MySQL之谓词下推
MySQL之谓词下推
什么是谓词
在SQL中,谓词就是返回boolean值即true或者false的函数,或是隐式转换为boolean的函数。SQL中的谓词主要有 LKIE、BETWEEN、IS NULL、IS NOT NULL、IN、EXISTS
谓词下推的基本思想即:
将过滤表达式尽可能移动至靠近数据源的位置,以使真正执行时能直接跳过无关的数据。
传统数据库中的谓词下推:
在传统数据库的查询系统中谓词下推作为优化手段很早就出现了,谓词下推的目的就是通过将一些过滤条件尽可能的在最底层执行可以减少每一层交互的数据量,从而提升性能。例如下面这个例子:
select count(1) from A Join B on A.id = B.id where A.a > 10 and B.b < 100;
在处理Join操作之前需要首先对A和B执行TableScan操作,然后再进行Join,再执行过滤,最后计算聚合函数返回,但是如果把过滤条件A.a > 10和B.b < 100分别移到A表的TableScan和B表的TableScan的时候执行,可以大大降低Join操作的输入数据。优化后的语句如下:
select count(1) from (select * from A where a>10)A1 Join (select * from B where b<100)B1 on A1.id = B1.id;
无论是行式存储还是列式存储,都可以在将过滤条件在读取一条记录之后执行以判断该记录是否需要返回给调用者,在Parquet做了更进一步的优化,优化的方法时对每一个Row Group的每一个Column Chunk在存储的时候都计算对应的统计信息,包括该Column Chunk的最大值、最小值和空值个数。通过这些统计值和该列的过滤条件可以判断该Row Group是否需要扫描。另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推。
在使用Parquet的时候可以通过如下两种策略提升查询性能:
1、类似于关系数据库的主键,对需要频繁过滤的列设置为有序的,这样在导入数据的时候会根据该列的顺序存储数据,这样可以最大化的利用最大值、最小值实现谓词下推。
2、减小行组大小和页大小,这样增加跳过整个行组的可能性,但是此时需要权衡由于压缩和编码效率下降带来的I/O负载。
列式存储中的谓词下推思想
RF算法中,用了谓词下推思想。大小表进行broadcast hash join时,用小表的join列数据构建BloomFilter,广播到大表的所有partition,使用该BloomFilter对大表join列数据进行过滤。最后将大表过滤后得到的数据与小表数据进行hashJoin。
这个过程如下图:
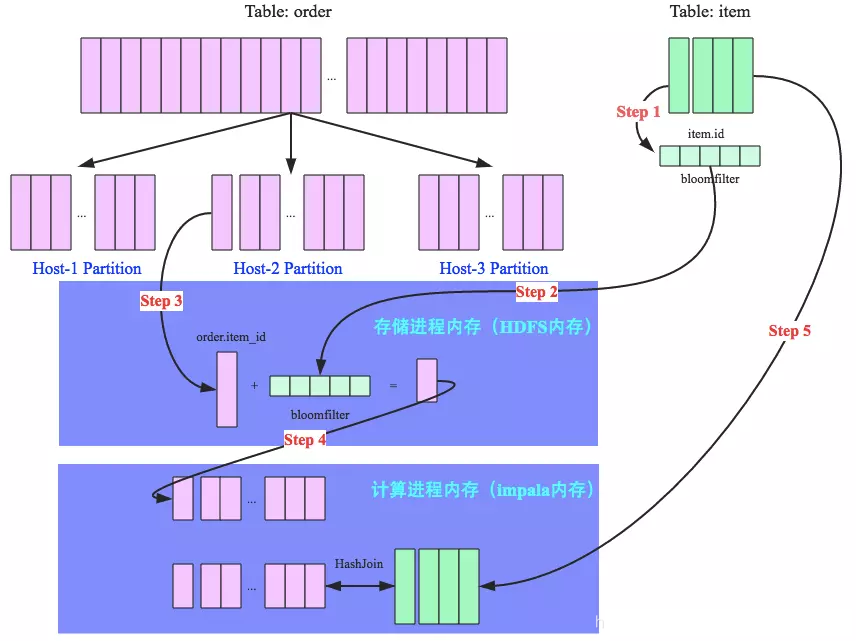
这样的好处是:
- 在存储层即过滤了大量大表无效数据,减少扫描无效数据列的同行其他列数据IO
- 减少存储进程到计算进程传输的数据
- 减少hashjoin开销
如这个SQL:
select item.name, order.* from order , item where order.item_id = item.id and item.category = ‘book’
使用谓词下推,会将表达式 item.category = ‘book’下推到join条件order.item_id = item.id之前。再往高大上的方面说,就是将过滤表达式下推到存储层直接过滤数据,减少传输到计算层的数据量。
HIVE中的谓词下推(下推规则同样适用于SparkSQL)
Hive中的Predicate Pushdown简称谓词下推,简而言之,就是在不影响结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
具体配置项是hive.optimize.ppd,默认为true,即开启谓词下推
PPD规则:
规则的逻辑描述如下:
- During Join predicates cannot be pushed past Preserved Row tables.
