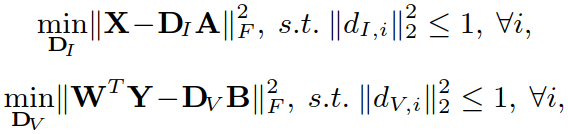
引入变量 S (其中 si 表示 S 中的第 i 个原子):

使用ADMM算法对求解 DI 进行优化(求解 DV 类似):

④ 确定 DI、DV、A、B,更新 W:
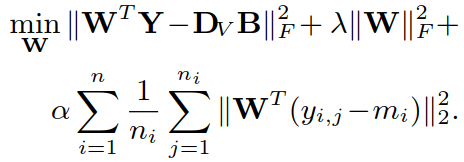
通过求导得出解: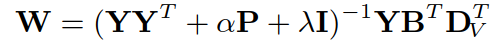
其中 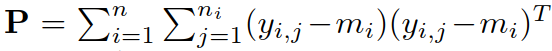 (但我算到的结果不一致)
(但我算到的结果不一致)
推导过程:
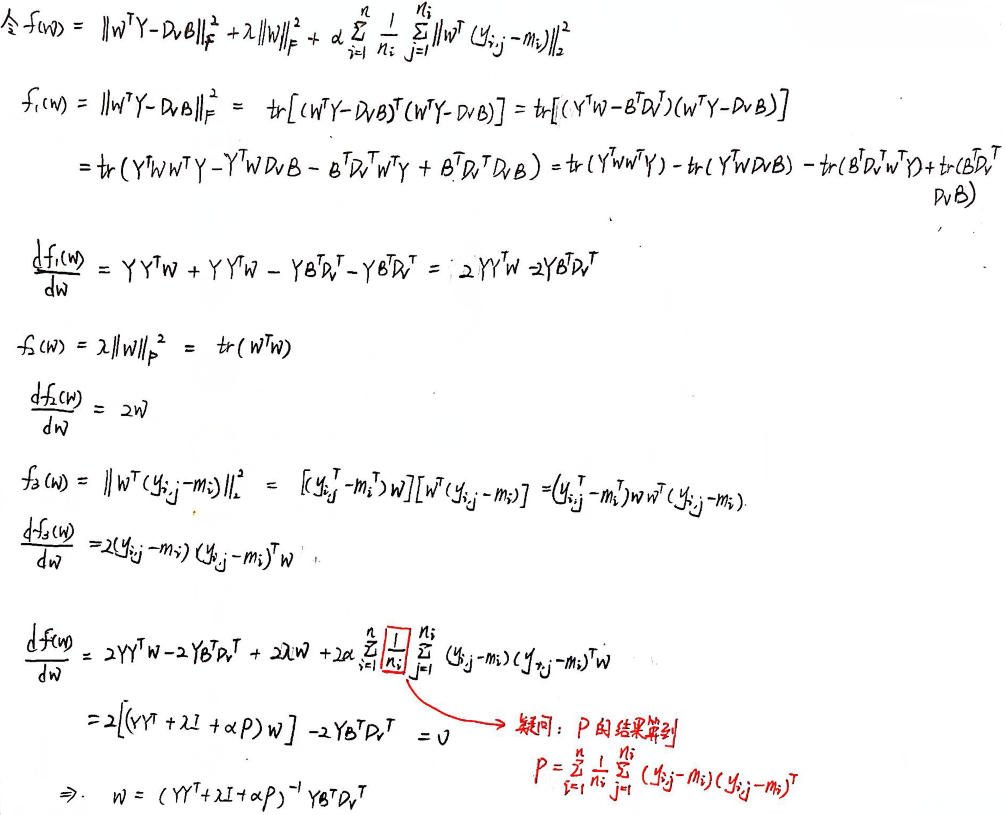
⑤ 优化算法流程:

(3)结果预测:
待测图片:x
视频库:Z = [Z1, ..., Zi, ...,Zl],其中 Zi = [zi,1, ..., zi,j, ..., zi,ni] 表示第 i 个视频的特征集.
行人重识别过程:
① 将图片 x 通过 DI 转为编码a;
② 将视频集 Z 通过 DV 编码 G;
③ 计算两者间的距离: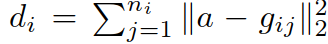 ,对结果进行排序.
,对结果进行排序.
Experimental Results
(1)数据集:
① iLIDS-VID数据集:
该数据集含有300个行人的600个图像序列,每个行人都有来自两个相机拍摄的图像序列.
