ELK学习实验013:ELK的一个完整的配置操作
前面做了关于ELK组件的各个实验,但是并没有真正的把各个组件结合起来做一个实验,现在使用一个脚本简单的生成日志,模拟生产不断产生日志的效果
一 流程说明

使用脚本产生日志,模拟用户的操作
日志的格式
[INFO] -- :: [cn.success.dashboard.Main] -DAU||使用优惠卷|-- ::
日志的格式时"DAU" + userID + "|" + visit + "|" +date
通过Filebeat读取日志文件的内容,并将内容发送给Logstash,,原因时需要对内容做处理
Logstash接收到内容后,进行处理,如分割操作,然后将内容发送到 Elasticsearch中
Kiana会读取 Elasticsearch中的数据,并且在 Kiana中进行设计 Dashboard,最后进行展示
后面的日志格式,图表,Dashboard都是自定义的
二 编一个日志的脚本
为了方便实验,脚本很简陋,只是一个输入工具,没有什么实际作用
2.1 日志内容如下
#!/bin/bash
visit_array=("浏览页面" "评论商品" "加入收藏" "加入购物车" "提交订单" "使用优惠卷" "领取优惠卷" "搜索" "查看订单")
visit_number=`head /dev/urandom | cksum | cut -c -`
id_number=`head /dev/urandom | cksum | cut -c -`
echo "[INFO] `date +%F` `date|awk '{print $4}'` [cn.success.dashboard.Main] - DAU|$id_number|${visit_array[$visit_number]}|`date +%F` `date|awk '{print $4}'`"
2.2 执行测试
简单执行一下,看一下效果
[root@node4 ~]# sh /opt/logs.sh
