Keras结合Keras后端搭建个性化神经网络模型(不用原生Tensorflow)
Keras是基于Tensorflow等底层张量处理库的高级API库。它帮我们实现了一系列经典的神经网络层(全连接层、卷积层、循环层等),以及简洁的迭代模型的接口,让我们能在模型层面写代码,从而不用仔细考虑模型各层张量之间的数据流动。
但是,当我们有了全新的想法,想要个性化模型层的实现,Keras的高级API是不能满足这一要求的,而换成Tensorflow又要重新写很多轮子,这时,Keras的后端就派上用场了。Keras将底层张量库的函数功能统一封装在“backend”中,用户可以用统一的函数接口调用不同的后端实现的相同功能。所以,如果不追求速度的话,可以仅使用Keras实现你的任何独特想法,从而避免使用原生Tensorflow写重复的轮子。
我们定义并训练一个神经网络模型需要考虑的要素有三个:层、损失函数、优化器。而我们创新主要在于前两个,因此下面介绍如何结合Keras高级API与后端,自定义特殊神经网络层以及损失函数。
自定义网络层
自定义层可以通过两种方式实现:使用Lambda层和继承Layer类。
lambda层
Lambda层仅能对输入做固定的变换,并不能定义可以通过反向传播训练的参数(通过Keras的fit训练),因此能实现的东西较少。以下代码实现了Dropout的功能:
from keras import backend as K
from keras import layers def my_layer(x):
mask = K.random_binomial(K.shape(x),0.5)
return x*mask*2
x = layers.Lambda(my_layer)(x)
其中my_layer函数是自定义层要实现的操作,传递参数只能是Lambda层的输入。定义好函数后,直接在layers.Lambda中传入函数对象即可。实际上,这些变换不整合在lambda层中而直接写在外面也是可以的:
from keras import backend as K
from keras import layers x = layers.Dense(500,activation='relu')(x)
mask = K.random_binomial(K.shape(x),0.5)
x = x*mask*2
数据先经过一个全连接层,然后再被0.5概率Dropout。以上实现Dropout只是作举例,你可以以同样的方式实现其它的功能。
继承layer类
如果你想自定义可以训练参数的层,就需要继承实现Keras的抽象类Layer。主要实现以下三个方法:
1、__init__(self, *args, **kwargs):构造函数,在实例化层时调用。此时还没有添加输入,也就是说此时输入规模未知,但可以定义输出规模等与输入无关的变量。类比于Dense层里的units、activations参数。
2、build(self, input_shape):在添加输入时调用(__init__之后),且参数只能传入输入规模input_shape。此时输入规模与输出规模都已知,可以定义训练参数,比如全连接层的权重w和偏执b。
3、call(self, *args, **kwargs):编写层的功能逻辑。
单一输入
当输入张量只有一个时,下面是实现全连接层的例子:
import numpy as np
from keras import layers,Model,Input,utils
from keras import backend as K
import tensorflow as tf class MyDense(layers.Layer):
def __init__(self, units=32): #初始化
super(MyDense, self).__init__()#初始化父类
self.units = units #定义输出规模
def build(self, input_shape): #定义训练参数
self.w = K.variable(K.random_normal(shape=[input_shape[-1],self.units])) #训练参数
self.b = tf.Variable(K.random_normal(shape=[self.units]),trainable=True) #训练参数
self.a = tf.Variable(K.random_normal(shape=[self.units]),trainable=False) #非训练参数
def call(self, inputs): #功能实现
return K.dot(inputs, self.w) + self.b #定义模型
input_feature = Input([None,28,28])
x = layers.Reshape(target_shape=[28*28])(input_feature)
x = layers.Dense(500,activation='relu')(x)
x = MyDense(100)(x)
x = layers.Dense(10,activation='softmax')(x) model = Model(input_feature,x)
model.summary()
utils.plot_model(model)
模型结构如下:
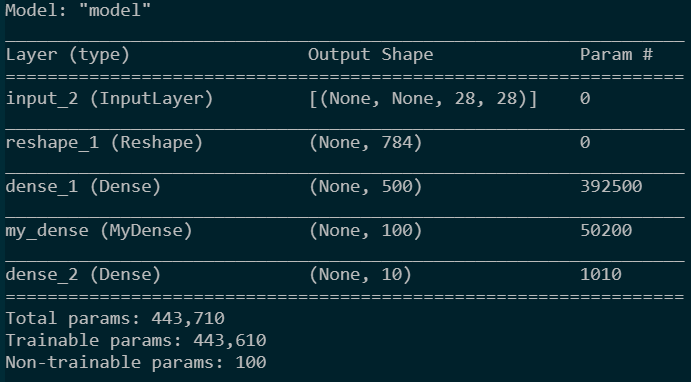 |
 |
在build()中,训练参数可以用K.variable或tf.Variable定义。并且,只要是用这两个函数定义并存入self中,就会被keras认定为训练参数,不管是在build还是__init__或是其它函数中定义。但是K.variable没有trainable参数,不能设置为Non-trainable params,所以还是用tf.Variable更好更灵活些。
多源输入
如果输入包括多个张量,需要传入张量列表。实现代码如下:
import numpy as np
from keras import layers,Model,Input,utils
from keras import backend as K
import tensorflow as tf class MyLayer(layers.Layer):
