k8s 自动伸缩 pod(HPA)
上一篇简单说了一下使用 kubeadm 安装 k8s。今天说一下 k8s 的一个神奇的功能:HPA (Horizontal Pod Autoscaler)。
HPA 依赖 metrics-server 获取 pod 的指标。所以我们要先安装 metrics-server 插件。
1. metrics-server 安装
1.1 下载 yaml 文件和 image
# 在 k8s master 节点执行
mkdir metrics-server
cd metrics-server
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml docker pull ninejy/metrics-server:v0.3.7
docker tag ninejy/metrics-server:v0.3.7 k8s.gcr.io/metrics-server/metrics-server:v0.3.7
1.2 安装
# 修改 components.yaml 文件,在 args 下面添加以下两行内容,不校验证书,不然会报 x509 错误
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP
- --kubelet-insecure-tls kubectl apply -f components.yaml
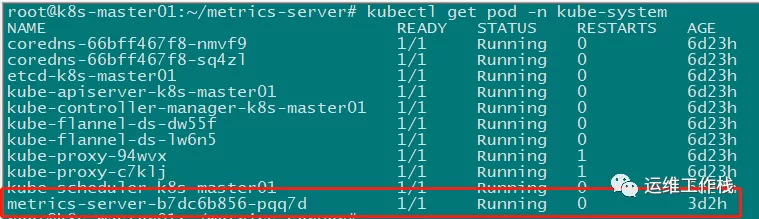
kubectl get pod -n kube-system
# 列出的 pod 中有 metrics-server-xxxxxxx,并且是 Running状态,就说明 metrics-server 安装好了
1.3 问题
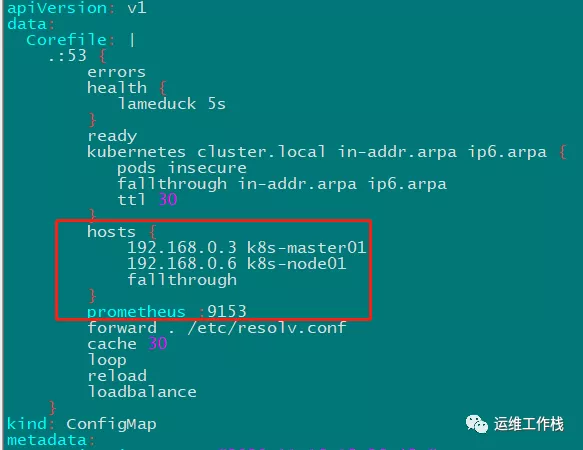
此时执行命令 `kubectl top nodes` 应该不会有结果。查看metrics-server pod 的日志,会有找不到主机 k8s-master01,k8s-node01的错误。这是因为主机名、IP的映射关系是我们在 hosts 文件里写的。需要在 coredns 的配置中加上这两个主机名、IP的对应关系记录。
kubectl edit configmap coredns -n kube-system
# 添加以下内容,然后 按键盘 Esc 输入 :wq 保存退出
hosts {
192.168.0.3 k8s-master01
192.168.0.6 k8s-node01
fallthrough
}
之后再执行 `kubectl top nodes` 就应该会有类似下图内容了

这样 metrics-server 就算安装好了。
2. 测试 HPA
2.1 deploymet/service/hpa yaml 文件
# cat hpa-cpu.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-hpa-cpu
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: myapp
image: ninejy/hpacpu:latest
ports:
- containerPort: 8080
resources:
limits:
cpu: 50m
memory: 10Mi
requests:
cpu: 50m
memory: 10Mi
---
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
ports:
- name: http
port: 80
targetPort: 8080
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: deployment-hpa-cpu
namespace: default
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deployment-hpa-cpu
targetCPUUtilizationPercentage: 80
这里我们限制每个 pod 最多使用一核 cpu 的 50/1000,当 pod 使用 cpu 的百分比大于最大限制的 80% 就会触发 pod 扩容,最多扩展到 5 个 pod.
2.2 创建 deploymet/service/hpa
kubectl apply -f hpa-cpu.yaml
2.3 测试 HPA
# 开三个 k8s-master01 窗口,分别执行下面三条命令
watch kubectl get pods
watch kubectl top pods
ip=$(kubectl get svc | grep myapp | awk '{print $3}')
for i in `seq 1 100000`; do curl $ip?a=$i; done
切换窗口查看,过一会就会有 pod 数量增加,说明 HPA 生效了。停掉 curl 的那条命令,过一会,pod 数量又会恢复到 1 个了。
以上就是 k8s HPA 的基本使用。HPA 也可以使用内存和其他自定义的指标,也可以组合使用。根据这些指标的值和设定的阈值进行 pod 的数量的增减。
更多内容可以参考 k8s 官网:
https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
k8s 自动伸缩 pod(HPA)的更多相关文章
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- k8s Pod的自动水平伸缩(HPA)
我们知道,当访问量或资源需求过高时,使用:kubectl scale命令可以实现对pod的快速伸缩功能 但是我们平时工作中我们并不能提前预知访问量有多少,资源需求多少. 这就很麻烦了,总不能为了需求总 ...