[INFO] -- :: [cn.success.dashboard.Main] - DAU||查看订单|-- ::
[root@node4 ~]# sh /opt/logs.sh
[INFO] -- :: [cn.success.dashboard.Main] - DAU||搜索|-- ::
[root@node4 ~]# sh /opt/logs.sh
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[root@node4 ~]# sh /opt/logs.sh
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[root@node4 ~]# sh /opt/logs.sh
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
2.3 实际操作
然后写一个死循环,两秒执行一次,把这个输入一个日志文件里模拟
[root@node4 ~]# while
> :
> do
> sh /opt/logs.sh >> /var/log/elk-test.log
> sleep
> done
2.4 查看效果
[root@node4 ~]# tail -f /var/log/elk-test.log
[INFO] -- :: [cn.success.dashboard.Main] - DAU||评论商品|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||评论商品|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||提交订单|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||评论商品|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入收藏|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||评论商品|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU|||-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
[INFO] -- :: [cn.success.dashboard.Main] - DAU||加入购物车|-- ::
基本达到一个日志的效果
三 配置filebeat
[root@node4 ~]# cd /usr/local/filebeat/
[root@node4 filebeat]# vi elk-test.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/elk-test.log
setup.template.settings:
index.number_of_shards:
output.logstash:
hosts: ["192.168.132.131:5044"]
四 配置logstash
4.1 初步配置
[root@node1 logstash]# vi elk-test.conf
input {
beats{
port => ""
}
}
filter{
mutate {
split => {"message" => "|"}
}
mutate {
add_field =>{
"UserId" => "%{[message][1]}"
"visit" => "%{[message][2]}"
"date" => "%{[message][3]}"
}
}
}
output {
stdout {codec => rubydebug}
}
先输出到控制台
[root@node1 logstash]# bin/logstash -f elk-test.conf
[--30T05::,][INFO ][org.logstash.beats.Server][main] Starting server on port:
