【原创】linux实时操作系统xenomai x86平台基准测试(benchmark)
一、前言
benchmark 即基准测试。通常操作系统主要服务于应用程序,其运行也是需要一定cpu资源的,一般来说操作系统提供服务一定要快,否则会影响应用程序的运行效率,尤其是实时操作系统。所以本文针对操作系统来做一些基准测试,看看在低端x86平台上,xenomai提供我们平时常用的服务所需要的时间,清楚地了解该平台上一些xenomai服务的消耗,有时能有利于我们进一步优化程序。影响因素有:主机CPU的结构、指令集以及CPU特性、运算速度等。
目前大多商业实时操作系统会提供详细benchmark测试,比如VxWorks,目前xenomai没有这类的方式,所以借鉴VxWorks的测试方式,对xenomai进行同样测试,所以文章中的测试项命名可能在Linux开发人员看来有点别扭,切勿见怪,其中一些具体流程可见本博客另外一篇文章xenomai与VxWorks实时性对比(资源抢占上下文切换对比)。
测试环境:
CPU:Intel j1900
内存:4GB DDR3
注:文中测试数据,单位us,每项测试次数500万次,编写测试用例使用的接口为Alchemy API,原因主要是Alchemy API比较好编写。
二、 测试数据处理
对于每个基准测试,通过在操作前读取时间戳\(t1\),该操作完成后读取时间戳\(t2\),\(t2\)与\(t1\)之间的差值就是测该操作的耗时。
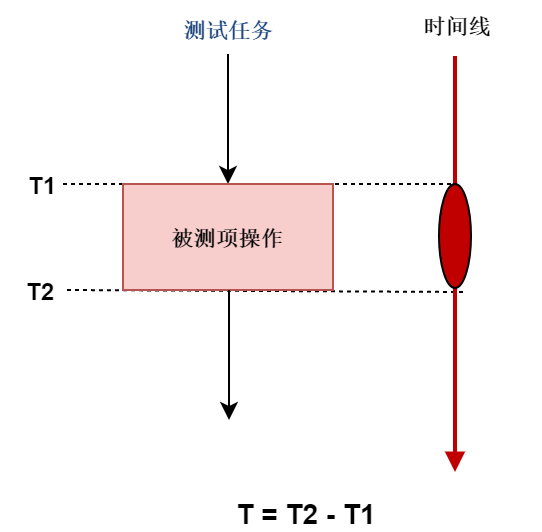
1.1 测试注意事项
需要注意的是,由于我们是基准测试,所以\(t1\)~\(t2\)这段时间尽量不要被不相关的事务打断,比如处理不相关的中断、非测试范围内的任务抢占等。为此需要考虑如下。
① 执行测试操作的任务优先级必须最高,两个任务间交互的测试类似。
② 必须检测t1-t2之间的非相关中断,并丢弃对应的测试数据,由于我们已将非xenomai的中断隔离到其cpu0,且无其他实时设备中断,除各种异常外,剩下与xenomai相关的就是定时器中断了,所以仅对tick中断处理,如果测试过程中产生了定时器中断,则忽略这组数据,因此需要为xenomai添加一个系统调用来获取中断信息,测试前后通过该系统调用获中断信息,以此判断测试的过程中有没有中断产生。
③ 读取时间戳的操作也是需要执行时间的,所以需要从结果中减去该时间的影响,测量读取时间戳的需要的时间很简单,通过连续两次读取时间戳\(a1\),\(a2\),\(a2-a1\)就是函数 _M_TIMESTAMP()的执行需要时间。
1.2 数据的处理
得到无误的操作耗时、测试次数后计算平均值最大值、最小值即可;
1.3 测试结构
根据以上,每个测试的流程及代码结构如下:
① 读取起始tick
② 开始测试循环
③ 读取时间戳a
④ 读取起始时间戳b
⑤ 被测试的操作
⑥读取结束时间戳c
⑦判断是否是loadrun,是则丢弃本次结果跳转到③
⑧读取tick,判断本次测试是否位于同一tick内,否则丢弃本次结果跳转到③
⑨判读耗时是都正确(a-b且b-c为正值),是则为有效值,否则丢弃本次结果跳转到③
unsigned long a;
unsigned long b;
unsigned long c;
ULONG tick;
BOOL loadRun = TRUE; /*排除cache对测试的影响,丢弃第一次测试的数据*/
tick = tickGet(); /*确保测试在同一个tick内完成*/
/*循环测试iterations次操作并统计结果*/
for (counter = 0; counter < pData->iterations; counter++)
{
a = _M_TIMESTAMP();
b = _M_TIMESTAMP(); /*起始时间*/
wd = wdCreate ();/*测试的操作*/
c = _M_TIMESTAMP(); /*结束时间*/
/*数据统计处理*/
BM_DATA_RECORD (((c >= b) && (b >= a)), c - b, b - a,
counter, tick, loadRun);
}
二、测试项
明白数据统计处理后剩下的就是其中测试的具体操作了,benchmark 分别对二值信号量(semB)、计数信号量(semC)、互斥量(semM)、读写信号量(SemRW)、任务(Task)、消息队列(msgq)、事件(event)、 中断响应(interrupt)、上下文切换(contexswitch)、时钟抖动(TaskJitter、IntJitter)在各种可能的情况下,测试该操作的耗时。