每个图像序列含有22-192帧,平均还有71帧.
② PRID2011数据集:
Cam-A含有385个行人的图像序列,Cam-B含有749个行人的图像序列.
每个序列含有5-675帧,平均含有84帧(低于20帧的需要被忽略).
(2)实验设置:
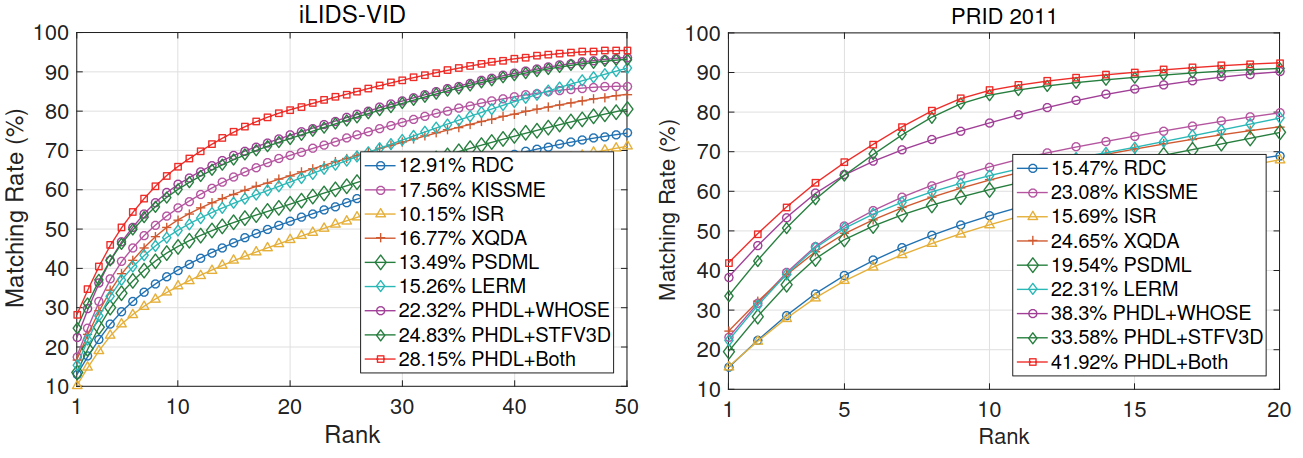
① 对比方法:RDC、KISSME、ISR、XQDA、PSDML、LERM.
② 特征选取:WHOSE、STFV3D.
③ 评估设置:从一个相机的视频序列中随机挑选一帧作为待测图片,从另一个相机的视频中进行识别. 数据集的50%作为训练集,50%作为测试集.
④ 参数设置:对于iLIDS-VID数据集:α = 10, β = 0.8, λ = 0.012, η = 0.12,字典规格120,W的列数460;对于 PRID2011数据集:α = 12, β = 0.7, λ = 0.01, η = 0.14,字典规格180,W的列数380.
