用python+sklearn(机器学习)实现天气预报数据 模型和使用
用python+sklearn机器学习实现天气预报 模型和使用
项目地址
系列教程
机器学习参考篇: python+sklearn+kaggle机器学习
用python+sklearn(机器学习)实现天气预报 准备
用python+sklearn(机器学习)实现天气预报数据 数据
用python+sklearn(机器学习)实现天气预报 模型和使用
0.前言
在上一篇教程里我们已经获取了所需要的全部数据,包括训练数据集和测试数据集,使用ProcessData()调用,所以接下来写模型的建立和预测
1.建立模型
没段代码在文章后面都会整合成一段,分段展示只是便于阅读
a.准备
引入所需要的头文件
from sklearn.ensemble import RandomForestRegressor # 随机树森林模型
import joblib # 保存模型为pkl
from sklearn.metrics import mean_absolute_error # MAE评估方法
from ProcessData import ProcessData # 取数据
选择模型
首先我们先要从模型里选择一项适合这次场景的模型,比如从决策树,随机树森林,RGB模型等等中选择,本处选用的随机树森林也就是RandomForest
选择评估方法
目前有许多的模型准确率评估方法,本处使用的是MAE,也就是mean_absolute_error 平均错误数值,就每个预测的数值离正确数值错误数值的平均数
获取数据集
这次可以从ProcessData()获取到全部的被预处理后的数据,如
# 取到数据
[X_train, X_valid, y_train, y_valid, X_test] = ProcessData()
b.建立模型
# 用XGB模型,不过用有bug
# modelX = XGBRegressor(n_estimators=1000, learning_rate=0.05, random_state=0, n_jobs=4)
# # model.fit(X_train_3, y_train_3)
# # model.fit(X_train_2, y_train_2)
# col = ["Ave_t", "Max_t", "Min_t", "Prec","SLpress", "Winddir", "Windsp", "Cloud"]
# modelX.fit(X_train, y_train,
# early_stopping_rounds=5,
# eval_set=[(X_valid, y_valid)],
# verbose=False)
# 随机树森林模型
model = RandomForestRegressor(random_state=0, n_estimators=1001)
# 训练模型
model.fit(X_train, y_train)
其中n_estimators是可自己选的,不过在多次调试后得到1001是MAE最优
c.获取模型评估结果
# 用MAE评估
score = mean_absolute_error(y_valid, preds)
d.用joblib模块保存模型
保存后的模型便于传播即可多次使用,但当前环境下的需求不大但我还是写了
# 保存模型到本地
joblib.dump(model, a)
e.封装
GetModel.py
# -*- coding: utf-8 -*-
# @Time: 2020/12/16
# @Author: Eritque arcus
# @File: GetModel.py
from sklearn.ensemble import RandomForestRegressor
import joblib
from sklearn.metrics import mean_absolute_error
from ProcessData import ProcessData
# 训练并保存模型
def GetModel(a="Model.pkl"):
"""
:param a: 模型文件名
:return:
[socre: MAE评估结果,
X_test: 预测数据集]
"""
# 取到数据
[X_train, X_valid, y_train, y_valid, X_test] = ProcessData()
# 用XGB模型,不过用有bug
# modelX = XGBRegressor(n_estimators=1000, learning_rate=0.05, random_state=0, n_jobs=4)
# # model.fit(X_train_3, y_train_3)
# # model.fit(X_train_2, y_train_2)
# col = ["Ave_t", "Max_t", "Min_t", "Prec","SLpress", "Winddir", "Windsp", "Cloud"]
# modelX.fit(X_train, y_train,
# early_stopping_rounds=5,
# eval_set=[(X_valid, y_valid)],
# verbose=False)
# 随机树森林模型
model = RandomForestRegressor(random_state=0, n_estimators=1001)