def __init__(self, output_dims):
super(MyLayer, self).__init__()
self.output_dims = output_dims
def build(self, input_shape):
[dim1,dim2] = self.output_dims
self.w1 = tf.Variable(K.random_uniform(shape=[input_shape[0][-1],dim1]))
self.b1 = tf.Variable(K.random_uniform(shape=[dim1]))
self.w2 = tf.Variable(K.random_uniform(shape=[input_shape[1][-1],dim2]))
self.b2 = tf.Variable(K.random_uniform(shape=[dim2]))
def call(self, x):
[x1, x2] = x
y1 = K.dot(x1, self.w1)+self.b1
y2 = K.dot(x2, self.w2)+self.b2
return K.concatenate([y1,y2],axis = -1) #定义模型
input_feature = Input([None,28,28])#输入
x = layers.Reshape(target_shape=[28*28])(input_feature)
x1 = layers.Dense(500,activation='relu')(x)
x2 = layers.Dense(500,activation='relu')(x)
x = MyLayer([100,80])([x1,x2])
x = layers.Dense(10,activation='softmax')(x) model = Model(input_feature,x)
model.summary()
utils.plot_model(model,show_layer_names=False,show_shapes=True)
模型结构如下:
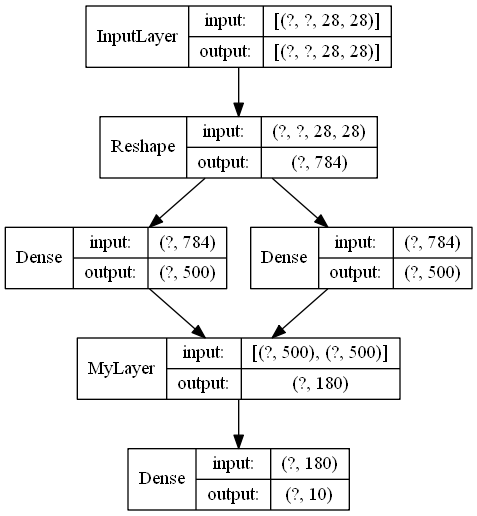
总之,传入张量列表,build传入的input_shape就是各个张量形状的列表。其它都与单一输入类似。
自定义损失函数
根据Keras能添加自定义损失的特性,这里将添加损失的方法分为两类:
1、损失需要根据模型输出与真实标签来计算,也就是只有模型的输出与外部真实标签作为计算损失的参数。
2、损失无需使用外部真实标签,也就是只用模型内部各层的输出作为计算损失的参数。
这两类损失添加的方式并不一样,希望以后Keras能把API再改善一下,这种冗余有时让人摸不着头脑。
第一类损失
这类损失可以通过自定义函数的形式来实现。函数的参数必须是两个:真实标签与模型输出,不能多也不能少,并且顺序不能变。然后你可以在这个函数中定义你想要的关于输出与真实标签之间的损失。然后在model.compile()中将这个函数对象传给loss参数。代码示例如下(参考链接):
def customed_loss(true_label,predict_label):
loss = keras.losses.categorical_crossentropy(true_label,predict_label)
loss += K.max(predict_label)
return loss model.compile(optimizer='rmsprop', loss=customed_loss)
如果硬是想用这种方法把模型隐层的输出拿来算损失的话,也不是不可以。只要把相应隐层的输出添加到模型的输出列表中,自定义损失函数就可以从模型输出列表中取出隐层输出来用了。即:
model = Model(input,[model_output, hidden_layer_output])
当然,这样就把模型结构改了,如果不想改模型的结构而添加“正则化”损失,可以使用下面的方法。
第二类损失
这类损失可以用Model.add_loss(loss)方法实现,loss可以使用Keras后端定义计算图来实现。但是显然,计算图并不能把未来训练用的真实标签传入,所以,add_loss方法只能计算模型内部的“正则化”损失。
add_loss方法可以使用多次,损失就是多次添加的loss之和。使用了add_loss方法后,compile中就可以不用给loss赋值,不给loss赋值的话使用fit()时就不能传入数据的标签,也就是y_train。如果给compile的loss赋值,最终的目标损失就是多次add_loss添加的loss和compile中loss之和。另外,如果要给各项损失加权重的话,直接在定义loss的时候加上即可。代码示例如下:
loss = 100000*K.mean(K.square(somelayer_output))#somelayer_output是定义model时获得的某层输出
model.add_loss(loss)
model.compile(optimizer='rmsprop')
以上讲的都是关于层输出的损失,层权重的正则化损失并不这样添加,自定义正则项可以看下面。
keras中添加正则化_Bebr的博客-CSDN博客_keras 正则化
里面介绍了已实现层的自定义正则化,但没有介绍自定义层的自定义正则化,这里先挖个坑,以后要用再研究。
Keras结合Keras后端搭建个性化神经网络模型(不用原生Tensorflow)的更多相关文章
- 手写数字识别——利用keras高层API快速搭建并优化网络模型
在<手写数字识别——手动搭建全连接层>一文中,我们通过机器学习的基本公式构建出了一个网络模型,其实现过程毫无疑问是过于复杂了——不得不考虑诸如数据类型匹配.梯度计算.准确度的统计等问题,但 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- tensor搭建--windows 10 64bit下安装Tensorflow+Keras+VS2015+CUDA8.0 GPU加速
windows 10 64bit下安装Tensorflow+Keras+VS2015+CUDA8.0 GPU加速 原文见于:http://www.jianshu.com/p/c245d46d43f0 ...
