为什么堆化 heapify() 只用 O(n) 就做到了?
heapify()
前面两篇文章介绍了什么是堆以及堆的两个基本操作,但其实呢,堆还有一个大名鼎鼎的非常重要的操作,就是 heapify() 了,它是一个很神奇的操作,
可以用 O(n) 的时间把一个乱序的数组变成一个 heap。
但是呢,heapify() 并不是一个 public API,看:

所以我们没有办法直接使用。
唯一使用 heapify() 的方式呢,就是使用
PriorityQueue(Collection<? extends E> c)
这个 constructor 的时候,人家会自动调用 heapify() 这个操作。
那具体是怎么做的呢?
哈哈源码已经暴露了:
从最后一个非叶子节点开始,从后往前做 siftDown().
因为叶子节点没必要操作嘛,已经到了最下面了,还能和谁 swap?
举个例子:
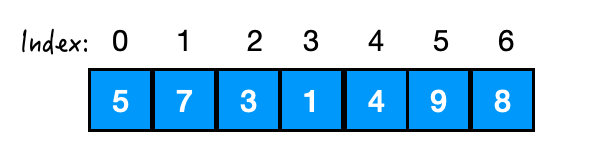
我们想把这个数组进行 heapify() 操作,想把它变成一个最小堆,拿到它的最小值。
那就要从 3 开始,对 3,7,5进行 siftDown().
Step 1.
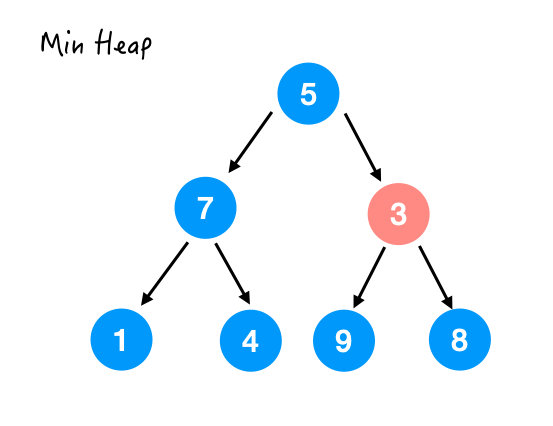
尴尬 ,3 并不用交换,因为以它为顶点的这棵小树已经满足了堆序性。
Step 2.

7 比它的两个孩子都要大,所以和较小的那个交换一下。
交换完成后;
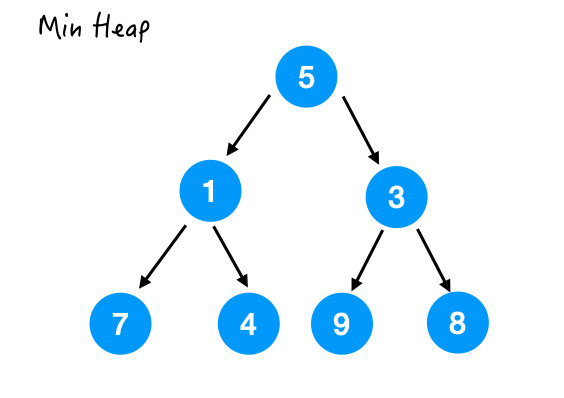
Step 3.