(3)实验结果:
Discussion
(1)特征压缩矩阵的效果:
若没有使用特征压缩矩阵 W ,记为 PHDL-W:

(2)字典规格和特征压缩矩阵规格的选择:
根据在iLIDS-VID数据集上的实验结果,最终选定字典大小为120,FPM大小为[400, 600]之间.(PRID2011数据集类似)
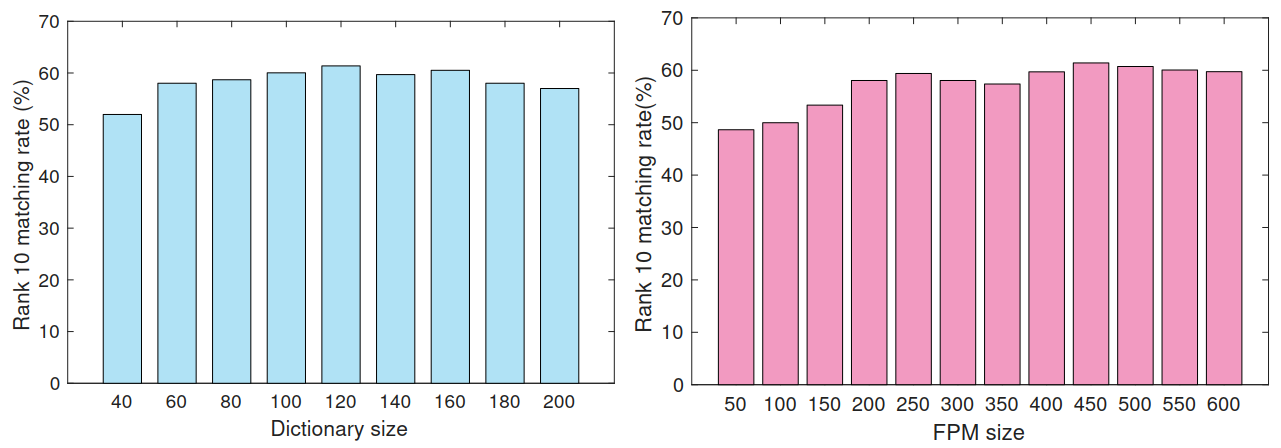
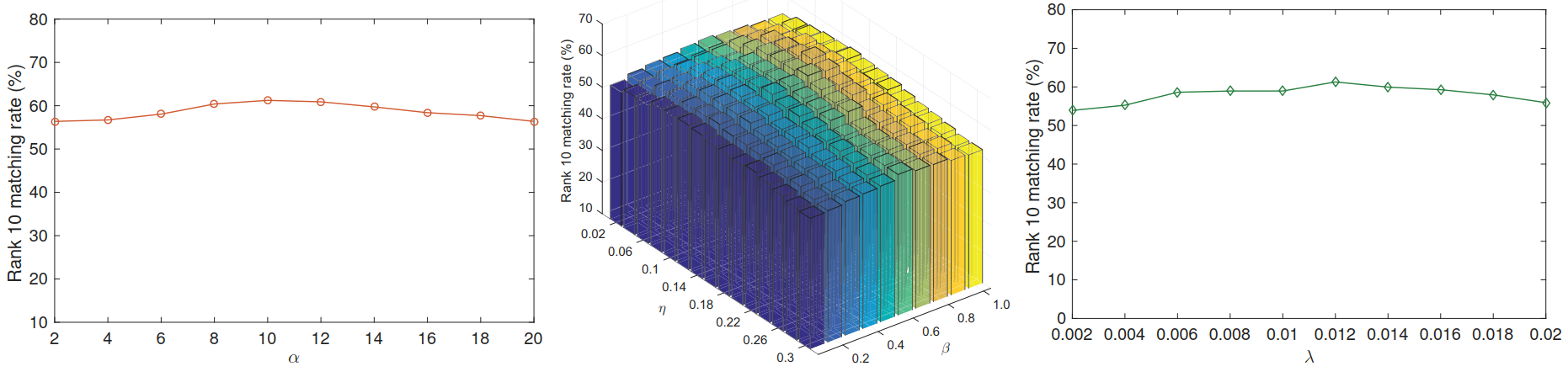
(3)参数的选择:
根据在iLIDS-VID数据集上的实验结果,α 选择[6, 16]之间,β 和 η 选择0.8和0.12,λ 选择[0.006, 0.016]之间.(PRID2011数据集类似)
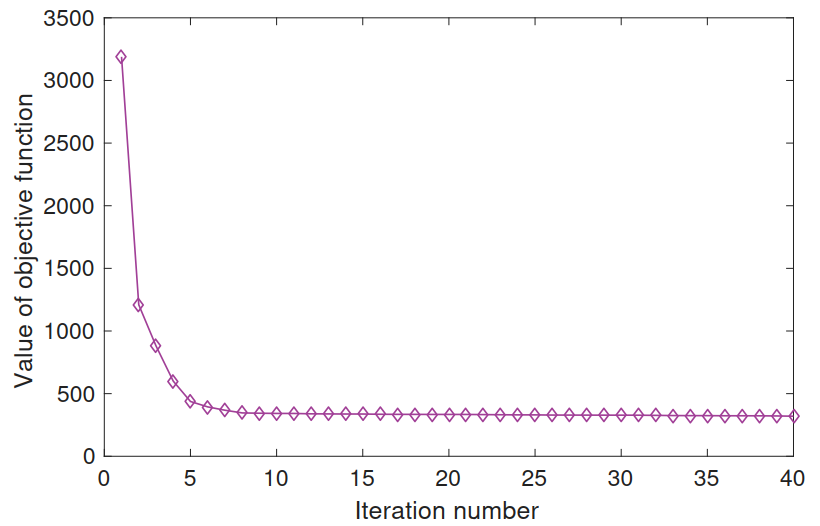
(4)迭代次数的选择:
在实验中,迭代15次基本趋于水平.