2.1 时间戳
测试读时间戳耗时bmTimestampRead。
unsigned long a;
unsigned long b;
ULONG tick;
BOOL loadRun = TRUE; \
tick = tickGet();
for (counter = 0; counter < pData->iterations; counter++)
{
a = _M_TIMESTAMP();
b = _M_TIMESTAMP();
/* validate and record data */
BM_DATA_RECORD ((b > a), b - a, 0, counter, tick, loadRun);
}

| min | avg | max |
|---|---|---|
| 0.084 | 0.094 | 0.132 |
2.2 任务切换
2.2.1信号量响应上下文切换时间
bmCtxSempend: 同一cpu上,高优先级任务对空信号量P操作阻塞,到低优先任务激活的时间。
bmCtxSemUnpend: 同一cpu上,低优先级任务对信号量V操作到高优先任务激活的时间。
CtxSmpAffinitySemUnPend: 高低优先级任务运行于不同cpu上,高优先级任务对空信号量P操作阻塞,到低优先任务激活的时间。
CtxSmpNoAffinitySemUnPend: 不设置亲和性,随系统调度,低优先级任务对信号量V操作到高优先任务激活的时间。
| min | avg | max | |
|---|---|---|---|
| bmCtxSempend | 2.136 | 2.193 | 2.641 |
| bmCtxSemUnpend | 2.351 | 2.395 | 2.977 |
| CtxSmpAffinitySemUnPend | 0.000 | 0.752 | 2.642 |
| CtxSmpNoAffinitySemUnPend | 2.389 | 2.454 | 2.797 |
2.2.2消息队列响应上下文切换时间
bmCtxMsgqPend:同一cpu上,高优先级任务对空消息队列接收数据阻塞,到低优先任务激活的时间。
bmCtxMsgqUnpend:同一cpu上, 低优先级任务写消息队列到高优先任务激活的时间。
CtxSmpAffinityMsgQUnPend:高低优先级任务运行于不同cpu上,高优先级任务对空消息队列接收数据阻塞,到低优先任务激活的时间。
CtxSmpNoAffinityMsgQUnPend:不设置亲和性,随系统调度, 低优先级任务写消息队列到高优先任务激活的时间。
| min | avg | max | |
|---|---|---|---|
| bmCtxMsgqPend | 2.496 | 2.529 | 2.833 |
| bmCtxMsgqUnpend | 2.882 | 2.949 | 3.374 |
| CtxSmpAffinityMsgQUnPend | 5.245 | 5.497 | 10.589 |
| CtxSmpNoAffinityMsgQUnPend | 2.941 | 2.995 | 3.636 |
2.2.3事件响应上下文切换时间
bmCtxMsgqPend:高优先级任务接收事件阻塞,到低优先任务激活的时间。
bmCtxMsgqUnpend: 低优先级任务发送事件到高优先任务激活的时间。
| min | avg | max | |
|---|---|---|---|
| bmCtxEventPend | - | - | - |
| bmCtxEventUnpend | - | - | - |
| CtxSmpAffinityEventQUnPend | - | - | - |
| CtxSmpNoAffinityEventUnPend | - | - | - |
2.2.2.4任务上下文切换时间
bmCtxTaskSwitch:同一cpu上,优先级调度下的任务切换时间。
| min | avg | max | |
|---|---|---|---|
| bmCtxTaskSwitch | 0.703 | 1.633 | 2.594 |
2.3 信号量(Semaphore)
1. 信号量的创建与删除
bmSemBCreate: 创建一个信号量耗时。
bmSemBDelete: 删除一个信号量耗时。
| min | avg | max | |
|---|---|---|---|
