分享知识-快乐自己:Liunx-大数据(Hadoop)初始化环境搭建
大数据初始化环境搭建:
-----------------------------------------------------------------
1):需要准备三个虚拟机环境(创建方式:可以单独创建三个虚拟机:点我查看如何安装虚拟机、也可以通过克隆方式:点我查看克隆详情)
2):NET 网络设置(点我查看网络设置)
3):分别关闭所有虚拟机防火墙
firewall-cmd --state 查看防火墙状态 systemctl stop firewalld.service 临时关闭防火墙(重启后生效) systemctl disable firewalld.service 设置防火墙开机不启动
4):分别修改三台虚拟机的 主机名 与 对应的IP 。分别如下:
主机器: admin 192.168.31.206 子机器:admin-01 192.168.31.207 子机器:admin-02 192.168.31.208 【可根据实际情况,约束 主机名称 与 IP】
例如:修改 admin (参考主机修改方式 修改子机器)
//永久修改主机名称
hostnamectl --static set-hostname admin //修改 hosts 文件
vim /etc/hosts

5):免密登录(分别修改三台虚拟机的 /etc/hosts 文件) 分别加入其它两台虚拟机的 域登录名。

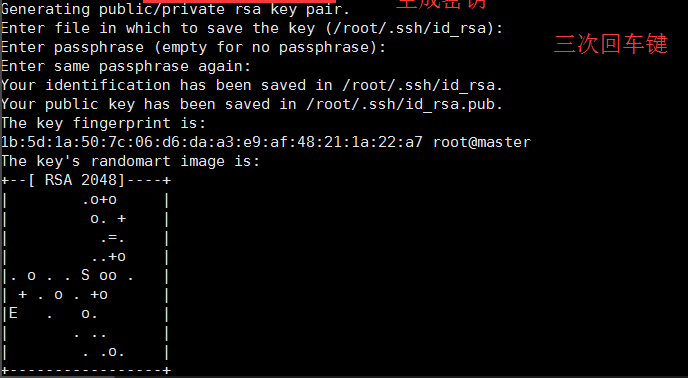
在主机上(admin)生成密钥:
ssh-keygen -t rsa

查看当前目录下的所有文件(包含隐藏文件 .ssh)
ll -a
进入 .ssh 目录:

把本机生成的id_rsa.pub复制到另外两个子机器中,重命名为authorized_keys
//需要先远程创建(.ssh目录)
ssh root@admin-01 "mkdir ~/.ssh/" //将id_rsa.pub进行远程拷贝
scp id_rsa.pub root@admin-01:~/.ssh/authorized_keys //admin-01:为主机名

分别在两个子机器中把authorized_keys 文件的权限改为600:
chmod 600 authorized_keys


在admin节点使用下面命令:(把id_rsa.pub追加到授权的key里面去)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

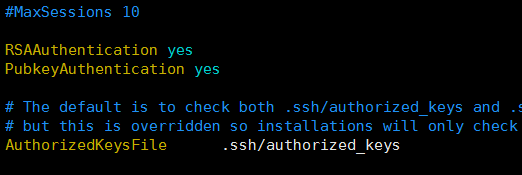
在所有机器上使用下面命令(修改SSH配置文件"/etc/ssh/sshd_config")
vim /etc/ssh/sshd_config RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
6):所有虚拟机安装JDK(点我查看安装步骤)
主机安装成功后可以通过复制操作,拷贝到子机器上(每台虚拟机的路径最好保持一致 方便统一管理)
scp -r /opt/jdk root@admin-01:/opt/jdk scp -r /opt/jdk root@admin-02:/opt/jdk
把 admin 中的profile文件复制到其他两个机器中:
scp /etc/profile root@admin-01:/etc/profile scp /etc/profile root@admin-02:/etc/profile
之后让两个子机器中的profile文件生效,分别在两个子机器中运行:
source /etc/profile
分享知识-快乐自己:Liunx-大数据(Hadoop)初始化环境搭建的更多相关文章
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵. 一.简介 Hadoop的平台搭建,设置为三种搭建方式,第一种是"单节点安装",这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合 ...
- 大数据 --> Hadoop集群搭建
Hadoop集群搭建 1.修改/etc/hosts文件 在每台linux机器上,sudo vim /etc/hosts 编写hosts文件.将主机名和ip地址的映射填写进去.编辑完后,结果如下: 2. ...
- 大数据基础-2-Hadoop-1环境搭建测试
Hadoop环境搭建测试 1 安装软件 1.1 规划目录 /opt [root@host2 ~]# cd /opt [root@host2 opt]# mkdir java [root@host2 o ...
- 入门大数据---Flink开发环境搭建
一.安装 Scala 插件 Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
随机推荐
- openWRT自学---对官方的开发指导文档的解读和理解 记录1:编译一个package
针对的是:http://kamikaze.openwrt.org/docs/openwrt.html#x1-390002 1.If you want, you can also modify the ...
- 一、任天堂ns (Nintendo Switch) 上手
公司不方便回家详解做个博客非专业评测~
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- Yii2实用基础学习笔记(二):Html助手和Request组件 [ 2.0 版本 ]
Html助手 1 .在@app\views\test的index.php中: <?php //引入命名空间 use yii\helpers\Html; ?> <?php //[一]表 ...
- shader一些语义或术语的解释
1.unity内置的摄像机和屏幕参数: 2.unity中一些常用的包含文件: 3.unityCG.cginc中一些常用的结构体: 4.unityCG.cginc中一些常用的帮助函数: 5.从应用阶段传 ...
- C语言基础知识【作用域规则】
C 作用域规则1.任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问.C 语言中有三个地方可以声明变量:在函数或块内部的局部变量在所有函数外部的全局变量在形式参数的函数参 ...
- PHP自动加载功能原理解析
前言 这篇文章是对PHP自动加载功能的一个总结,内容涉及PHP的自动加载功能.PHP的命名空间.PHP的PSR0与PSR4标准等内容. 一.PHP自动加载功能 PHP自动加载功能的由来 在PHP开发过 ...
- [Sdoi2014]数数[数位dp+AC自动机]
3530: [Sdoi2014]数数 Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 834 Solved: 434[Submit][Status][ ...
- 右键打开cmd
Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Directory\shell\OpenCmdHere]@="Open cmd ...
- python login form
import time from selenium import webdriver browser = webdriver.Chrome() wait_time = 1 USER = 'xl.fen ...