join条件过滤不能下推到保留行表中。
比如以下选择,left join中左表s1为保留行表,所以on条件(join过滤条件)不能下推到s1中
select s1.key, s2.key from src s1 left join src s2 on s1.key > '2';
而s2表不是保留行,所以s2.key>2条件可以下推到s2表中:
select s1.key, s2.key from src s1 left join src s2 on s2.key > '2';
- After Join predicates cannot be pushed past Null Supplying tables.
where条件过滤不能下推到NULL补充表。
比如以下选择left join的右表s2为NULL补充表所以,s1.key>2 where条件可以下推到s1:
select s1.key, s2.key from src s1 left join src s2 where s1.key > '2';
而以下选择由于s2未NULL补充表所以s2.key>2过滤条件不能下推
select s1.key, s2.key from src s1 left join src s2 where s2.key > '2';
关于join和where采用ppd的规则如下:

1、对于Join(Inner Join)、Full outer Join,条件写在on后面,还是where后面,性能上面没有区别;
2、对于Left outer Join ,右侧的表写在on后面、左侧的表写在where后面,性能上有提高;
3、对于Right outer Join,左侧的表写在on后面、右侧的表写在where后面,性能上有提高;
4、所谓下推,即谓词过滤在map端执行;所谓不下推,即谓词过滤在reduce端执行
注意:如果在表达式中含有不确定函数,整个表达式的谓词将不会被pushed,例如
select a.* from a join b on a.id = b.idwhere a.ds = '2019-10-09' and a.create_time = unix_timestamp();
因为unix_timestamp是不确定函数,在编译的时候无法得知,所以,整个表达式不会被pushed,即ds='2019-10-09'也不会被提前过滤。类似的不确定函数还有rand()等。
MySQL之谓词下推的更多相关文章
- Spark之谓词下推
谓词下推就是指将各个条件先应用到对应的数据上,而不是根据写入的顺序执行,这样就可以先过滤掉部分数据,降低join等一系列操作的数据量级,提高运算速度,如下图:
- BigData – Join中竟然也有谓词下推!?
本文由 网易云发布. 在之前的文章中简要介绍了Join在大数据领域中的使用背景以及常用的几种算法-broadcast hash join .shuffle hash join以及 sort merg ...
- Hive优化之谓词下推
Hive优化之谓词下推 解释 Hive谓词下推(Predicate pushdown) 关系型数据库借鉴而来,关系型数据中谓词下推到外部数据库用以减少数据传输 基本思想:尽可能早的处理表达式 属于逻辑 ...
- 【大数据】SparkSql 连接查询中的谓词下推处理 (二)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/II48YxGfoursKVvdAXYbVg作者:李勇 目录:1.左表 join 后条件下推2.左表j ...
- 【大数据】SparkSql 连接查询中的谓词下推处理 (一)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/YPN85WBNcnhk8xKjTPTa2g 作者:李勇 目录: 1.SparkSql 2.连接查询和 ...