- 入门项目数字手写体识别:使用Keras完成CNN模型搭建(重要)
摘要: 本文是通过Keras实现深度学习入门项目——数字手写体识别,整个流程介绍比较详细,适合初学者上手实践. 对于图像分类任务而言,卷积神经网络(CNN)是目前最优的网络结构,没有之一.在面部识别. ...
- 使用PyTorch简单实现卷积神经网络模型
这里我们会用 Python 实现三个简单的卷积神经网络模型:LeNet .AlexNet .VGGNet,首先我们需要了解三大基础数据集:MNIST 数据集.Cifar 数据集和 ImageNet 数 ...
- BP神经网络模型与学习算法
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 建模算法(六)——神经网络模型
(一)神经网络简介 主要是利用计算机的计算能力,对大量的样本进行拟合,最终得到一个我们想要的结果,结果通过0-1编码,这样就OK啦 (二)人工神经网络模型 一.基本单元的三个基本要素 1.一组连接(输 ...
- BP神经网络模型及算法推导
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
随机推荐
- vue多个路由复用同一个组件的跳转问题(this.router.push)
因为router-view传参问题无法解决,比较麻烦. 所以我采取的是@click+this.router.push来跳转 但是现在的问题是跳转后,url改变了,但是页面的数据没有重新渲染,要刷新才可 ...
- SUM and COUNT -- SQLZOO
SUM and COUNT 注意:where语句中对表示条件的需要用单引号, 下面的译文使用的是有道翻译如有不正确,请直接投诉有道 01.Show the total population of th ...
- 预定义的 $_POST 变量用于收集来自 method="post" 的表单中的值
PHP $_POST 变量 在 PHP 中,预定义的 $_POST 变量用于收集来自 method="post" 的表单中的值. $_POST 变量 预定义的 $_POST 变量用 ...
- mit-6.828 Lab01:Booting a PC Part2 理论知识
Part 2 目录 Part 2 学习理论知识 反汇编 扇区 BIOS 启动过程总结 Boot loader启动过程总结 A20 gate 读boot/boot.S 和 boot/boot.c源码 - ...
- [转]new一个对象的过程中发生了什么?
来自:沉默哥 | 公号 :程序员小乐 链接:cnblogs.com/JackPn/p/9386182.html Java在new一个对象的时候,会先查看对象所属的类有没有被加载到内存,如果没有的话,就 ...
- Linux分布式机器 设置机器名字
查看主机的名字: hostname 1.临时修改 [root@localhost datas]# hostname slaver 临时修改,重启服务器后就不生效了 [root@localhost da ...
- 【HNOI2012】永无乡 题解(并查集+线段树合并)
题目链接 给定一张含$n$个点$m$条边的无向图,每个点有一个重要指数$a_i$.有两种操作:1.在$x$和$y$之间连一条边:2.求$x$所在连通块中重要程度第$k$小的点. ----------- ...
- 在Spring Boot中动态实现定时任务配置
原文路径:https://zhuanlan.zhihu.com/p/79644891 在日常的项目开发中,往往会涉及到一些需要做到定时执行的代码,例如自动将超过24小时的未付款的单改为取消状态,自动将 ...
- PHP 之 Composer 新手入门指南
自2012年3月1日发布以来,Composer因提供了PHP迫切需要的东西:依赖项管理而广受欢迎.实际上,Composer是将所有第三方软件(例如CSS框架,jQuery插件等)引入你的项目的一种方法 ...
- 标星7000+,这个 Python 艺术二维码生成器厉害了!
微信二维码,相信大家也并不陌生,为了生成美观的二维码,许多用户都会利用一些二维码生成工具. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手 ...