最后一个要处理的就是 5 了,那这里 5 比它的两个孩子都要大,所以也和较小的那个交换一下。
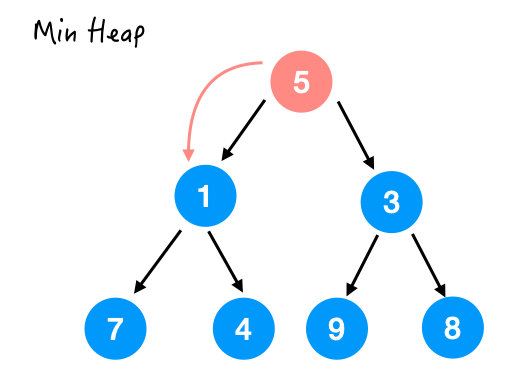
换完之后结果如下,注意并没有满足堆序性,因为 4 还比 5 小呢。
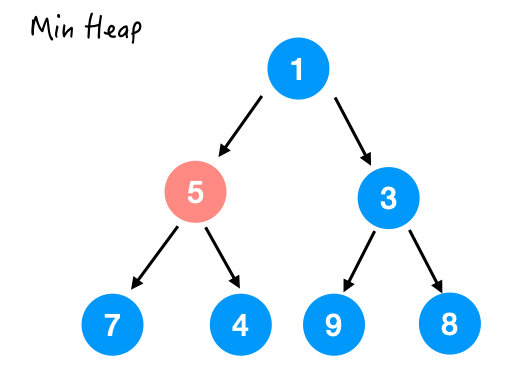
所以接着和 4 换,结果如下:
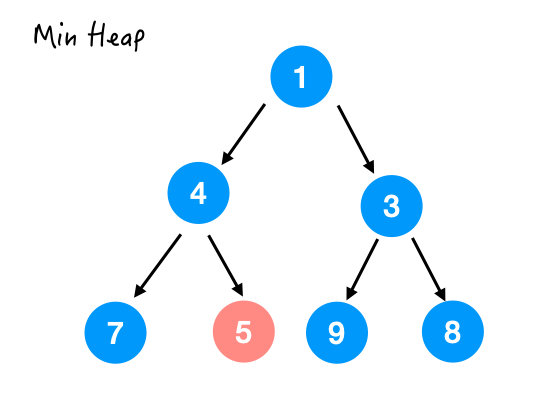
这样整个 heapify() 的过程就完成了。
好了难点来了,为什么时间复杂度是 O(n) 的呢?
怎么计算这个时间复杂度呢?
其实我们在这个过程里做的操作无非就是交换交换。
那到底交换了多少次呢?
没错,交换了多少次,时间复杂度就是多少。
那我们可以看出来,其实同一层的节点最多交换的次数都是相同的。
那么这个总的交换次数 = 每层的节点数 * 每个节点最多交换的次数
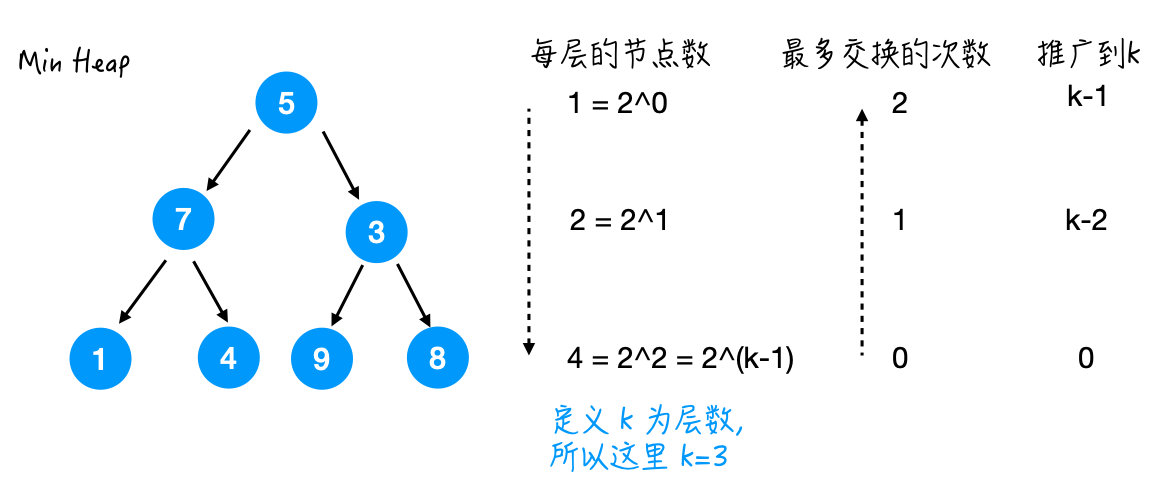
这里设 k 为层数,那么这个例子里 k=3.