| bmSemCreate | 10.433 | 11.417 | 12.977 |
| bmSemDelete | 10.276 | 11.431 | 12.317 |
2. 信号量PV操作
SemGiveNoTask:当没有任务阻塞在信号量上时,对空信号量V操作消耗的时间。
SemGiveTaskInQ:同一CPU上,高优先级任务阻塞在信号量时,低优先级任务释放信号量操作消耗的时间。
SemTakeUnavail:单任务对不可用的信号量P操作消耗的时间。
SemTakeAvail:单任务对可用信号量非阻塞P操作消耗的时间。
bmSemGiveTake:单任务对同一信号量连续一次PV操作消耗的时间。
| min | avg | max | |
|---|---|---|---|
| SemGiveNoTask | 0.099 | 0.110 | 0.132 |
| SemGiveTaskInQ | 1.837 | 2.036 | 2.281 |
| SemTakeAvail | 0.084 | 0.094 | 0.108 |
| SemTakeUnavail | 0.111 | 0.125 | 0.144 |
| SemGiveTake | 0.187 | 0.192 | 0.198 |
| SemPrioInv | 6.531 | 6.842 | 11.968 |
2.4 互斥量(Mutex)
2.4.1 互斥量的创建与删除
MutexCreate:创建一个互斥量耗时。
MutexDelete:删除一个互斥量耗时。
2.4.2 互斥量PV操作
MutexGiveNoTask:当没有任务阻塞在mutex上时,释放mutex操作消耗的时间。
MutexGiveTaskInQ:同一CPU上,高优先级任务阻塞在mutex时,低优先级任务释放mutex操作消耗的时间。
MutexTakeUnavail:当没有mutex可用时,对mutex请求操作的耗时。
MutexTakeAvail:在mutex可用时,请求mutex消耗的时间。
MutexGiveTake:单任务对mutex连续请求释放消耗的时间。
| min | avg | max | |
|---|---|---|---|
| MutexCreate | 2.881 | 2.947 | 3.205 |
| MutexDelete | 2.039 | 2.084 | 2.209 |
| MutexGiveNoTask | 0.033 | 0.044 | 0.066 |
| MutexGiveTaskInQ | 0.047 | 0.117 | 0.228 |
| MutexTakeAvail | 0.084 | 0.094 | 0.114 |
| MutexGiveTake | 0.118 | 0.122 | 0.148 |
2.5 消息队列(Message Queue)
2.5.1 创建与删除
MsgQCreate:创建一个MsgQ需要的时间。
MsgQDelete:删除一个MsgQ需要的时间。
2.5.2 数据收发
MsgQRecvAvail:当MsgQ内有数据时,接收1Byte数据需要的时间。
MsgQRecvNoAvail:当MsgQ没有数据时,非阻塞接收1Byte数据需要的时间。
MsgQSendPend:高优先级等待数据时,发送1Byte数据需要的时间。
MsgQSendNoPend:没有任务等待数据时,发送1Byte数据需要的时间。
MsgQSendQFull:当MsgQ满时,非阻塞发送1Byte数据需要的时间。
| min | avg | max | |
|---|---|---|---|
| MsgQCreate | 5.991 | 6.324 | 6.855 |
| MsgQDelete | 3.733 | 3.849 | 4.046 |
| MsgQRecvAvail | 0.240 | 0.279 | 0.396 |
| MsgQRecvNoAvail | 0.216 | 0.267 | 0.349 |
| MsgQSendPend | 2.401 | 2.647 | 3.902 |
| MsgQSendNoPend | 1.223 | 1.262 | 1.536 |
| MsgQSendQFull | 0.228 | 0.275 | 0.408 |
2.6 定时器(Alarm)
AlarmCreate:创建一个alarm的时间。
AlarmDelStarted:删除一个已经激活的alarm的时间。
AlarmDelNotStarted:删除一个未激活alarm的时间。