[--30T05::,][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>}
root@node1 ~]# netstat -antlup|grep 5044

再启动filebeat
[root@node4 filebeat]# ./filebeat -e -c elk-test.yml
查看控制台的输出情况

4.2 把数据进行格式化配置
[root@node1 ~]# vim /usr/local/logstash/elk-test.conf
input {
beats{
port => ""
}
}
filter{
mutate {
split => {"message" => "|"}
}
mutate {
add_field =>{
"UserId" => "%{[message][1]}"
"visit" => "%{[message][2]}"
"DateTime" => "%{[message][3]}"
}
}
mutate{
convert => {
"UserId" => "integer"
"visit" => "string"
"DateTime" => "string"
}
}
}
output {
stdout {codec => rubydebug}
}
启动再看
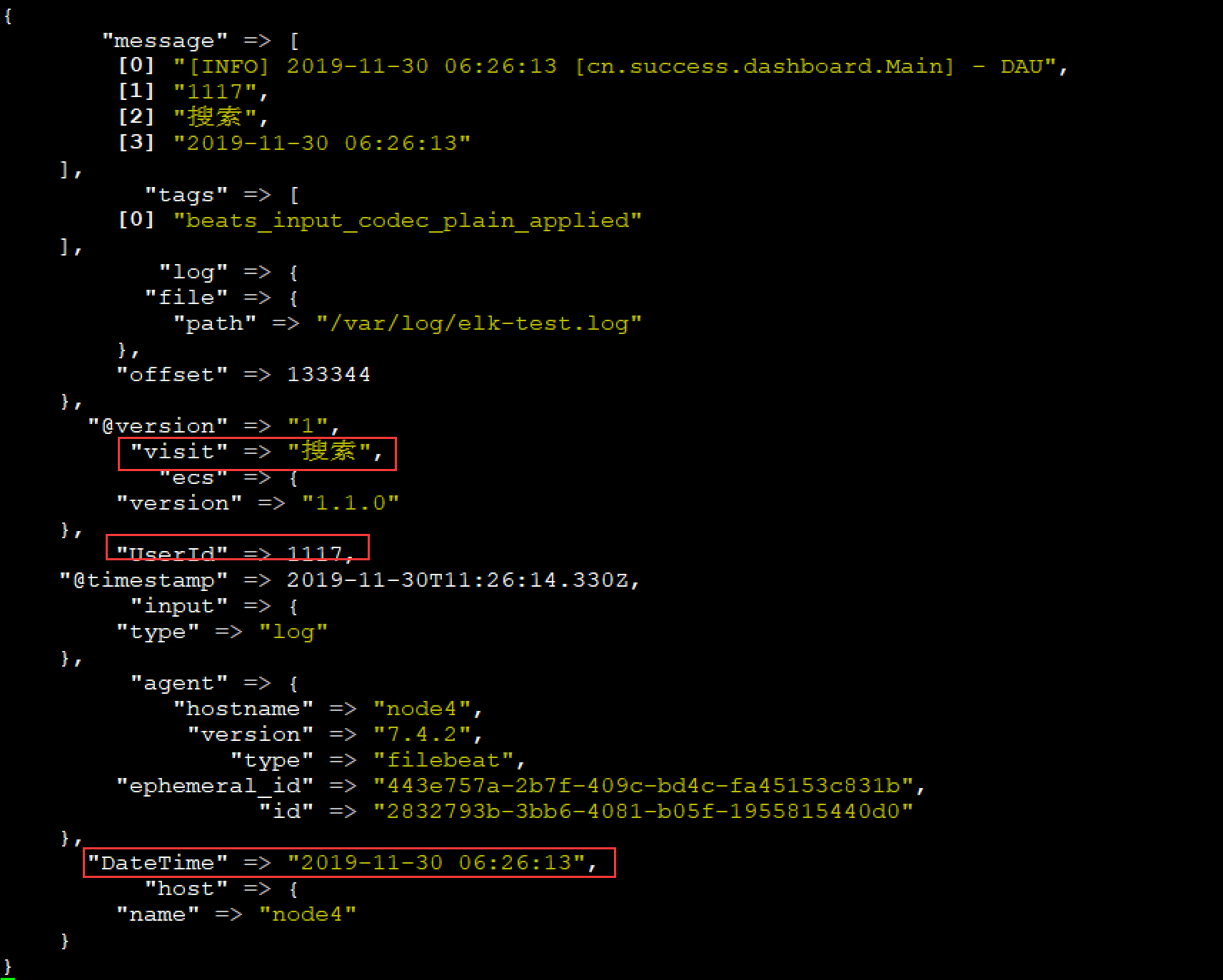
数据处理完成
4.3 数据传到elasticsearch配置
[root@node1 logstash]# vim elk-test.conf
input {
beats{
port => ""
}
}
filter{
mutate {
split => {"message" => "|"}
}
mutate {
add_field =>{
"UserId" => "%{[message][1]}"
"visit" => "%{[message][2]}"
"DateTime" => "%{[message][3]}"
