Python基础及爬虫入门
**写在前面**
我们在学习任何一门技术的时候,往往都会看很多技术博客,很多程序员也会写自己的技术博客。但是我想写的这些不是纯技术博客,我暂时也没有这个能力写出 Python 或者爬虫相关的技术博客来。我只是作为一个初学 Python 和爬虫的产品,把我学习的过程和心得记录下来,供大家参考。
我会给到我在学习过程中参考的技术博客链接,在此也对他们的无私奉献表示感谢。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
**Python 基础
先来点开胃菜**
可能对于很多人来说, Python 最大的特点就是“简短”。那么用Python 写程序到底有多短呢?举个栗子~
我有两个室友,一个前端,一个后台。他们分别用 JavaScript 和 C# 实现下面这个功能,需要多少行代码呢?
输出 (0:100)之间的,【1X1, 2X2 ··· 100X100】中 2 的倍数
JavaScript 用了10行,C# 用了5行 (当然,这也跟他们当时的技术水平有关。一般来说,用任何语言实现这个功能应该都不需要10行代码)
那么用 Python 呢?只需要一行

Python 代码简短明确,相对来说比较好入门,适合在课余和工作之余 的时间去学习,所以大家不用担心自己没有时间。
PS. 我无意比较各语言的好坏,我知道 C、C++ 的运行效率比 Python 高很多,我也相信有大牛能够通过其他语言只用一行代码来实现。在此只是简述 Python 简短易入门。
**Python 版本**
如果你有百度过 Python,那么你应该知道,Python 目前有两个主要的版本: Python 2.7.X 和 Python 3.3.X,而且这两者是不完全兼容的。
目前来说,Python 2.X 的教程和库更多,更好学。但 Python 3.X 更先进,而且解决了 Python 2.X 在使用中文的时候容易出现的编码错误问题。
这里不评价哪个版本更好,但是我目前用的是 Python 2.7,因此这里所说的所有博客、教程、语法和库···都是基于 Python 2.7
**开始学习吧**
我在学习 Python 基础的时候主要参考了 Python 教程 ,他的博客通俗易懂,在“技术博客界”也比较出名。
但是这个教程几乎涵盖了 Python 的所有知识教程,如果只是需要用 Python 写一个爬虫或者其他小脚本的话,实际上是不需要全部看完的(当然如果你愿意也可以)。如果你有其他语言的基础,那么可以只看个大概,了解一些基本的语法和特性就行了;如果你没有其他语言的基础,甚至对编程一窍不通,那么建议你多学习一些,最好看到“错误、调试和测试”那一章,并且一定要把其中每一篇的示例代码放到自己的编译器里跑一遍(不要复制,自己敲),这样才能理解其中的一些原理。
我大学的专业是软件工程,因此有一定的 C++ 基础。我大概只看到“高级特性”那一章,然后就开始学习爬虫了。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
**爬虫入门**
网络爬虫(又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。——百度百科
**网页知识简介**
一般来说,爬虫获取的是网页上的内容。我们通过浏览器上网时,首先会对该网站的服务器发送一个访问请求,服务器收到请求后,把我们需要的数据传回来给到浏览器,然后浏览器解析数据并展现给我们。