- 大数据SQL中的Join谓词下推,真的那么难懂?
听到谓词下推这个词,是不是觉得很高大上,找点资料看了半天才能搞懂概念和思想,借这个机会好好学习一下吧. 引用范欣欣大佬的博客中写道,以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白 ...
- Mysql中谓词使用date_format的优化
优化前: SELECT a.* FROM t1 a, (SELECT obj_id,MAX(PRE_DETAIL_INST_ID) PRE_DETAIL_INST_ID FROM t1 WHERE D ...
- spark教程(19)-sparkSQL 性能优化之谓词下推
在 sql 语言中,where 表示的是过滤,这部分语句被 sql 层解析后,在数据库内部以谓词的形式出现: 在 sparkSQL 中,如果出现 where,它会现在数据库层面进行过滤,一般数据库会有 ...
- MySQL调优之索引优化
一.索引基本知识 1.索引的优点 1.减少了服务器需要扫描的数据量 2.帮助服务器避免排序和临时表 例子: select * from emp orde by sal desc; 那么执行顺序: 所以 ...
随机推荐
- 前中后序递归遍历树的体会 with Python
前序:跟->左->右 中序:左->根->右 后序:左>右->根 采用递归遍历时,编译器/解释器负责将递归函数调用过程压入栈并保护现场,在不同位置处理根节点即可实现不 ...
- Java与C#
Java和C#都是编程的语言,它们是两个不同方向的两种语言 相同点: 他们都是面向对象的语言,也就是说,它们都能实现面向对象的思想(封装,继承,多态) 区别: 1.c#中的命名空间是namespace ...
- 微信小程序--每周图书推荐
这是我个人的第一个原生微信小程序,作为一枚萌新,自己没有前端经历,所以代码很混乱,界面很简单,难度也很低,主要用来记录自己学小程序过程中遇到的问题. 一. 先上预览图 左右滑动切换每周推荐的图书,点击 ...
- WIN10系统下静态编译Qt4.8.7
qt-everywhere-opensource-src-4.8.7.tar.gz http://download.qt.io/archive/qt/4.8/4.8.7/qt-everywhere- ...
- Layui关闭弹出层对话框--刷新父界面
在毕设的开发中,添加用户.添加权限等等一些地方需要类似于bootstrap中的模态框.然而开发用的却是layui 在layui中有弹出层可以实现其中的效果. 但是,一般用的时候都是提交后关闭窗口,刷新 ...
- 翻译 | 30个 Python3 的最佳实践,技巧和窍门
1.使用 Python3 如果你关注 Python 的话,应该会知道 Python 2 已经于今年(2020 年)1 月 1 日正式弃用了.这份教程的很多例子都是只支持 Python 3 的,如果你还 ...
- jQuery中toggle与slideToggle以及fadeToggle的显示、隐藏方法的比较
1.区别 ①动画效果的比较: toggle:直接显示.隐藏,如果有[时间参数]且[匹配的元素有宽度属性],则动态效果为左上角-右下角拉卷效果,透明度0-1之间的变化:若有时间参数但是[匹配的元素没有宽 ...
- Java实现RS485串口通信
前言 前段时间赶项目的过程中,遇到一个调用RS485串口通信的需求,赶完项目因为楼主处理私事,没来得及完成文章的更新,现在终于可以整理一下当时的demo,记录下来. 首先说一下大概需求:这个项目是机器 ...
- 解决Tengine健康检查引起的TIME_WAIT堆积问题
简介: 解决Tengine健康检查引起的TIME_WAIT堆积问题 一. 问题背景 "服务上云后,我们的TCP端口基本上都处于TIME_WAIT的状态"."这个问题在线下 ...
- Rabbitmq可靠消息投递,消息确认机制
前言 我们知道,消息从发送到签收的整个过程是 Producer-->Broker/Exchange-->Broker/Queue-->Consumer,因此如果只是要保证消息的可靠投 ...