}
}
mutate{
convert => {
"UserId" => "integer"
"visit" => "string"
"DateTime" => "string"
}
}
}
output {
elasticsearch{
hosts => ["192.168.132.131:9200","192.168.132.132:9200","192.168.132.133:9200"]
}
}
启动
[root@node1 logstash]# bin/logstash -f elk-test.conf
使用elasticsearch head查看
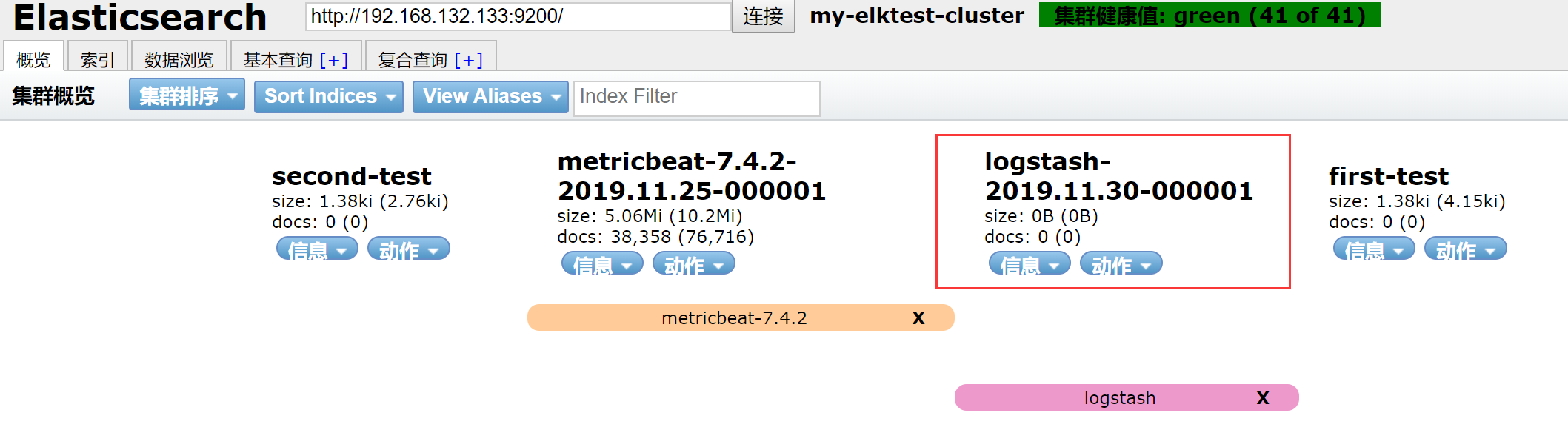
4.4 ES查看原数据
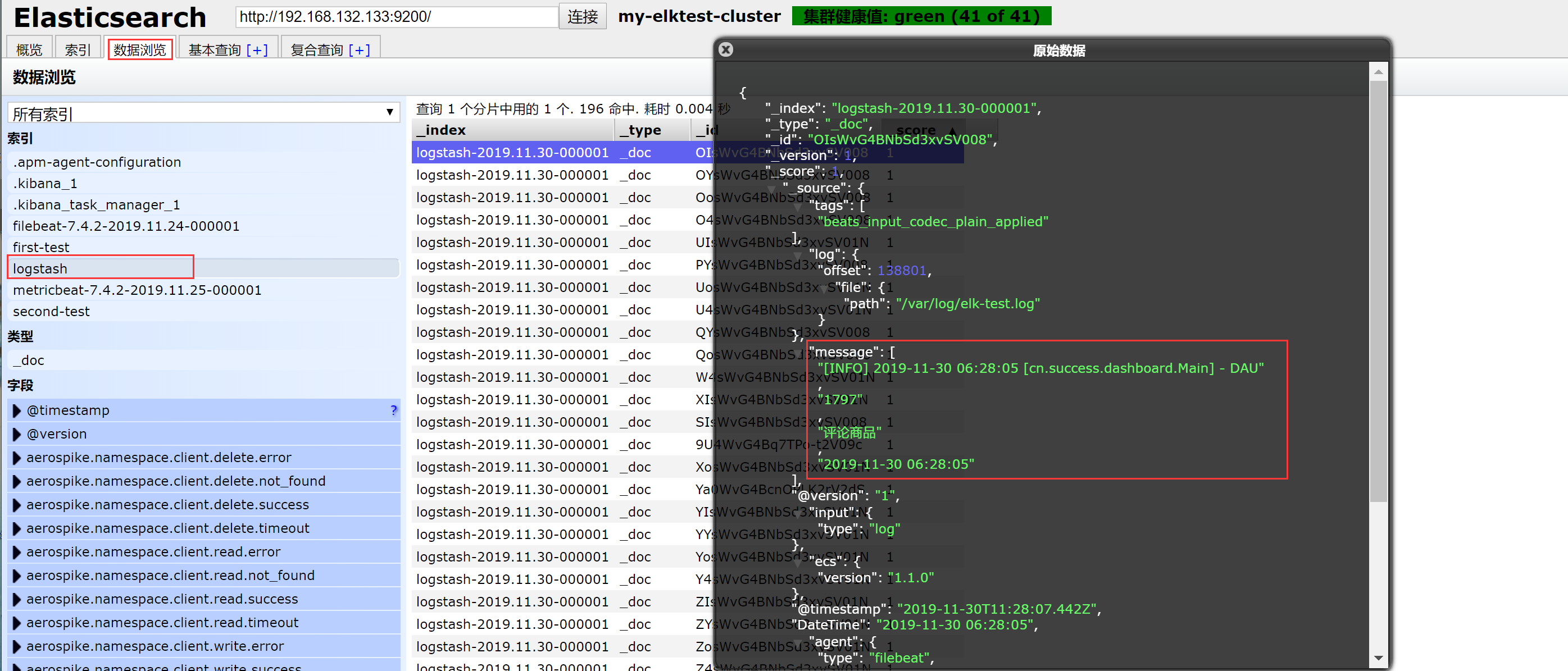
这样就把所有数据收集到elasticsearch上
五 kibana配置
5.1 创建index patten
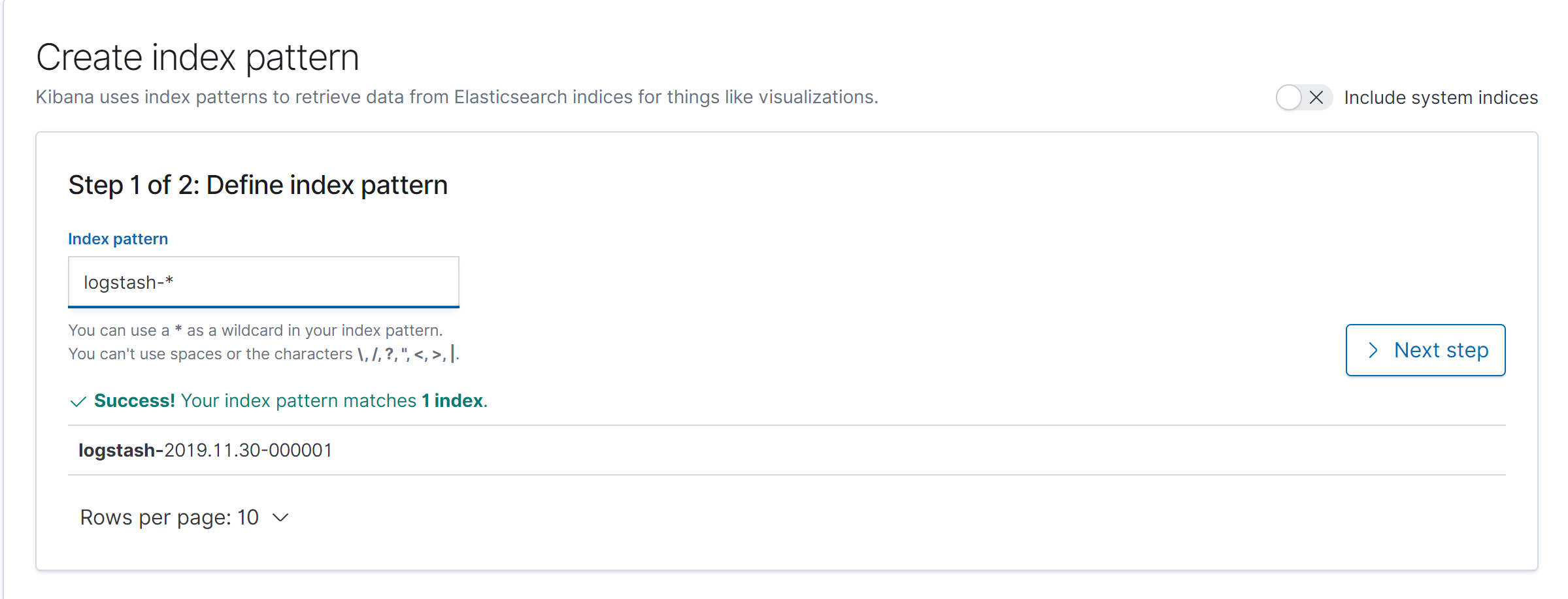
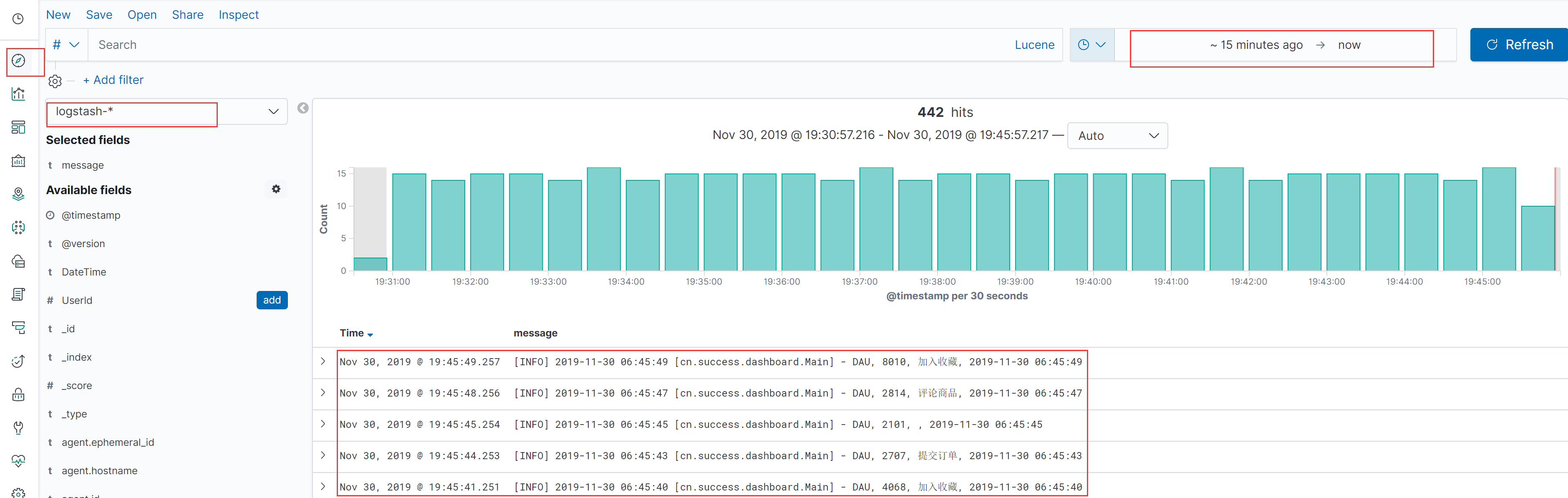
5.2 实时显示数据
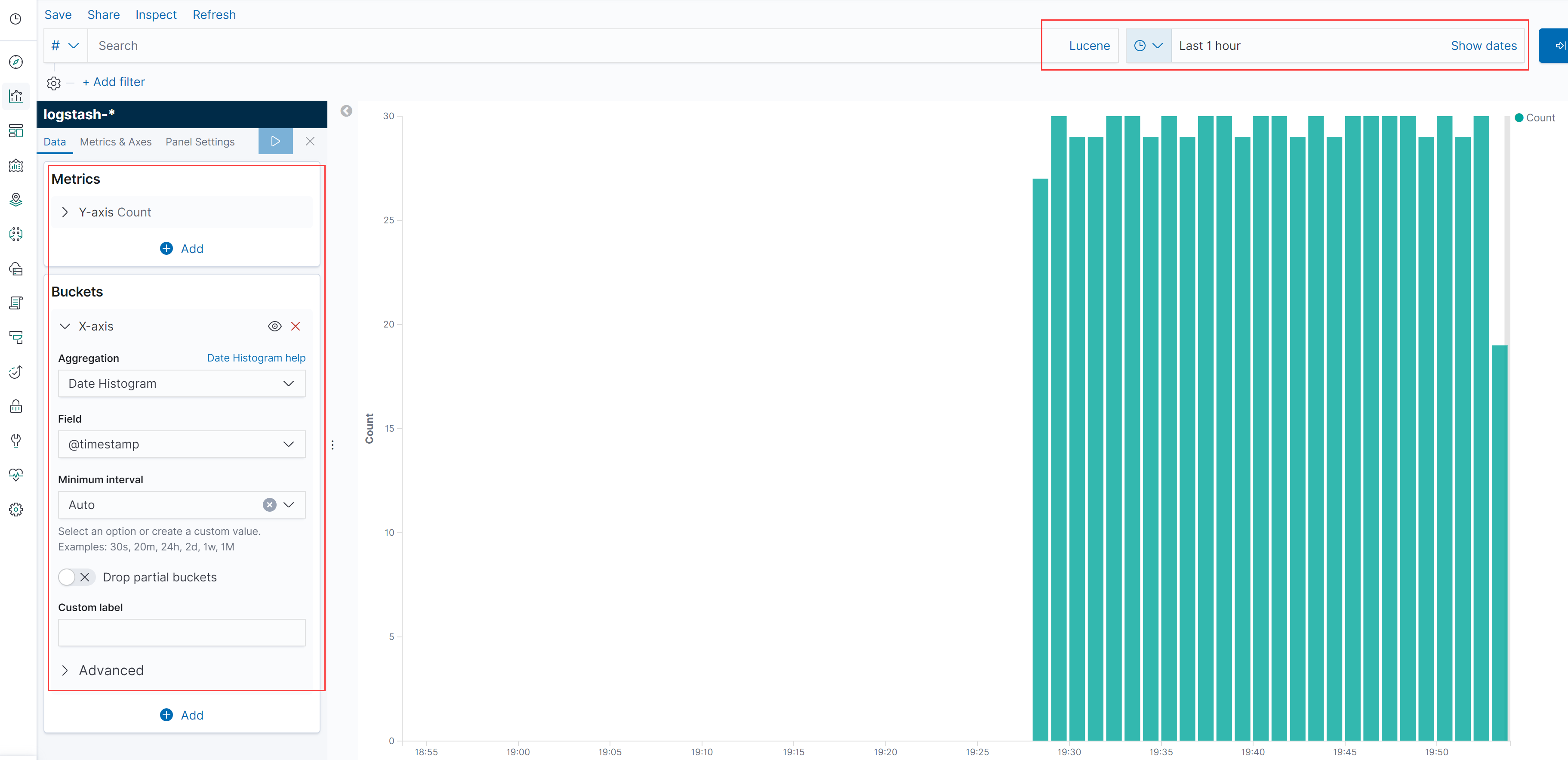
5.3 创建一个以时间间隔的柱状图
详细步骤可参考前面的自定义图表https://www.cnblogs.com/zyxnhr/p/11954663.html

创建结果
保存
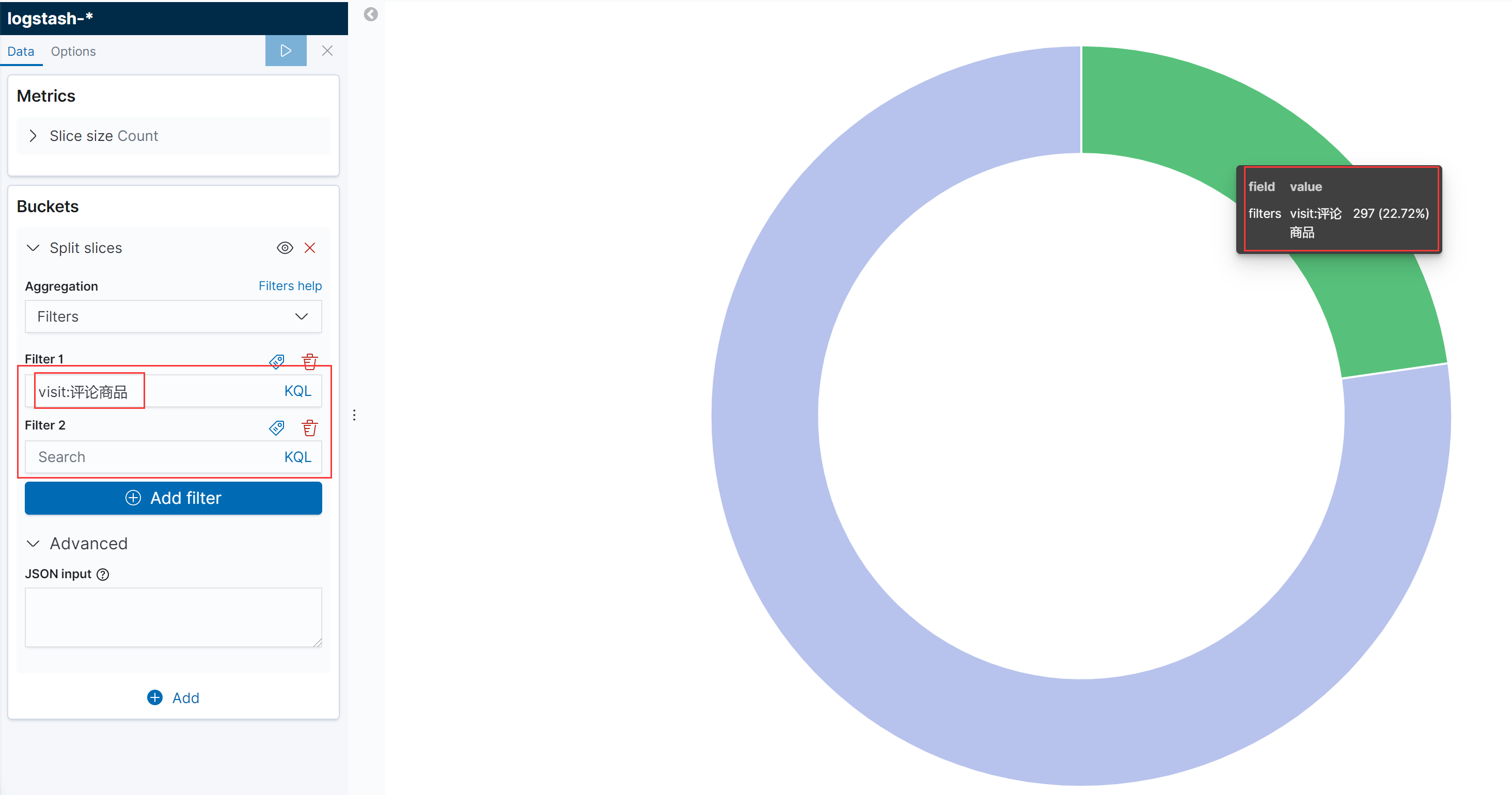
5.4 各个操作的饼图分布
添加一个饼图,依然选择logstash
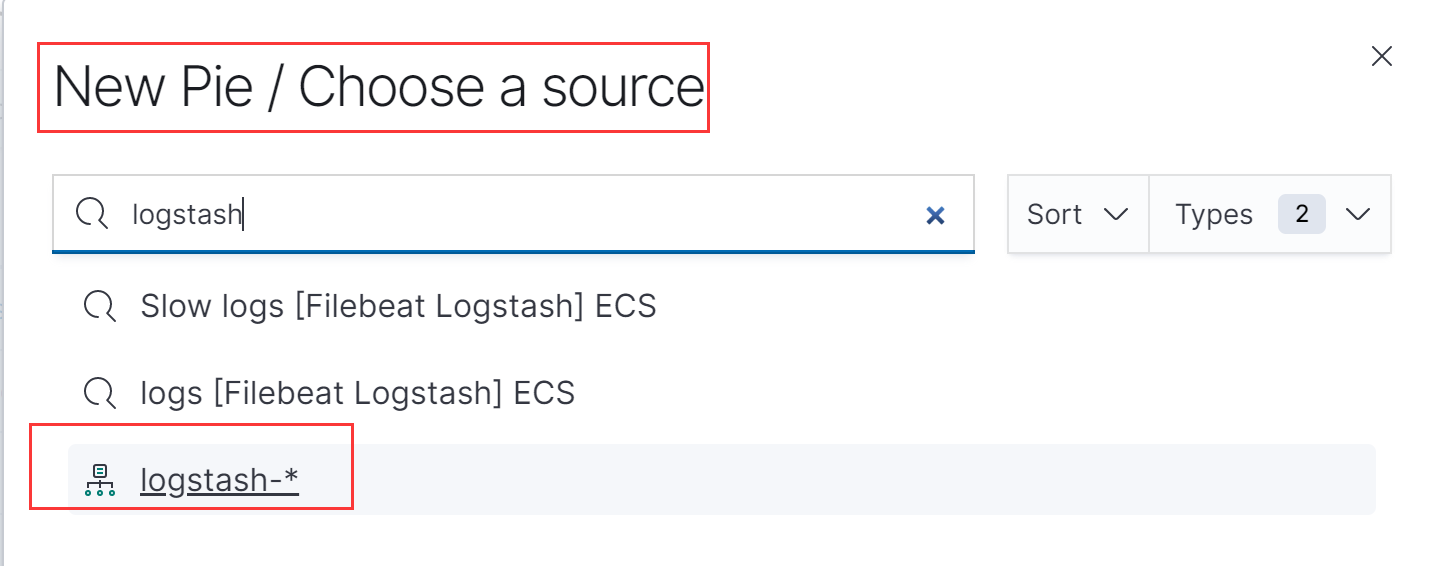

左侧过滤
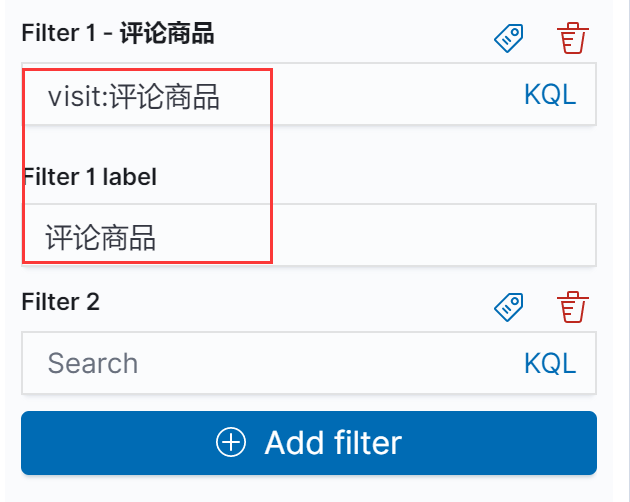
添加一个lable
添加前后显示效果
依次添加所有动作
添加完后效果
设置选项