而这些数据在被浏览器解析之前,其实就是一些代码。我们在浏览器页面按一下F12,就能看到该网址的源代码。
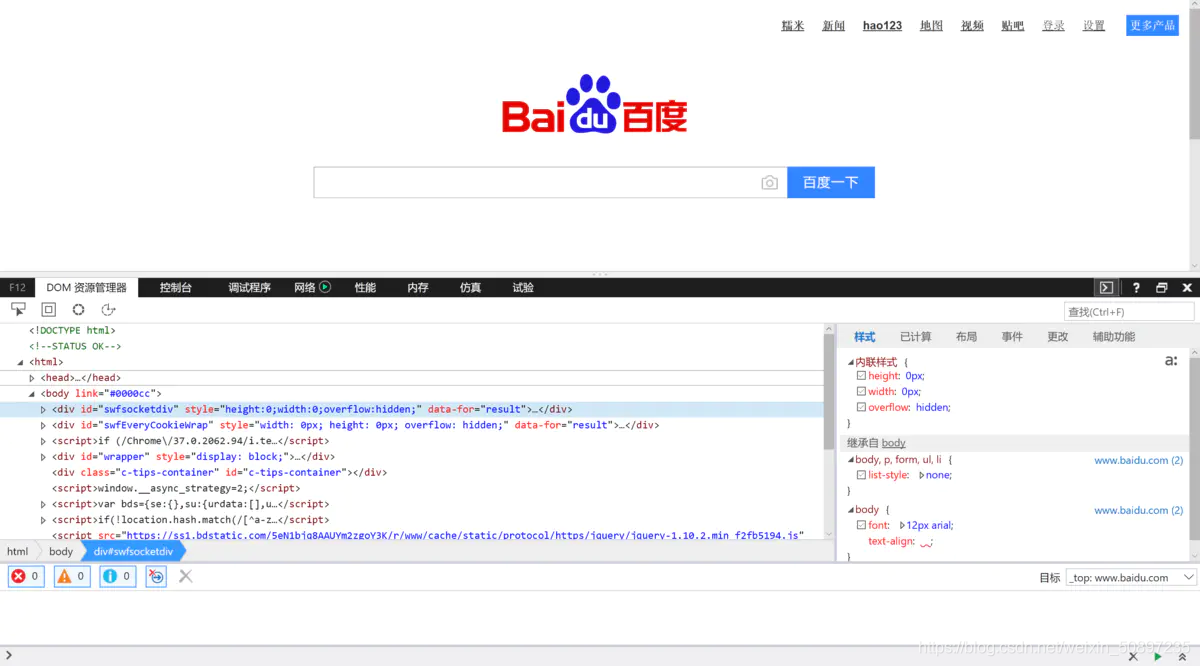
**爬虫原理简介**
如果没有前端基础,那么我们可能完全看不懂这些源代码。但是,我们通过浏览器看到的文字、图片等信息,其实也包含在源代码里。
比如这个页面的部分文字和图片:
其中包含文字和图片的代码是这样的

也就是说,只要我们爬到了网页的源代码,那么这个网页展示出来的(甚至隐藏掉的)所有信息,我们只要从源码中筛选就能够获取。
所以一般爬虫的原理其实非常简单:
爬取源码
筛选信息
如何获取源代码
我们访问网页一般都是通过浏览器,而浏览器其实也就是一个程序而已。相应的,爬虫其实也是一个程序。
因此爬虫程序(脚本)其实就是把自己伪装成一个浏览器,然后跟浏览器一样向目标网页的服务器发送访问请求,只要骗过了服务器,那么服务器就会把源码返回给你,这样你就获得该网页的源代码了。
PS. 上面指的网页都是静态网页,不包括动态内容;源代码也只是 HTML 代码,不包括 JS 代码。爬取动态内容要更为复杂一些
API
如果你是一个互联网从业者,那么应该听过 API 这个词。
API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,而又无需访问源码,或理解内部工作机制的细节。——百度百科
简单来说,你可以把 API 当做一个管道接口,当你连接上这个管道接口后,你就能从中获取一些数据信息(当然,你能获取哪些信息是它说了算)。
很多企业都会对外开放一些 API 接口,通过这些接口,我们能更为快速、高效、便捷地获取天气、航班、股市等信息。(不只是这些公共信息,其实像 QQ、微博、facebook 等都会开放一些 API 接口,这样能让公司的业务更好地渗透到市场中去,也利于业务之间的合作)
显然,我们也可以通过爬虫程序来连接这些 API 接口,以此来获取数据信息。
开始学习吧
我在学习爬虫的过程中主要参考的是Python爬虫学习系列教程 ,他主要分了4个学习阶段。按照这个教程一步一步的实践,很快你就能收获一些成果了。
我创了一个 python交流群,有感兴趣的小伙伴也可以加我的扣扣群867零67久45,群里有专门的老师跟资料可以提供给小伙伴们学习python,晚上8点也有老师直播教小伙伴们怎么学习python,欢迎大家加入python这个大家庭。
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
Python基础及爬虫入门的更多相关文章
- 入门python有什么好的书籍推荐?纯干货推荐,你值得一看 python基础,爬虫,数据分析
Python入门书籍不用看太多,看一本就够.重要的是你要学习Python的哪个方向,或者说你对什么方向感兴趣,因为Python这门语言的应用领域比较广泛,比如说可以用来做数据分析.机器学习,也可以用来 ...
- Python爬虫从入门到进阶(1)之Python概述及爬虫入门
一.Python 概述 1.计算机语言概述 (1).语言:交流的工具,沟通的媒介 (2).计算机语言:人跟计算机交流的工具 (3).Python是计算机语言的一种 2.Python编程语言 代码:人类 ...
- Python 基础:分分钟入门
Python和Pythonic Python是一门计算机语言(这不是废话么),简单易学,上手容易,深入有一定困难.为了逼格,还是给你们堆一些名词吧:动态语言.解释型.网络爬虫.数据处理.机器学习.We ...