AlarmStartQEmpty:任务没有alarm时,start一个alarm需要的时间。
AlarmStartQEmpty:任务在已有一个 alarm的基础上,再start一个alarm需要的时间。
AlarmCancel:stop一个alarm需要的时间。
| min | avg | max | |
|---|---|---|---|
| AlarmCreate | 4.790 | 4.937 | 7.719 |
| AlarmDelStarted | 3.637 | 3.804 | 4.250 |
| AlarmDelNotStarted | 3.420 | 3.523 | 4.381 |
| AlarmStartQEmpty | 1.860 | 2.079 | 3.158 |
| AlarmStartQFull | 1.835 | 1.897 | 2.101 |
| AlarmCancel | 1.596 | 1.680 | 2.677 |
2.7 事件(Event)
EventSendSelf: 任务向自己发送一个Event需要的时间。
EventReceiveAvailable: 接收一个已产生的Event需要的时间。
EventReceiveUnavailable: 非阻塞接收一个未产生的Event需要的时间。
EventTaskSendWanted: 高优先级等待Event时,发送Event需要的时间。
EventTaskSendUnwanted: 无任务等待Event时,发送Event需要的时间。
| min | avg | max | |
|---|---|---|---|
| EventSendSelf | 4.790 | 4.937 | 7.719 |
| EventReceiveAvailable | 3.637 | 3.804 | 4.250 |
| EventReceiveUnavailable | 3.420 | 3.523 | 4.381 |
| EventTaskSendWanted | 1.860 | 2.079 | 3.158 |
| EventTaskSendUnwanted | 1.835 | 1.897 | 2.101 |
2.8 任务(Task)
2.8.1 任务创建激活
TaskSpawn: 创建并激活一个任务需要的时间。
TaskDelete:删除一个任务需要的时间。
TaskInit:创建一个任务需要的时间。
TaskActivate:激活新创建的任务需要的时间。
2.8.2 任务调度控制
TaskSuspendReady:对一个已经处于ready状态的任务suspend操作需要的时间。
TaskSuspendPend:对一个等待资源处于pend状态的任务进行suspend操作需要的时间。
TaskSuspendSusp:对刚创建的处于Suspend任务 执行Suspend操作需要的时间。
TaskSuspendDelay:对一个处于sleep任务进行suspend操作需要的时间。
TaskResumeReady:对一个处于Ready状态的任务进行Resume操作需要的时间。
TaskResumePend:对一个等待资源处于pend状态的任务进行Resume操作需要的时间。
TaskResumeSusp:对一个处于Suspend状态的任务进行Resume操作需要的时间。
TaskResumeDelay:对一个处于sleep任务进行Resume操作需要的时间。
TaskPrioritySetReady:对一个处于Ready状态任务修改优先级操作需要的时间。
TaskPrioritySetPend:对一个处于pend状态任务修改优先级操作需要的时间。
bmTaskCpuAffinityGet:获取任务的亲和性需要的时间。
bmTaskCpuAffinitySet:设置任务的亲和性需要的时间。
| min | avg | max | |
|---|---|---|---|
| TaskSpawn(1000万次) | 150.649 | 153.859 | 1162.041 |
| TaskDelete(1000万次) | 136.074 | 145.766 | 189.952 |
| TaskInit(1000万次) | 178.703 | 185.015 | 436.639 |
| TaskActivate | 1.052 | 1.336 | 2.986 |
| TaskSuspendReady | 1.404 | 1.444 | 1.681 |