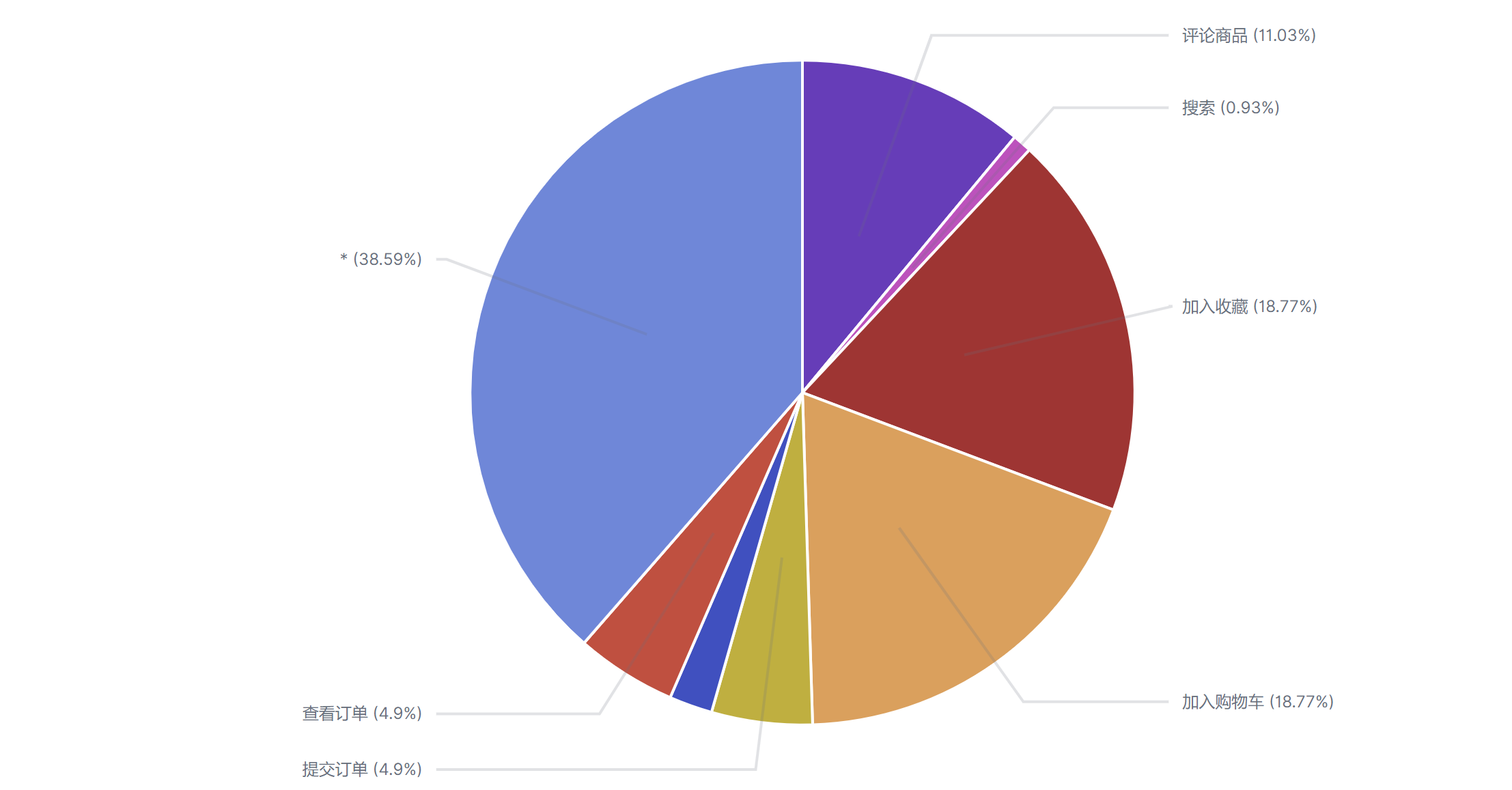
结果如下
保存
5.5 添加一个数据表格
这样显示
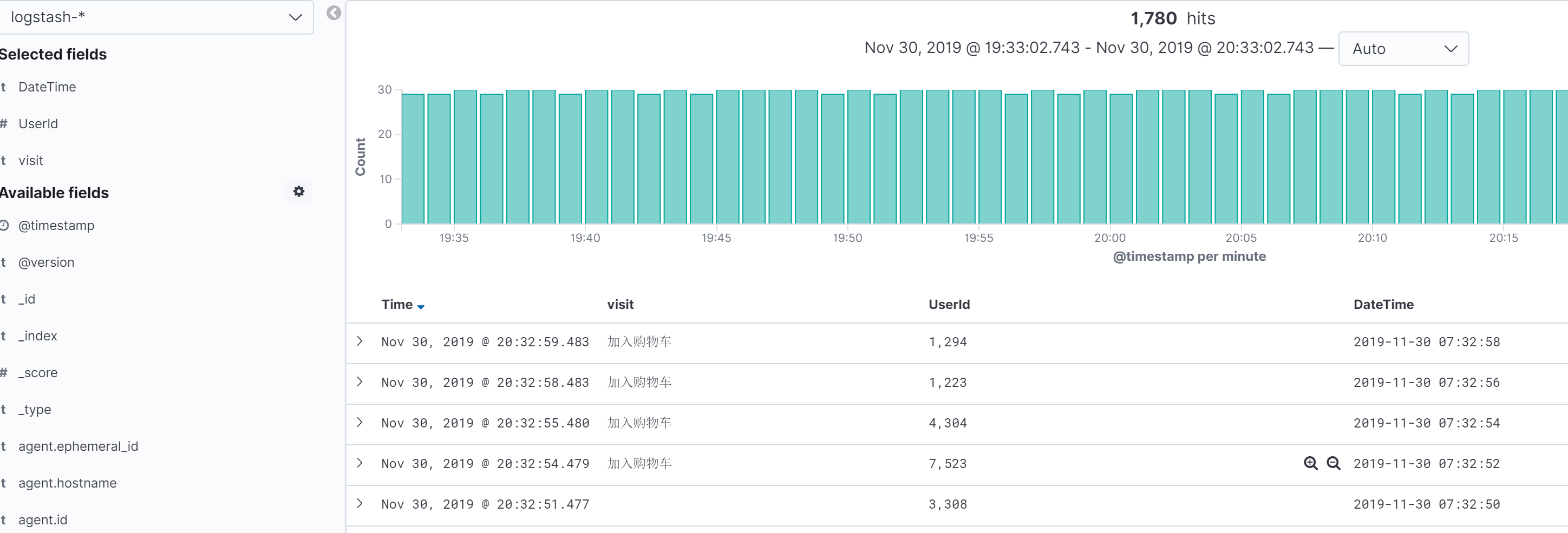
在数据探索中进行保存,将各个操作的数据以表格的形式展示出来
5.6 制作dashboard
创建新的dashboard

调正一下界面。就可以得到下面的界面
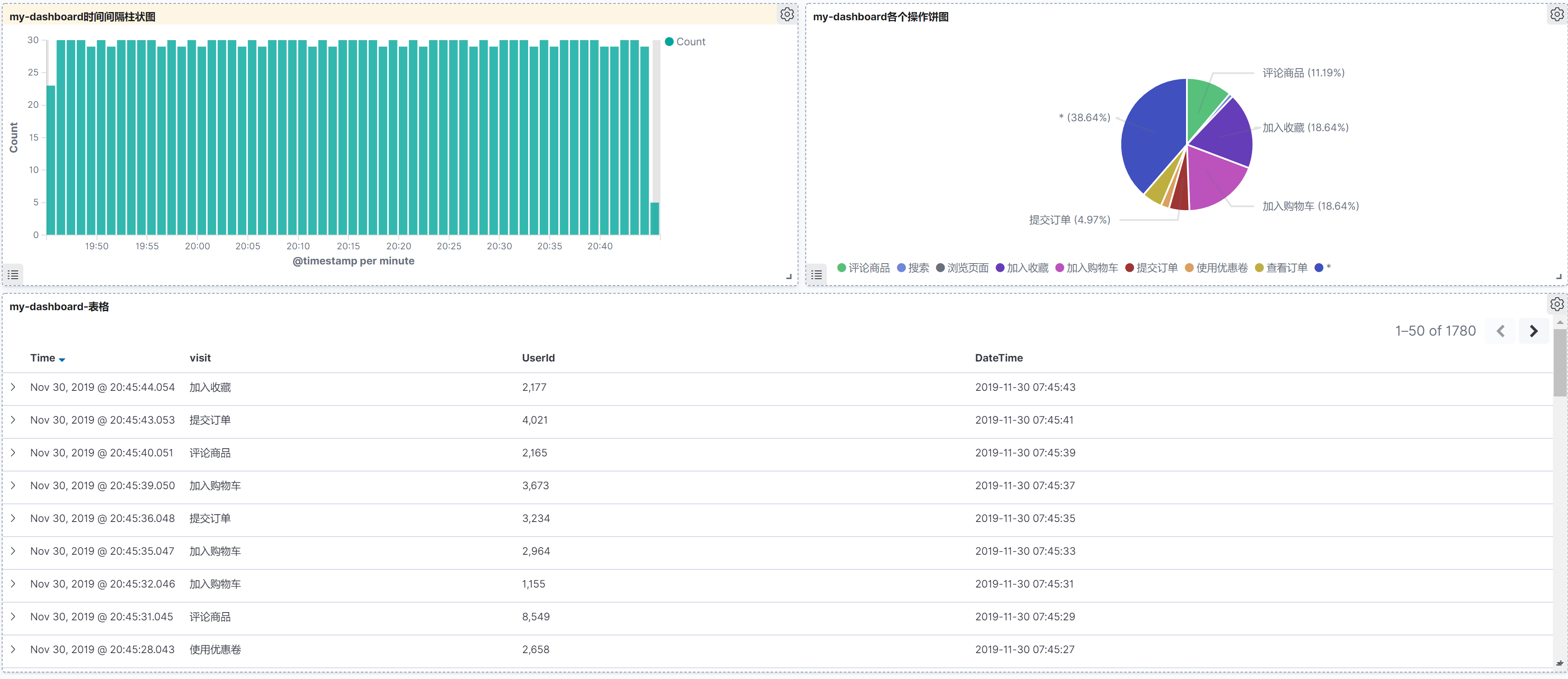
调整名字
5.7 最终结果

保存

整个的实验完成
参考: https://www.bilibili.com/video/av67957955?p=64
ELK学习实验013:ELK的一个完整的配置操作的更多相关文章
- ELK学习实验004:Elasticsearch的简单介绍和操作
一 集群节点 Elstaicsearch的集群是由多个节点组成都,通过cluster.name设置集权名称,比能切用与区分其他的集群,每个节点通过node.name指定节点 在Elasticsearc ...
- ELK学习实验015:日志的自定义index配置
前面使用json格式收集了nginx的日志,但是再index的显示是filebeat-*,现在使用自定义的index进行配置 但是再使用filebeat的7.4版本以后,有一个巨坑,就是按照网络的很多 ...
- ELK学习实验001:Elastic Stack简介
1 背景介绍 在我们日常生活中,我们经常需要回顾以前发生的一些事情:或者,当出现了一些问题的时候,可以从某些地方去查找原因,寻找发生问题的痕迹.无可避免需要用到文字的.图像的等等不同形式的记录.用计算 ...
- ELK学习实验014:Nginx日志JSON格式收集
1 Kibana的显示配置 https://demo.elastic.co/app/kibana#/dashboard/welcome_dashboard 环境先处理干净 安装nginx和httpd- ...
- ELK学习笔记之ELK架构与介绍