- scrapy基础 之 爬虫入门:先用urllib2来理解爬虫
1,概念理解 爬虫:抓取和保存网页信息,用户看到的网页实质是由 HTML 代码构成的,爬虫爬来的便是这些内容,通过分析和过滤这些 HTML 代码,实现对图片文字等资源的获取. URL:即统一资源定位符 ...
- Python基础之爬虫(持续更新中)
python通过urllib.request.urlopen("https://www.baidu.com")访问网页 实战,去网站上下载一只猫的图片 import urllib. ...
- python简单页面爬虫入门 BeautifulSoup实现
本文可快速搭建爬虫环境,并实现简单页面解析 1.安装 python 下载地址:https://www.python.org/downloads/ 选择对应版本,常用版本有2.7.3.4 安装后,将安装 ...
- python基础===【爬虫】爬虫糗事百科首页图片代码
import requests import re import urllib.request def getHtml(url): page = requests.get(url) html = pa ...
- python基础之1--Python入门
第1章 Python生态圈 第2章 编程与编程语言 python是一门编程语言,作为学习python的开始,需要事先搞明白:编程的目的是什么?什么是编程语言?什么是编程? 2.1 编程的目的: 计算机 ...
- Python 基础 4-1 字典入门
引言 字典 是Python 内置的一种数据结构,它便于语义化表达一些结构数据,字典是开发中常用的一种数据结构 字典介绍 字典使用花括号 {} 或 dict 来创建,字典是可以嵌套使用的 字典是成对出现 ...
随机推荐
- Catalina 动态壁纸相关设置
关闭SIP 重启,在开机时一直按Command+r进入recovery模式. 打开终端,如图所示: 在终端中输入命令,回车: csrutil disable 然后重启 设置动态壁纸 首先需在Dynam ...
- 《Java从入门到失业》第四章:类和对象(4.3):一个完整的例子带你深入类和对象
4.3一个完整的例子带你深入类和对象 到此为止,我们基本掌握了类和对象的基础知识,并且还学会了String类的基本使用,下面我想用一个实际的小例子,逐步来讨论类和对象的一些其他知识点. 4.3.1需求 ...
- Registry 容器镜像服务端细节
引言 通常我们在使用集群或者容器的时候,都会接触到存储在本地的镜像,也或多或少对本地镜像存储有一定的了解.但是服务端的镜像存储细节呢?本文主要介绍容器镜像的服务端存储结构,对于自建镜像服务或是对容器镜 ...
- python获取某视频网站视频
还是老生常谈的操作 import requests import os from bs4 import BeautifulSoup from urllib.parse import urljoin h ...
- 刷题[De1CTF 2019]SSRF Me
前置知识 本题框架是flask框架,正好python面向对象和flask框架没怎么学,借着这个好好学一下 这里我直接听mooc上北京大学陈斌老师的内容,因为讲的比较清楚,直接把他的ppt拿过来,看看就 ...
- 每日爬虫JS小逆之5分钟旅游网MD5一锅端
来吧骚年,每天花5分钟锻炼一下自己的JS调试也是极好的,对后期调试滑块验证码还原.拖动很有帮助,坚持下去,我们能赢.建议亲自试试哦,如果对大家有帮助的话不妨关注一下知识图谱与大数据公众号,当然不关注也 ...
- Python-全局解释器锁GIL原理和多线程产生原因与原理-多线程通信机制
GIL 全局解释器锁,这个锁是个粗粒度的锁,解释器层面上的锁,为了保证线程安全,同一时刻只允许一个线程执行,但这个锁并不能保存线程安全,因为GIL会释放掉的并且切换到另外一个线程上,不会完全占用,依据 ...
- 独立看第一个C++程序到最终结果log----2019-04-16
(如果一个人夸你,千万别相信,一个人真优秀是不需要说出来的,所以别人夸你的时候也是自己最松懈的时候,千万不能飘,只能说明自己不是很差而已,世界上优秀的人很多,一直优秀到最后的人却是凤毛菱角. 如果一个 ...
- Selenium截屏 图片未加载的问题解决--【懒加载】
需求: 截屏后转PDF. 问题: selenium截屏后,图片未加载 如下图: 原因: 网站使用了懒加载技术:只有在浏览器中纵向滚动条滚动到指定的位置时,页面的元素才会被动态加载. 什么是图片懒加载? ...
- 让我们创建屏幕- Android UI布局和控件
下载LifeCycleTest.zip - 278.9 KB 下载ViewAndLayoutLessons_-_Base.zip - 1.2 MB 下载ViewAndLayoutLessons_-_C ...