| TaskSuspendPend | 0.035 | 1.392 | 1.561 |
| TaskSuspendSusp | 0.151 | 0.155 | 0.321 |
| TaskSuspendDelay | 1.356 | 1.401 | 1.525 |
| TaskResumeReady | 0.146 | 0.155 | 0.487 |
| TaskResumePend | 0.756 | 0.802 | 0.877 |
| TaskResumeSusp | 0.204 | 0.248 | 0.324 |
| TaskResumeDelay | 0.180 | 0.228 | 0.300 |
| TaskPrioritySetReady | 18.925 | 21.002 | 21.855 |
| TaskPrioritySetPend | 19.046 | 21.014 | 28.296 |
| TaskCpuAffinityGet | - | - | - |
| TaskCpuAffinitySet | 8.332 | 9.541 | 19.808 |
Cyclic:如下操作的流程循环一次的耗时,图中M表示mutex,B表示Semaphore。
/*
Higher Priority Lower Priority
Task1 Task2
=============== ==============
semTake(M)
semGive(M)
|
V
semGive(B)
semTake(B)
|
V
semTake(B)
\
\
\-------------> semTake(M)
semGive(B)
/
/
semTake(M) <-------------/
\
\
\-------------> semGive(M)
/
/
semGive(M) <-------------/
|
V
taskSuspend() <-------------/
\
\
\-------------> taskResume()
/
/
msgQSend() <-------------/
msgQReceive()
|
V
msgQReceive()
\
\
\-------------> msgQSend()
/
/
taskDelay(0) <-------------/
|
V
eventReceive()
\
\
\-------------> eventSend()
/
/
repeat... <-------------/
*/
| min | avg | max | |
|---|---|---|---|
| Cyclic | 33.589 | 34.409 | 36.471 |
版权声明:本文为本文为博主原创文章,转载请注明出处。如有问题,欢迎指正。博客地址:https://www.cnblogs.com/wsg1100/
【原创】linux实时操作系统xenomai x86平台基准测试(benchmark)的更多相关文章
- 【原创】xenomai3.1+linux构建linux实时操作系统-基于X86_64和arm
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 目录 一.概要 二.环境准备 1.1 安装内核编译工 ...
- linux内核移植X86平台的例子
bootloader支持启动多个Linux 内核安装(X86平台) 1. cparch/x86/boot/bzImage /boot/vmlinuz-$version 2. cp $initrd /b ...
- Linux 定制X86平台操作系统
/********************************************************************************* * Linux 定制X86平台操作 ...
- 【原创】有利于提高xenomai 实时性的一些配置建议
版权声明:本文为本文为博主原创文章,转载请注明出处.如有错误,欢迎指正. @ 目录 一.影响因素 1.硬件 2.BISO(X86平台) 3.软件 4. 缓存使用策略与GPU 二.优化措施 1. BIO ...
- X86平台下嵌入式linux触摸屏解决方案(usb触摸屏控制器+完美校准方案+触摸屏QTE开发环境搭建)
一直在用X86平台,真心不想用WINCE和XPE,一些大的硬件供应商都不提供linux平台下的技术支持,比如研华的3343PC104系列的板子... 开发的问题如下: 1 USB控制器目前只有台湾和竹 ...