每层的节点数是从上到下以指数增长:
$$\ce{1, 2, 4, ..., 2^{k-1}}$$
每个节点交换的次数,
从下往上就是:
$$ 0, 1, ..., k-2, k-1 $$
那么总的交换次数 S(k) 就是两者相乘再相加:
$$S(k) = \left(2^{0} *(k-1) + 2^{1} *(k-2) + ... + 2^{k-2} *1 \right)$$
这是一个等比等差数列,标准的求和方式就是错位相减法。
那么
$$2S(k) = \left(2^{1} *(k-1) + 2^{2} *(k-2) + ... + 2^{k-1} *1 \right)$$
两者相减得:
$$S(k) = \left(-2^{0} *(k-1) + 2^{1} + 2^{2} + ... + 2^{k-2} + 2^{k-1} \right)$$
化简一下:
(不好意思我实在受不了这个编辑器了。。。
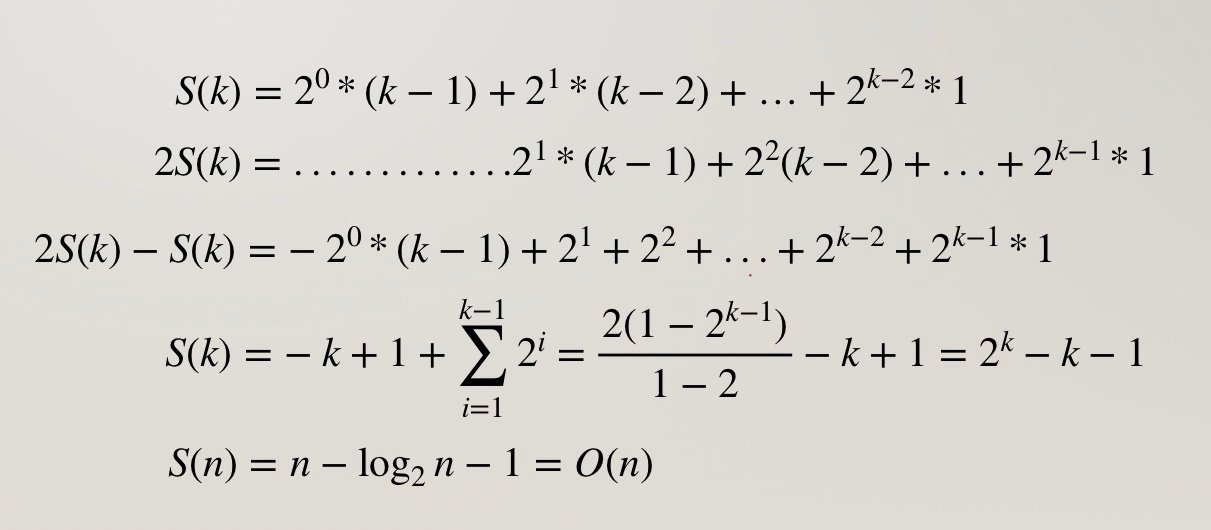
所以 heapify() 时间复杂度是 O(n).
以上就是堆的三大重要操作,最后一个 heapify() 虽然不能直接操作,但是堆排序中用到了这种思路,之前的「选择排序」那篇文章里也提到了一些,感兴趣的同学可以后台回复「选择排序」获得文章~至于堆排序的具体实现和应用,以及为什么实际生产中并不爱用它,我们之后再讲。
如果你喜欢这篇文章,记得给我点赞留言哦~你们的支持和认可,就是我创作的最大动力,我们下篇文章见!
我是小齐,纽约程序媛,终生学习者,每天晚上 9 点,云自习室里不见不散!
更多干货文章见我的 Github: https://github.com/xiaoqi6666/NYCSDE
为什么堆化 heapify() 只用 O(n) 就做到了?的更多相关文章
- lintcode: 堆化
堆化 给出一个整数数组,堆化操作就是把它变成一个最小堆数组. 对于堆数组A,A[0]是堆的根,并对于每个A[i],A [i * 2 + 1]是A[i]的左儿子并且A[i * 2 + 2]是A[i]的右 ...
- Java实现的二叉堆以及堆排序详解
一.前言 二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1.二叉堆类型分为最大堆( ...
- Java并发包源码学习系列:阻塞队列实现之PriorityBlockingQueue源码解析
目录 PriorityBlockingQueue概述 类图结构及重要字段 什么是二叉堆 堆的基本操作 向上调整void up(int u) 向下调整void down(int u) 构造器 扩容方法t ...