论文阅读笔记(三)【AAAI2017】:Learning Heterogeneous Dictionary Pair with Feature Projection Matrix for Pedestrian Video Retrieval via Single Query Image的更多相关文章
- 论文阅读笔记三十:One pixel attack for fooling deep neural networks(CVPR2017)
论文源址:https://arxiv.org/abs/1710.08864 tensorflow代码: https://github.com/Hyperparticle/one-pixel-attac ...
- 论文阅读笔记三:R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection(CVPR2017)
进行文本的检测的学习,开始使用的是ctpn网络,由于ctpn只能检测水平的文字,而对场景图片中倾斜的文本无法进行很好的检测,故将网络换为RRCNN(全称如题).小白一枚,这里就将RRCNN的论文拿来拜 ...
- 论文阅读笔记三十九:Accurate Single Stage Detector Using Recurrent Rolling Convolution(RRC CVPR2017)
论文源址:https://arxiv.org/abs/1704.05776 开源代码:https://github.com/xiaohaoChen/rrc_detection 摘要 大多数目标检测及定 ...
- 论文阅读笔记三十七:Grid R-CNN(CVPR2018)
论文源址:https://arxiv.org/abs/1811.12030 开源代码:未公开 摘要 本文提出了目标检测网络Grid R-CNN,其基于网格定位机制实现准确的目标检测.传统方法主要基于回 ...
- 论文阅读笔记三十六:Mask R-CNN(CVPR2017)
论文源址:https://arxiv.org/pdf/1703.06870.pdf 开源代码:https://github.com/matterport/Mask_RCNN 摘要 Mask R-CNN ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 论文阅读笔记三十一:YOLO 9000: Better,Faster,Stronger(CVPR2016)
论文源址:https://arxiv.org/abs/1612.08242 代码:https://github.com/longcw/yolo2-pytorch 摘要 本文提出YOLO9000可以检测 ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 论文阅读笔记三十五:R-FCN:Object Detection via Region-based Fully Convolutional Networks(CVPR2016)
论文源址:https://arxiv.org/abs/1605.06409 开源代码:https://github.com/PureDiors/pytorch_RFCN 摘要 提出了基于区域的全卷积网 ...
随机推荐
- C# 获取键盘钩子,屏蔽键盘按键
static int hHook = 0; public delegate int HookProc(int nCode, int wParam, IntPtr lParam); //LowLevel ...
- AndroidStudio报错:Could not download gradle.jar:No cacahed version available for offline mode
场景 在讲Android Studio 的.gradle目录从默认C盘修改为 别的目录后,新建app提示: Could not download gradle.jar:No cacahed versi ...
- MySQL中使用group by 是总是出现1055的错误
因为在MySQL中使用group by 是总是出现1055的错误,这就导致了必须去查看是什么原因了,查询了相关的资料,现在将笔记记录下来,以便后面可以参考使用: sql_mode:简而言之就是:它定义 ...
- 简易音乐播放器主界面设计 - .NET CORE(C#) WPF开发
微信公众号:Dotnet9,网站:Dotnet9,问题或建议:请网站留言, 如果对您有所帮助:欢迎赞赏. 简易音乐播放器主界面设计 - .NET CORE(C#) WPF开发 阅读导航 本文背景 代码 ...
- Openshift V3系列各组件版本
Openshift V3.* 系列各组件版本 Components 3.0 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.9 3.10 3.11 Core Components dock ...
- LINUX系统(CentOS7安装)一之JDK8的安装
JDK 的安装系统安装就不做过多介绍,大家从网上寻找安装步骤进行安装,不过我推荐大家进行安装时选择桌面图形化格式进行安装,方便做一部分操作,同时在安装过程中选择英文模式,同时我自己在安装的过程中发现使 ...
- LAMP搭建随笔
前言 这是我第一次在写博客,里面记录了我配置LAMP遇到的各种各样的细节,也许表述不够准确,希望大佬给于批评指正 环境 OS Ubuntu server 18.04.3 远程连接软件 cmder 文件 ...
- 纪中21日c组T2 2117. 【2016-12-30普及组模拟】台风
2117. 台风 (File IO): input:storm.in output:storm.out 时间限制: 1000 ms 空间限制: 262144 KB 具体限制 Goto Proble ...
- 基于XML的声明式事务控制
1.maven依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="h ...
- TC SRM556 OldBridges
题意 有一个包含\(n\)个点的图,点的编号分别为\(0\)到\(n-1\).有若干双向边连接两个点,有些边可以经过无限次,有些边最多只能经过(双向)两次.Alice计划从\(a1\)到\(a2\)进 ...