# 训练模型
model.fit(X_train, y_train)
# 预测模型,用上个星期的数据
preds = model.predict(X_valid)
# 用MAE评估
score = mean_absolute_error(y_valid, preds)
# 保存模型到本地
joblib.dump(model, a)
# 返回MAE
return [score, X_test]
2.总控
代码
这几篇文章写了零零散散好几个类,所以要写个总文件也就是启动文件串起来,然后在控制台输出
Main.py
# -*- coding: utf-8 -*-
# @Time: 2020/12/16
# @Author: Eritque arcus
# @File: Main.py
import joblib
import datetime as DT
from GetModel import GetModel
import matplotlib.pyplot as plt
# 训练并保存模型并返回MAE
r = GetModel()
print("MAE:", r[0])
# 读取保存的模型
model = joblib.load('Model.pkl')
# 最终预测结果
preds = model.predict(r[1])
# 反归一化或标准化,不过出bug了,不用
# for cols in range(0, len(preds)):
# preds[cols] = scaler.inverse_transform(preds[cols])
# sns.lineplot(data=preds)
# plt.show()
# 打印结果到控制台
print("未来7天预测")
print(preds)
all_ave_t = []
all_high_t = []
all_low_t = []
for a in range(1, 7):
today = DT.datetime.now()
time = (today + DT.timedelta(days=a)).date()
print(time.year, '/', time.month, '/', time.day, ': 平均气温', preds[a][0], '最高气温', preds[a][1],
'最低气温', preds[a][2], "降雨量", preds[a][3], "风力", preds[a][4])
all_ave_t.append(preds[a][0])
all_high_t.append(preds[a][1])
all_low_t.append(preds[a][2])
temp = {"ave_t": all_ave_t, "high_t": all_high_t, "low_t": all_low_t}
# 绘画折线图
plt.plot(range(1, 7), temp["ave_t"], color="green", label="ave_t")
plt.plot(range(1, 7), temp["high_t"], color="red", label="high_t")
plt.plot(range(1, 7), temp["low_t"], color="blue", label="low_t")
plt.legend() # 显示图例
plt.ylabel("Temperature(°C)")
plt.xlabel("day")
# 显示
plt.show()
使用方法
直接用python运行pre_weather/Main.py,就会在控制台输出预测的数据
python pre_weather/Main.py
或
在你的python代码里用joblib导入生成的模型,然后输入你的数据进行预测
(PS: 因为模型的训练用的数据日期和你预测数据的日期有关,所以不建议直接用使用非当天训练的模型进行预测,误差可能偏大)
如以下代码(在Main.py的11行):
import joblib
# 读取保存的模型
model = joblib.load('Model.pkl')
# 最终预测结果
preds = model.predict(r[1])
其中,r[1]是预测数据
或
参考Main.py,自己写一个符合你需求的启动文件
3.最后效果
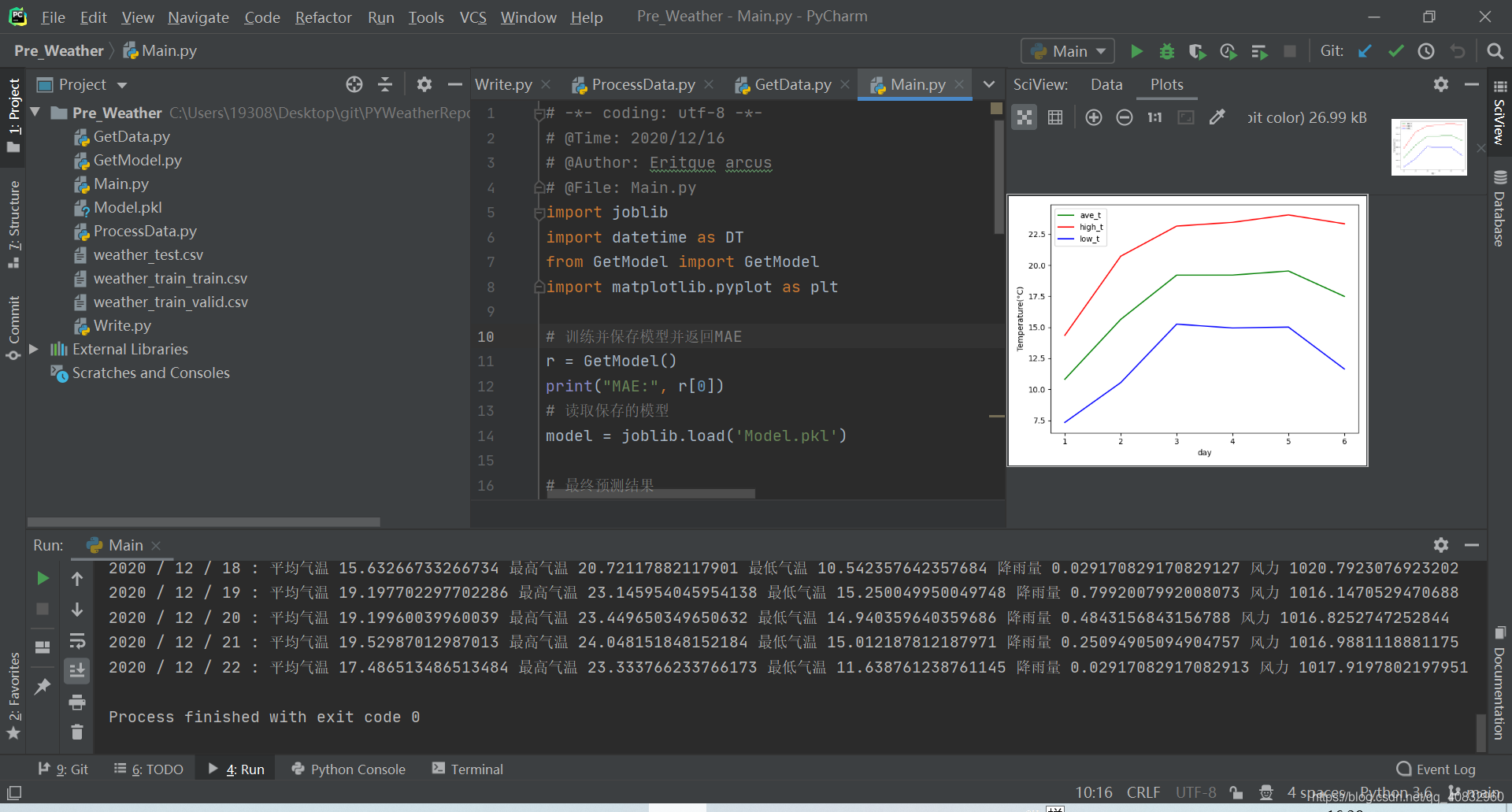
本系列教程到这就结束了,代码具体还要以github项目:PYWeatherReport为主,可能会在这个github项目上不定期优化更新
有问题可以在评论问问
-END-
用python+sklearn(机器学习)实现天气预报数据 模型和使用的更多相关文章
- 用python+sklearn(机器学习)实现天气预报数据 数据
用python+sklearn机器学习实现天气预报 数据 项目地址 系列教程 勘误表 0.前言 1.爬虫 a.确认要被爬取的网页网址 b.爬虫部分 c.网页内容匹配取出部分 d.写入csv文件格式化 ...