- Linux.中断处理.入口x86平台entry_32.S
Linux.中断处理.入口x86平台entry_32.S Linux.中断处理.入口x86平台entry_32.S 在保护模式下处理器是通过中断号和IDTR找到中断处理程序的入口地址的.IDTR存的是 ...
- QNX 实时操作系统(Quick Unix)
Gordon Bell和Dan Dodge在1980年成立了Quantum Software Systems公司,他们根据大学时代的一些设想写出了一个能在IBM PC上运行的名叫QUNIX(Quick ...
- Linux服务器操作系统
Linux服务器操作系统 今日大纲 ● 服务器操作系统的系列.Linux的主流产品.虚拟机软件 ● 安装linux ● linux基本命令 ● 用户管理及权限(多用户) ● ...
- X86平台乱序执行简要分析(翻译为主)
多处理器使用松散的内存模型可能会非常混乱,写操作可能会无序,读操作可能会返回不是我们想要的值,为了解决这些问题,我们需要使用内存栅栏(memory fences),或者说内存屏障(memory bar ...
随机推荐
- Java中的常见锁(公平和非公平锁、可重入锁和不可重入锁、自旋锁、独占锁和共享锁)
公平和非公平锁 公平锁:是指多个线程按照申请的顺序来获取值.在并发环境中,每一个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个就占有锁,否者就会加入到等待队列中,以 ...
- linux学习(四)Linux 文件基本属性
一.引言 Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限. 为了保护系统的安全性,Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定. 在Lin ...
- Layer层自定义
keras允许自定义Layer层, 大大方便了一些复杂操作的实现. 也方便了一些novel结构的复用, 提高搭建模型的效率. 实现方法 通过继承keras.engine.Layer类, 重写其中的部分 ...
- 每日爬虫JS小逆之5分钟旅游网MD5一锅端
来吧骚年,每天花5分钟锻炼一下自己的JS调试也是极好的,对后期调试滑块验证码还原.拖动很有帮助,坚持下去,我们能赢.建议亲自试试哦,如果对大家有帮助的话不妨关注一下知识图谱与大数据公众号,当然不关注也 ...
- [译]await VS return VS return await
原文地址:await vs return vs return await作者:Jake Archibald 当编写异步函数的时候,await,return,return await三者之间有一些区别, ...
- @DependsOn注解的使用
如果Bean A 在创建前需要先创建BeanB此时就可以使用DependsOn注解 @Configuration public class MyConfig { @Bean @DependsOn(&q ...
- NX二次开发-C#使用DllImport调用libufun.dll里的UF函数(反编译.net.dll)调用loop等UF函数
在写这篇文章的时候,我正在头晕,因为下班坐车回家,有些晕车了.头疼的要死.也吃不下去饭. 版本:NX11+VS2013 最近这一年已经由C++过度到C#,改用C#做应用程序开发和NX二次开发. C#在 ...
- 使用gettid() 注意事项
gettid()这个函数不可以在程序中直接使用,它是Linux本身的一个函数, 但是:仅包含#include <sys/types.h>,然后使用,编译时会报该函数未定义之类的错误! 解决 ...
- 浅谈Prufer序列
\(\text{Prufer}\)序列,是树与序列的一种双射. 构建过程: 每次找到一个编号最小的叶子节点\(Leaf\),将它删掉,并将它所连接的点的度数\(-1\),且加入\(\text{Pruf ...
- AD(Altium Designer)PCB布线中的“格式刷”,助力快速布局布线
摘要:在AD(Altium Designer)进行电路板布线时,孔丙火(微信公众号:孔丙火)经常会碰到电路中有相同功能的模块,比如2路相同的RS485通信电路.多路相同继电器输出电路.多路相同的输入电 ...