0x00 为什么用到ELK 一般我们需要进行日志分析场景:直接在日志文件中 grep.awk 就可以获得自己想要的信息.但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档.文本搜索太 ...
- ELK学习实验002:Elasticsearch介绍及单机安装
一 简介 ElasticSearch是一个基于Luncene的搜索服务器.它提供了一个分布式多用户能力全文搜索引擎,基于RESTful web接口,ElsticSearch使用Java开发的,并作为A ...
- ELK学习实验005:beats的一些工具介绍
一 背景需求 Nginx是一个非常优秀的web服务器,往往Nginx服务会作为项目的访问入口,那么,nginx的性能保障就会变得非常重要,如果nginx的运行出现了问题就会对项目有较大的影响,所以,我 ...
- ELK学习实验012:Logstash的安装和使用
一 logstash安装 1.1下载包 [root@node1 ~]# cd /usr/local/src/ [root@node1 src]# wget https://artifacts.elas ...
- ELK学习实验008:Kibana的介绍
一 简介 Kiana是一款开源的数据分析和可视化平台,它是 Elastic Stack成员之一,设计用于和 Elasticsearch协作.您可以使用 Kiana对 Elasticsearch索引中的 ...
随机推荐
- 字符串分割+二维数组 Day15练习
package com.sxt.arrays.test; import java.util.Arrays; /* 1,2,3,4!5,6,7!8,9!12,456,90!32 * 将此字符串以叹号为分 ...
- spring的父子关系
1.父容器不能拿子容器的资源 2.子容器可以拿到父容器的资源
- H5页面IOS中键盘弹出导致点击错位的问题