- Java数据结构和算法(五)二叉排序树(BST)
Java数据结构和算法(五)二叉排序树(BST) 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 二叉排序树(Binary S ...
- Java同步数据结构之PriorityBlockingQueue
前言 接下来继续BlockingQueue的另一个实现,优先级阻塞队列PriorityBlockingQueue.PriorityBlockingQueue是一个无限容量的阻塞队列,由于容量是无限的所 ...
- 两种建立堆的方法HeapInsert & Heapify
参考 堆排序中两种建堆方法的比较 第一种方法HeapInsert 它可以假定我们事先不知道有多少个元素,通过不断往堆里面插入元素进行调整来构建堆. 它的大致步骤如下: 首先增加堆的长度,在最末尾的地方 ...
- 索引堆(Index Heap)
首先我们先来看一个由普通数组构建的普通堆. 然后我们通过前面的方法对它进行堆化(heapify),将其构建为最大堆. 结果是这样的: 对于我们所关心的这个数组而言,数组中的元素位置发生了改变.正是因为 ...
- lintcode-130-堆化
130-堆化 给出一个整数数组,堆化操作就是把它变成一个最小堆数组. 对于堆数组A,A[0]是堆的根,并对于每个A[i],A [i * 2 + 1]是A[i]的左儿子并且A[i * 2 + 2]是A[ ...
- 数据结构中的堆(Heap)
堆排序总结 这是排序,不是查找!!!查找去找二叉排序树等. 满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树. 构建顶堆: a.构造初始堆 b.从最后一层非叶节点开始调整,一直到根节点 c.如果 ...
随机推荐
- Robotframework自动化7-数据库连接
一.连接mysql数据库 1.安装pymysql: pip install pymysql pip install robotframework-databaselibrary 导入库Datab ...
- PHP之道(PHP The Right Way)
原文地址:http://laravel-china.github.io/php-the-right-way/
- 使用PXE+VNC方式安装CentOS 7
U盘坏了,用个下面的方法安装 安装配置dhcp yum -y install dhcp tftp-server 修改如下,网段改为你自己的网段 vim /etc/dhcp/dhcpd.conf sub ...
- Docker实战(1):通过配置文件启动MongoDB
系统环境:Centos7 MongoDB 4.0.0 创建文件 注意:创建文件全是为了Docker run做准备,文件所对应的路径需与下一步的映射路径所对应,路径可自我更改. mkdir mongo ...
- firewalld 防火墙
firewalld防火墙 firewalld简述 firewalld:防火墙,其实就是一个隔离工具:工作于主机或者网络的边缘对于进出本主机或者网络的报文根据事先定义好的网络规则做匹配检测,对于能够 ...
- 分享一些好用的 Chrome 插件!
使用浏览器扩展程序可以使你的工作效率提高数倍不止,那么下面我就向大家分享一下我日常使用的扩展,可能大多数扩展大家都已经在使用了,不过也难免有一两个是你不知道的. 以下排名并不分先后,请坚持看到最后,或 ...
- 刷题[CISCN2019 华北赛区 Day2 Web1]Hack World
解题思路 打开发现是很简单的页面,告诉了表名和列名,只需知道字段即可 尝试一下,输入1,2都有内容,后面无内容.输入1'让他报错,发现返回bool(false) 大概思路就是布尔型注入了,通过不断返回 ...
- SSH 框架常见错误
新手学习SSH框架的时候总会遇到很多问题,一碰到404 或者500错误就不知道怎么解决. 404错误是很常见的一个错误,如果没有用框架基本上只可能是没有这个路径或者文件,但是用了框架之后404的原因就 ...
- 吴恩达Machine Learning学习笔记(二)--多变量线性回归
回归任务 多变量线性回归 公式 h为假设,theta为模型参数(代表了特征的权重),x为特征的值 参数更新 梯度下降算法 影响梯度下降算法的因素 (1)加速梯度下降:通过让每一个输入值大致在相同的范围 ...
- Presto 标量函数注册和调用过程简述
在Presto 函数开发一文中已经介绍过如何进行函数开发,本文主要讲述标量函数(Scalar Function)实现之后,是如何在Presto内部进行注册和被调用的.主要讲述标量函数是因为:三类函数的 ...