- 基于Kubernetes的hpa实现pod实例数量的自动伸缩
Pod 是在 Kubernetes 体系中,承载用户业务负载的一种资源.Pod 们运行的好坏,是用户们最为关心的事情.在业务流量高峰时,手动快速扩展 Pod 的实例数量,算是玩转 Kubernetes ...
- kubernetes之Pod水平自动伸缩(HPA)
https://k8smeetup.github.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ Horizon ...
- K8S(17)二进制的1.15版本部署hpa自动伸缩
K8S(17)二进制部署的K8S(1.15)部署hpa功能 目录 K8S(17)二进制部署的K8S(1.15)部署hpa功能 零.参考文件: 一.生成metrics-proxy证书 二.修改apise ...
- Horizontal Pod Autoscaler(Pod水平自动伸缩)
Horizontal Pod Autoscaler 根据观察到的CPU利用率(或在支持自定义指标的情况下,根据其他一些应用程序提供的指标)自动伸缩 replication controller, de ...
- kubernetes云平台管理实战:HPA水平自动伸缩(十一)
一.自动伸缩 1.启动 [root@k8s-master ~]# kubectl autoscale deployment nginx-deployment --max=8 --min=2 --cpu ...
- 基于Prometheus,Alermanager实现Kubernetes自动伸缩
到目前为止Kubernetes对基于cpu使用率的水平pod自动伸缩支持比较良好,但根据自定义metrics的HPA支持并不完善,并且使用起来也不方便. 下面介绍一个基于Prometheus和Aler ...
- k8s弹性伸缩概念以及测试用例
k8s弹性伸缩概念以及测试用例 本文原文出处:https://juejin.im/post/5c82367ff265da2d85330d4f 弹性伸缩式k8s中的一大亮点功能,当负载大的时候,你可以对 ...
随机推荐
- 论文解读《Understanding the Effective Receptive Field in Deep Convolutional Neural Networks》
感知野的概念尤为重要,对于理解和诊断CNN网络是否工作,其中一个神经元的感知野之外的图像并不会对神经元的值产生影响,所以去确保这个神经元覆盖的所有相关的图像区域是十分重要的:需要对输出图像的单个像素进 ...
- vue父组件促发子组件中的方法
实现在父组件中促发子组件里面的方法 子组件: <template> <div> 我是子组件 </div> </template> <script& ...
- 20200725_java爬虫_项目创建及log4j配置
0. 摘要 0.1 添加log4j依赖 <dependency> <groupId>org.slf4j</groupId> <artifactId>sl ...
- python爬虫10 b站爬取使用 selenium+ phantomJS
但有时候 我们不想要让它打开浏览器去执行 能不能直接在代码里面运行呢 也就是说 有没有一个无形的浏览器呢 恩 phantomJS 就是 它是一个基于 WebKit 的浏览器引擎 可以做到无声无息的操作 ...
- shell脚本实现---Zabbix5.0快速部署
shell脚本实现---Zabbix5.0快速部署 zabbix-server快速安装脚本 #!/bin/bash #Zabbix-Server 5.0#author:sunli#mail:sunli ...
- [C#.NET 拾遗补漏]12:死锁和活锁的发生及避免
多线程编程时,如果涉及同时读写共享数据,就要格外小心.如果共享数据是独占资源,则要对共享数据的读写进行排它访问,最简单的方式就是加锁.锁也不能随便用,否则可能会造成死锁和活锁.本文将通过示例详细讲解死 ...
- 准备数据集用于flink学习
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- mingw32环境下链接库找不到问题
本人在win10下安装了mingw环境,以方面windows下测试gcc编译器构建一些开源组件.但是windows系统下遇到了一些编译问题. 1. 问题现象 一次手写的Makefile遇到了如下编译错 ...
- 数组和list 相互转换中遇到的坑
代码示例: public class ArrayDemo { public static void main(String[] args) { Integer[] arr = {1, 2, 3, 4, ...
- Shell脚本常用命令整理
该笔记主要整理了一些常见的脚本操作命令,大致如下(持续补充中): 1. while.for循环 1. while.for循环 #!/bin/bash # while循环 v_start_date=${ ...