- 用python+sklearn(机器学习)实现天气预报 准备
用python+sklearn机器学习实现天气预报 准备 项目地址 系列教程 0.流程介绍 1. 环境搭建 a.python b.涉及到的机器学习相关库 sklearn panda seaborn j ...
- python+sklearn+kaggle机器学习
python+sklearn+kaggle机器学习 系列教程 0.kaggle 1. 初级线性回归模型机器学习过程 a. 提取数据 b.数据预处理 c.训练模型 d.根据数据预测 e.验证 今天是10 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- [Python]-sklearn模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载数据集
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- python sklearn模型的保存
使用python的机器学习包sklearn的时候,如果训练集是固定的,我们往往想要将一次训练的模型结果保存起来,以便下一次使用,这样能够避免每次运行时都要重新训练模型时的麻烦. 在python里面,有 ...
- Python: sklearn库——数据预处理
Python: sklearn库 —— 数据预处理 数据集转换之预处理数据: 将输入的数据转化成机器学习算法可以使用的数据.包含特征提取和标准化. 原因:数据集的标准化(服从均值为 ...
- 机器学习——Java调用sklearn生成好的Logistic模型进行鸢尾花的预测
机器学习是python语言的长处,而Java在web开发方面更具有优势,如何通过java来调用python中训练好的模型进行在线的预测呢?在java语言中去调用python构建好的模型主要有三种方法: ...
- 客户流失?来看看大厂如何基于spark+机器学习构建千万数据规模上的用户留存模型 ⛵
作者:韩信子@ShowMeAI 大数据技术 ◉ 技能提升系列:https://www.showmeai.tech/tutorials/84 行业名企应用系列:https://www.showmeai. ...
随机推荐
- SQL Server常用函数及命令
1.字符串函数 --ascii函数,返回字符串最左侧字符的ascii码值 SELECT ASCII('a') AS asciistr --ascii代码转换函数,返回指定ascii值对应的字符 SEL ...
- When you received Ubuntu...
翻译软件 Goldendict 安装命令: sudo apt install goldendict 在 dit -> Dictinoaries -> Websites 中添加有道的链接: ...
- 题解-CF1307G Cow and Exercise
CF1307G Cow and Exercise 给 \(n\) 点 \(m\) 边的带权有向图,边 \(i\) 为 \((u_i,v_i,w_i)\).\(q\) 次询问,每次给 \(x_i\),问 ...
- 算法(图论)——最小生成树及其题目应用(prim和Kruskal算法实现)
题目 n个村庄间架设通信线路,每个村庄间的距离不同,如何架设最节省开销? Kruskal算法 特点 适用于稀疏图,时间复杂度 是nlogn的. 核心思想 从小到大选取不会产生环的边. 代码实现 代码中 ...
- 深入理解Java虚拟机(八)——类加载机制
是什么是类加载机制 Java虚拟机将class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程就是类加载机制. 类的生命周期 一个类从加载到内存 ...
- 算法——和为K的连续子数组
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数. 输入:nums = [1,1,1], k = 2 输出: 2 , [1,1] 与 [1,1] 为两种不同的情况. 链 ...
- antDesign获取表单组件的值
子组件中: getFormValue是在点击确定按钮获取表单值得事件函数,一旦执行就会执行里边的validate()回调函数 返回的数据中有error和value两种,如果存在error那就是其中某 ...
- DVWA各等级文件上传漏洞
file upload 文件上传漏洞,攻击者可以通过上传木马获取服务器的webshell权限. 文件上传漏洞的利用是 够成功上传木马文件, 其次上传文件必须能够被执行, 最后就是上传文件的路径必须可知 ...
- 【转载】Django,学习笔记
[转自]https://www.cnblogs.com/jinbchen/p/11133225.html Django知识笔记 基本应用 创建项目: django-admin startproje ...
- 推荐系统实践 0x0f AutoRec
从这一篇开始,我们开始学习深度学习推荐模型,与传统的机器学习相比,深度学习模型的表达能力更强,并且更能够挖掘出数据中潜藏的模式.另外.深度学习模型结构也非常灵活,能够根据业务场景和数据结构进行调整.还 ...