使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的。
优势:
- 将下载图片转换成通用的JPG和RGB格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
- 异步下载
- ......
工作流程:
- 爬取一个Item,将图片的URLs放入
image_urls字段 - 从
Spider返回的Item,传递到Item Pipeline - 当
Item传递到ImagePipeline,将调用Scrapy 调度器和下载器完成image_urls中的url的调度和下载。 - 图片下载成功结束后,图片下载路径、url和校验和等信息会被填充到images字段中。
实现方式:
- 自定义pipeline,优势在于可以重写ImagePipeline类中的实现方法,可以根据情况对照片进行分类;
- 直接使用ImagePipeline类,简单但不够灵活;所有的图片都是保存在full文件夹下,不能进行分类
实践:爬取http://699pic.com/image/1/这个网页下的前四个图片集(好进行分类演示)

这里使用方法一进行实现:
步骤一:建立项目与爬虫
1.创建工程:scrapy startproject xxx(工程名)
2.创建爬虫:进去到上一步创建的目录下:scrapy genspider xxx(爬虫名) xxx(域名)
步骤二:创建start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl 699pic(爬虫名)".split(" "))
步骤三:设置settings
1.关闭机器人协议,改成False
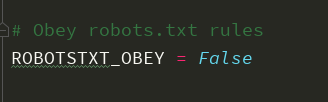
2.设置headers
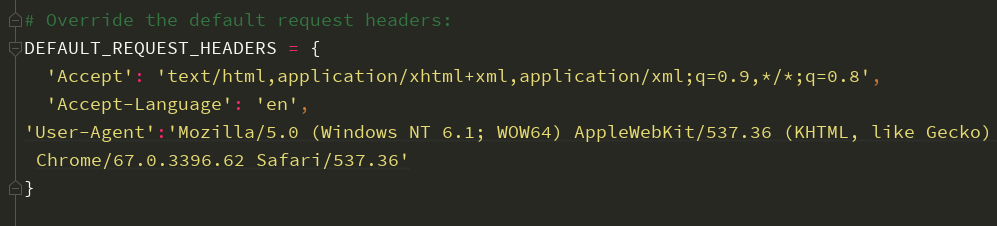
3.打开ITEM_PIPELINES
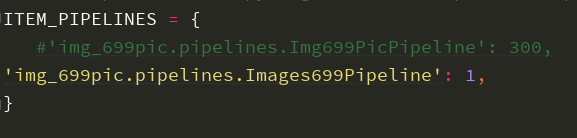
将项目自动生成的pipelines注释掉,黄色部分是下面步骤中自己写的pipeline,这里先不写。
步骤四:item
class Img699PicItem(scrapy.Item):
# 分类的标题
category=scrapy.Field()
# 存放图片地址
image_urls=scrapy.Field()
# 下载成功后返回有关images的一些相关信息
images=scrapy.Field()
步骤五:写spider
import scrapy
from ..items import Img699PicItem
import requests
from lxml import etree class A699picSpider(scrapy.Spider):
name = '699pic'
allowed_domains = ['699pic.com']
start_urls = ['http://699pic.com/image/1/']
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
} def parse(self, response):
divs=response.xpath("//div[@class='special-list clearfix']/div")[0:4]
for div in divs:
category=div.xpath("./a[@class='special-list-title']//text()").get().strip()
url=div.xpath("./a[@class='special-list-title']/@href").get().strip()
image_urls=self.parse_url(url)
item=Img699PicItem(category=category,image_urls=image_urls)
yield item def parse_url(self,url):
response=requests.get(url=url,headers=self.headers)
htmlElement=etree.HTML(response.text)
image_urls=htmlElement.xpath("//div[@class='imgshow clearfix']//div[@class='list']/a/img/@src")
return image_urls
步骤六:pipelines
import os
from scrapy.pipelines.images import ImagesPipeline
from . import settings class Img699PicPipeline(object):
def process_item(self, item, spider):
return item class Images699Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 这个方法是在发送下载请求之前调用的,其实这个方法本身就是去发送下载请求的
request_objs=super(Images699Pipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item=item
return request_objs def file_path(self, request, response=None, info=None):
# 这个方法是在图片将要被存储的时候调用,来获取这个图片存储的路径
path=super(Images699Pipeline, self).file_path(request,response,info)
category=request.item.get('category')
image_store=settings.IMAGES_STORE
category_path=os.path.join(image_store,category)
if not os.path.exists(category_path):
os.makedirs(category_path)
image_name=path.replace("full/","")
image_path=os.path.join(category_path,image_name)
return image_path
步骤七:返回到settings中
1.将黄色部分填上