IOS在点击输入框弹出键盘 键盘回缩 后 定位没有相应改变 还有 textarea 也会弹出键盘 $("input").blur(function() { console.l ...
- Flask学习之六 个人资料和头像
英文博客地址:http://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-vi-profile-page-and-avatars ...
- Flask学习之三 web表单
本部分Miguel Grinberg教程的翻译地址:http://www.pythondoc.com/flask-mega-tutorial/webforms.html 开源中国的:http://ww ...
- Laravel 下的伪造跨站请求保护 CSRF#
简介# Laravel 可以轻松地保护应用程序免受跨站请求伪造(CSRF) 的攻击.跨站请求伪造是一种恶意的攻击, 他凭借已通过身份验证的用户身份来运行未经过授权的命令. Laravel 会自动为每个 ...
- IDEA中安装activiti并使用
1.IDEA中本身不带activiti,需要自己安装下载. 打开IDEA中File列表下的Settings 输入actiBPM,然后点击下面的Search...搜索 点击Install 下载 下载结束 ...
- set_time_limit(0)是什么意思?
语法 : void set_time_limit (int seconds) 说明 : 设定一个程式所允许执行的秒数,如果到达限制的时间,程式将会传回错误.它预设的限制时间是30秒,max_execu ...
- Python--day61--Django ORM单表操作之展示用户列表
user_list.html views.py 项目的urls.py文件
- centos linux mysql 10060远程错误代码
Navicat for MySQL远程连接数据错误代码10060 1.登陆远程linux服务器命令界面 vim /etc/sysconfig/iptables 进入防火墙配置修改 增加以下两条防火墙 ...