分享知识-快乐自己:Liunx-大数据(Hadoop)初始化环境搭建
大数据初始化环境搭建:
-----------------------------------------------------------------
1):需要准备三个虚拟机环境(创建方式:可以单独创建三个虚拟机:点我查看如何安装虚拟机、也可以通过克隆方式:点我查看克隆详情)
2):NET 网络设置(点我查看网络设置)
3):分别关闭所有虚拟机防火墙
firewall-cmd --state 查看防火墙状态 systemctl stop firewalld.service 临时关闭防火墙(重启后生效) systemctl disable firewalld.service 设置防火墙开机不启动
4):分别修改三台虚拟机的 主机名 与 对应的IP 。分别如下:
主机器: admin 192.168.31.206 子机器:admin-01 192.168.31.207 子机器:admin-02 192.168.31.208 【可根据实际情况,约束 主机名称 与 IP】
例如:修改 admin (参考主机修改方式 修改子机器)
//永久修改主机名称
hostnamectl --static set-hostname admin //修改 hosts 文件
vim /etc/hosts

5):免密登录(分别修改三台虚拟机的 /etc/hosts 文件) 分别加入其它两台虚拟机的 域登录名。

在主机上(admin)生成密钥:
ssh-keygen -t rsa

查看当前目录下的所有文件(包含隐藏文件 .ssh)
ll -a
进入 .ssh 目录:

把本机生成的id_rsa.pub复制到另外两个子机器中,重命名为authorized_keys
//需要先远程创建(.ssh目录)
ssh root@admin-01 "mkdir ~/.ssh/" //将id_rsa.pub进行远程拷贝
scp id_rsa.pub root@admin-01:~/.ssh/authorized_keys //admin-01:为主机名

分别在两个子机器中把authorized_keys 文件的权限改为600:
chmod 600 authorized_keys


在admin节点使用下面命令:(把id_rsa.pub追加到授权的key里面去)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

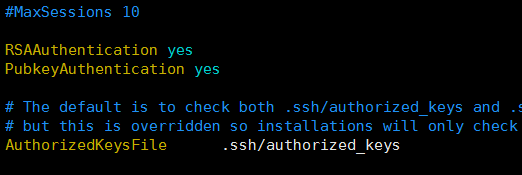
在所有机器上使用下面命令(修改SSH配置文件"/etc/ssh/sshd_config")
vim /etc/ssh/sshd_config RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile .ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
6):所有虚拟机安装JDK(点我查看安装步骤)
主机安装成功后可以通过复制操作,拷贝到子机器上(每台虚拟机的路径最好保持一致 方便统一管理)
scp -r /opt/jdk root@admin-01:/opt/jdk scp -r /opt/jdk root@admin-02:/opt/jdk
把 admin 中的profile文件复制到其他两个机器中:
scp /etc/profile root@admin-01:/etc/profile scp /etc/profile root@admin-02:/etc/profile
之后让两个子机器中的profile文件生效,分别在两个子机器中运行:
source /etc/profile
分享知识-快乐自己:Liunx-大数据(Hadoop)初始化环境搭建的更多相关文章
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建: 一):大数据(hadoop)初始化环境搭建 二):大数据(hadoop)环境搭建 三):运行wordcount案例 四):揭秘HDFS 五):揭秘MapReduce ...
- 大数据Hadoop学习之搭建Hadoop平台(2.1)
关于大数据,一看就懂,一懂就懵. 一.简介 Hadoop的平台搭建,设置为三种搭建方式,第一种是"单节点安装",这种安装方式最为简单,但是并没有展示出Hadoop的技术优势,适合 ...
- 大数据 --> Hadoop集群搭建
Hadoop集群搭建 1.修改/etc/hosts文件 在每台linux机器上,sudo vim /etc/hosts 编写hosts文件.将主机名和ip地址的映射填写进去.编辑完后,结果如下: 2. ...
- 大数据基础-2-Hadoop-1环境搭建测试
Hadoop环境搭建测试 1 安装软件 1.1 规划目录 /opt [root@host2 ~]# cd /opt [root@host2 opt]# mkdir java [root@host2 o ...
- 入门大数据---Flink开发环境搭建
一.安装 Scala 插件 Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala ...
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
随机推荐
- 浏览器登录cookie
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.o ...
- 程序猿学英语—In August the English learning summary
时间真快,总结的7月份英语学习总结刚刚结束,转眼间又该对8月份的英语学习进行小节了. 进入8月初.下发了一个文档,用一个星期的时间学音标.纠音. 在王美的带领下我组也发起了纠音运动. 刚开 始纠音的时 ...
- bugzilla部署记录
这两天部署了个bugzilla,记录如下. 1.主要参考文章 Bugzilla安装过程.Bugzilla使用手册及解决方案 如果你使用的系统是win7或者IIS是7.0的话,你可能还需要Win7 安装 ...
- 【BZOJ1061/3265】[Noi2008]志愿者招募/志愿者招募加强版 单纯形法
[BZOJ1061][Noi2008]志愿者招募 Description 申奥成功后,布布经过不懈努力,终于成为奥组委下属公司人力资源部门的主管.布布刚上任就遇到了一个难题:为即将启动的奥运新项目招募 ...
- K-Piggy-Bank
Piggy-Bank Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total ...
- 记录-springMVC访问web-inf下文件问题+在jsp页面导入jquery插件路径不对问题
环境:spring + springMvc + mybatis + maven 关于在springMVC环境访问web-inf目录下文件,其一有在springMVC xml文件下加 <!-- 对 ...
- openssl将私钥和crt证书合成pfx证书
pfx是什么文件:公钥加密技术12号标准(Public Key Cryptography Standards #12,PKCS#12)为存储和传输用户或服务器私钥.公钥和证书指定了一个可移植的格式.它 ...
- 九度OJ 1251:序列分割 (DFS)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:166 解决:34 题目描述: 一个整数数组,长度为n,将其分为m份,使各份的和相等,求m的最大值 比如{3,2,4,3,6} 可以分成{ ...
- java访问微信接口发送消息
最近在开发activiti流程的时候有个需求:流程到达每个审批节点后,需要向该节点的审批人发送一个消息,提示有审批需要处理. 参考了一下微信的开发者文档和网络上的一些技术博客,现在记录一下.以便后续继 ...
- MySQL的information_schema库
information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式. 什么是元数据呢?元数据是关于数据的数据,如数据库名或表名.列的数据类型,或访问权限.有些时候用于表述该信 ...