Redis 中 HyperLogLog 的使用场景

什么是基数估算
HyperLogLog 是一种基数估算算法。所谓基数估算,就是估算在一批数据中,不重复元素的个数有多少。
从数学上来说,基数估计这个问题的详细描述是:对于一个数据流 {x1,x2,...,xs} 而言,它可能存在重复的元素,用 n 来表示这个数据流的不同元素的个数,并且这个集合可以表示为{e1,...,en}。目标是:使用 m 这个量级的存储单位,可以得到 n 的估计值,其中 m<<n 。并且估计值和实际值 n 的误差是可以控制的。
对于上面这个问题,如果是想得到精确的基数,可以使用字典(dictionary)这一个数据结构。对于新来的元素,可以查看它是否属于这个字典;如果属于这个字典,则整体计数保持不变;如果不属于这个字典,则先把这个元素添加进字典,然后把整体计数增加一。当遍历了这个数据流之后,得到的整体计数就是这个数据流的基数了。
这种算法虽然精准度很高,但是使用的空间复杂度却很高。那么是否存在一些近似的方法,可以估算出数据流的基数呢?HyperLogLog 就是这样一种算法,既可以使用较低的空间复杂度,最后估算出的结果误差又是可以接受的。
HyperLogLog 算法简介
HyperLogLog 算法的基本思想来自伯努利过程。
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
那么如何通过伯努利过程来估算抛了多少次硬币呢?还是假设 1 代表抛出正面,0 代表反面。连续出现两次 0 的序列应该为“001”,那么它出现的概率应该是三个二分之一相乘,即八分之一。那么可以估计大概抛了 8 次硬币。
HyperLogLog 原理思路是通过给定 n 个的元素集合,记录集合中数字的比特串第一个1出现位置的最大值k,也可以理解为统计二进制低位连续为零(前导零)的最大个数。通过k值可以估算集合中不重复元素的数量m,m近似等于 2^k。
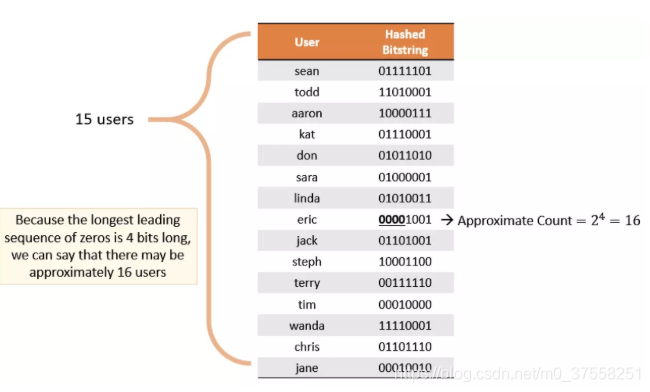
如上图所示,给定一定数量的用户,通过 Hash 算法得到一串 Bitstring,记录其中最大连续零位的计数为 4,User 的不重复个数为 2 ^ 4 = 16。
1. 分桶优化
HyperLogLog 的基本思想是利用集合中数字的比特串第一个 1 出现位置的最大值来预估整体基数,但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog中引入分桶平均的概念,计算 m 个桶的调和平均值。下面公式中的const是一个修正常量。
Redis 中 HyperLogLog 一共分了 2^14 个桶,也就是 16384 个桶。每个桶中是一个 6 bit 的数组,如下图所示。
HyperLogLog 将上文所说的 64 位比特串的低 14 位单独拿出,它的值就对应桶的序号,然后将剩下 50 位中第一次出现 1 的位置值设置到桶中。50位中出现1的位置值最大为50,所以每个桶中的 6 位数组正好可以表示该值。
在设置前,要设置进桶的值是否大于桶中的旧值,如果大于才进行设置,否则不进行设置。示例如下图所示。
在计算近似基数时,就分别计算每个桶中的值,带入到上文将的 DV 公式中,进行调和平均和结果修正,就能得到估算的基数值。
Redis 中的 HyperLogLog
Redis 提供了 PFADD 、 PFCOUNT 和 PFMERGE 三个命令来供用户使用 HyperLogLog。
# 用于向 HyperLogLog 添加元素
# 如果 HyperLogLog 估计的近似基数在 PFADD 命令执行之后出现了变化, 那么命令返回 1 , 否则返回 0
# 如果命令执行时给定的键不存在, 那么程序将先创建一个空的 HyperLogLog 结构, 然后再执行命令
pfadd key value1 [value2 value3]
# PFCOUNT 命令会给出 HyperLogLog 包含的近似基数
# 在计算出基数后, PFCOUNT 会将值存储在 HyperLogLog 中进行缓存,知道下次 PFADD 执行成功前,就都不需要再次进行基数的计算。
pfcount key
# PFMERGE 将多个 HyperLogLog 合并为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的并集基数。
pfmerge destkey key1 key2 [...keyn]
应用场景
HyperLogLog 主要的应用场景就是进行基数统计。这个问题的应用场景其实是十分广泛的。例如:对于 Google 主页面而言,同一个账户可能会访问 Google 主页面多次。于是,在诸多的访问流水中,如何计算出 Google 主页面每天被多少个不同的账户访问过就是一个重要的问题。那么对于 Google 这种访问量巨大的网页而言,其实统计出有十亿 的访问量或者十亿零十万的访问量其实是没有太多的区别的,因此,在这种业务场景下,为了节省成本,其实可以只计算出一个大概的值,而没有必要计算出精准的值。
对于上面的场景,可以使用HashMap、BitMap和HyperLogLog 来解决。对于这三种解决方案,这边做下对比:
HashMap:算法简单,统计精度高,对于少量数据建议使用,但是对于大量的数据会占用很大内存空间;BitMap:位图算法,具体内容可以参考我的这篇文章,统计精度高,虽然内存占用要比HashMap少,但是对于大量数据还是会占用较大内存;HyperLogLog:存在一定误差,占用内存少,稳定占用 12k 左右内存,可以统计 2^64 个元素,对于上面举例的应用场景,建议使用。
参考
- https://mp.weixin.qq.com/s/AvPoG8ZZM8v9lKLyuSYnHQ
- https://blog.csdn.net/m0_37558251/article/details/105436370
Redis 中 HyperLogLog 的使用场景的更多相关文章
- Redis 中 BitMap 的使用场景
BitMap BitMap 原本的含义是用一个比特位来映射某个元素的状态.由于一个比特位只能表示 0 和 1 两种状态,所以 BitMap 能映射的状态有限,但是使用比特位的优势是能大量的节省内存空间 ...
- Redis中5种数据结构的使用场景介绍
转载于:http://www.itxuexiwang.com/a/shujukujishu/redis/2016/0216/108.html?1455861435 一.redis 数据结构使用场景 原 ...
- Redis中7种集合类型应用场景&redis常用命令
Redis常用数据类型 Redis最为常用的数据类型主要有以下五种: String Hash List Set Sorted set 在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部 ...
- Redis中5种数据结构的使用场景
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 ...
- Redis 中 5 种数据结构的使用场景介绍
这篇文章主要介绍了Redis中5种数据结构的使用场景介绍,本文对Redis中的5种数据类型String.Hash.List.Set.Sorted Set做了讲解,需要的朋友可以参考下 一.redis ...
- Redis学习笔记之Redis中5种数据结构的使用场景介绍
原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构 ...
- Redis中3种特殊的数据类型(BitMap、Geo和HyperLogLog)
前言 Reids 在 Web 应用的开发中使用非常广泛,几乎所有的后端技术都会有涉及到 Redis 的使用.Redis 种除了常见的字符串 String.字典 Hash.列表 List.集合 Set. ...
- Redis中7种集合类型应用场景
StringsStrings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字.使用Strings类型,你可以完全实现目前 Memcached 的功能,并且效率更 ...
- Redis在实际项目中的一应用场景
1.在游戏的等级排名,可以将用户信息放入到redis的有序集合中,然后取得相应的排名,不用自己写代码去排序. 2.利用rediss的数据特性的自增,自减属性,可以将项目中的一些列入阅读数,点赞数放入到 ...
随机推荐
- Python之根据四个坐标确定其位于左上下右上下
1.导入模块 import numpy as np 2.存储所需要确定位置的四个坐标点 # 所需要确定位置的四个坐标 coordinate = [[2570, 1948], [2391, 1919], ...
- 按照BNF语法重新写就的JsonAnalyzer2
本例源码:https://files.cnblogs.com/files/heyang78/JsonAnalyzer2-20200525-01.rar 自从按BNF重新书写了算术表达式解析(https ...
- 同样是logback1.11,更换了log配置后,无论是否有线程持续不断写入log文件,log文件会按设定以日期序号轮换
上次发现了logback1.11的一个bug,即有线程持续写入log,则log文件不会按设定模式进行轮换. 但发现同样采用logback1.11的另外一个工程,它的日志文件就没有错误,于是参照其配置文 ...
- Java 序列化界新贵 kryo 和熟悉的“老大哥”,就是 PowerJob 的序列化方案
本文适合有 Java 基础知识的人群 作者:HelloGitHub-Salieri HelloGitHub 推出的<讲解开源项目>系列. 项目地址: https://github.com/ ...
- oracle之DML和DDL语句的其他用法
DML和DDL语句的其他用法 17.1 DML语句-MERGE 作用:把数据从一个表复制到另一个表,插入新数据或替换掉老数据. Oracle 10g中MERGE有如下一些改进: 1.UPDATE或IN ...
- 自然常数e的含义
e是一个重要的常数,但是它的直观含义却不像 π 那么明了.我们都知道,圆的周长与直径之比是一个常数,这个常数被称为圆周率,记作 π = 3.14159......可是e代表什么呢? e是“指数”(ex ...
- 移动端 取消0.3ms的延迟 两种方案解决
在index.html中添加一下代码 <script src="https://as.alipayobjects.com/g/component/fastclick/1.0.6/fas ...
- 为什么阿里巴巴禁止使用BigDecimal的equals方法做等值比较?
GitHub 17k Star 的Java工程师成神之路,不来了解一下吗! GitHub 17k Star 的Java工程师成神之路,真的不来了解一下吗! GitHub 17k Star 的Java工 ...
- 跟我一起学.NetCore之路由的最佳实现
前言 路由,这词绝对不陌生,不管在前端还是后端都经常提到,而这节不说其他,就聊.NetCore的路由:在之前的Asp.Net MVC 中,路由算是面试时必问的考点,可见其重要性,它的主要作用是映射UR ...
- session深入探讨
简介 session(会话),其实是一个容易让人误解的词.它总跟web系统的会话挂钩,利用session,javaweb项目实现了登录状态的控制.坊间流传,关闭浏览器,就是关闭了web系统的会话. 其 ...