2.存放图片的总路径
IMAGES_STORE=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
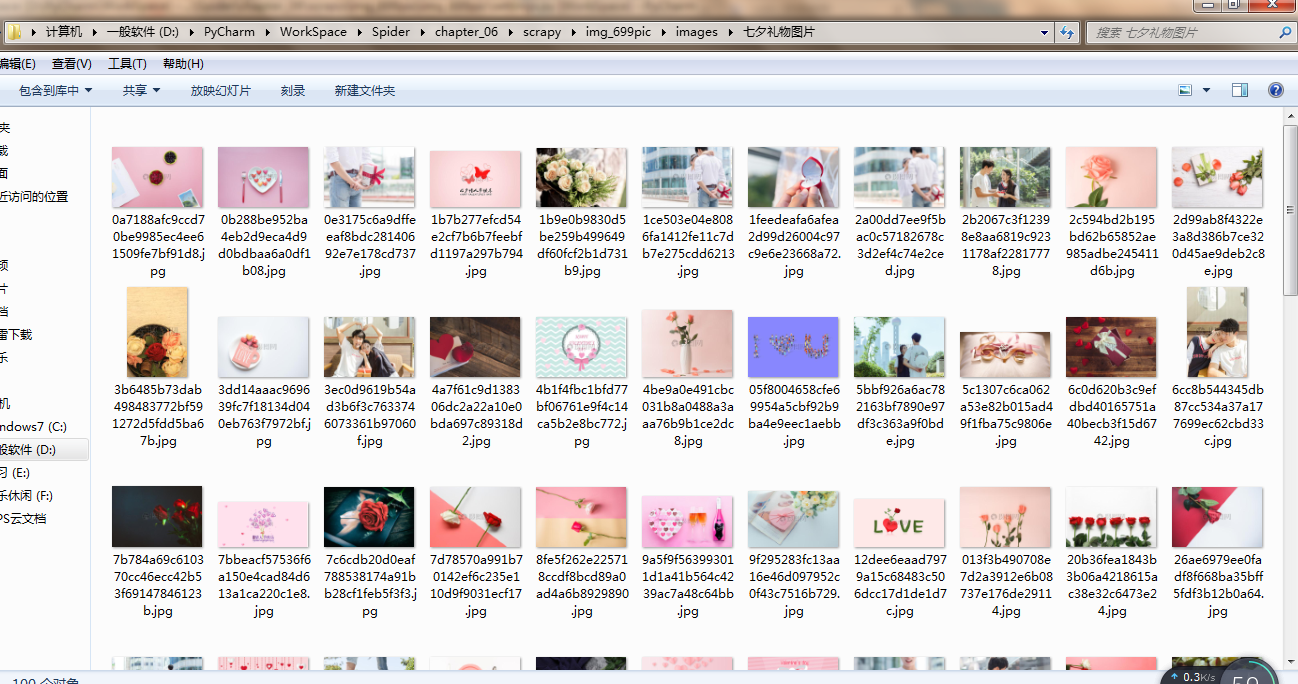
最终结果:

使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。的更多相关文章
- 通过scrapy内置的ImagePipeline下载图片到本地、并提取本地保存地址
1.通过scrapy内置的ImagePipeline下载图片到本地 2.获取图片保存本地的地址 1.通过scrapy内置的ImagePipeline下载图片到本地 1)在settings.py中打开 ...
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- 使用 Scrapy 的 ImagesPipeline 下载图片
下载 百度贴吧-动漫壁纸吧 所有图片 定义item Spider spider 只需要得到图片的url,必须以列表的形式给管道处理 class PictureSpiderSpider(scrapy.S ...
- (二)scrapy 中如何自定义 pipeline 下载图片
这里以一个很简单的小爬虫为例,爬取 壹心理 网站的阅读页面第一页的所有文章及其对应的图片,文章页面如下: 创建项目 首先新建一个 scrapy 项目,安装好相关依赖(步骤可参考:scrapy 安装及新 ...
- scrapy 在爬取过程中抓取下载图片
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了 最好是保存,在使用其他方法下载 我这个是在 https://blog.csd ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
- 使用官方组件下载图片,保存到MySQL数据库,保存到MongoDB数据库
需要学习的地方,使用官方组件下载图片的用法,保存item到MySQL数据库 需要提前创建好MySQL数据库,根据item.py文件中的字段信息创建相应的数据表 1.items.py文件 from sc ...
- 使用scrapy框架爬取图片网全站图片(二十多万张),并打包成exe可执行文件
目标网站:https://www.mn52.com/ 本文代码已上传至git和百度网盘,链接分享在文末 网站概览 目标,使用scrapy框架抓取全部图片并分类保存到本地. 1.创建scrapy项目 s ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
随机推荐
- PAT1067. Sort with Swap(0, *) (25) 并查集
PAT1067. Sort with Swap(0, *) (25) 并查集 题目大意 给定一个序列, 只能进行一种操作: 任一元素与 0 交换位置, 问最少需要多少次交换. 思路 最优解就是每次 0 ...
- $_GET 与 $POST
$_GET就是地址传值,用 '?' 开始传值,多个值间用 '&' 号分隔,多用于简单的传值,比如说看新闻需要新闻id一般就会用地址传值, $_GET的好处是传值可见,也就是只要一个地址就ok了 ...
- iOS自动打开闪光灯
现在好多应有都具备扫码功能,为了减少用户操作,一般会在光线比较暗的时候,自动打开闪光灯: 1.导入头文件 #import <AVFoundation/AVFoundation.h> #im ...
- jzoj100029. 【NOIP2017提高A组模拟7.8】陪审团(贪心,排序)
Description 陪审团制度历来是司法研究中的一个热议话题,由于陪审团的成员组成会对案件最终的结果产生巨大的影响,诉讼双方往往围绕陪审团由哪些人组成这一议题激烈争夺. 小 W 提出了一个甲乙双方 ...
- CentOS7——vi编辑保存
按ESC键 跳到命令模式,然后: :w 保存文件但不退出vi :w file 将修改另外保存到file中,不退出vi :w! 强制保存,不推出vi :wq 保存文件并退出vi :wq! 强制保存文件, ...
- haproxy+keepalived主备与双主模式配置
Haproxy+Keepalived主备模式 主备节点设置 主备节点上各安装配置haproxy,配置内容且要相同 global log 127.0.0.1 local2 chroot /var/lib ...
- 汇编:将指定的内存中连续N个字节填写成指定的内容
1.loop指令实现 ;=============================== ;循环程序设计 ;将制定内存中连续count个字节填写成指定内容(te) ;loop指令实现 DATAS SEG ...
- 汇编:采用址表的方法编写程序实现C程序的switch功能
//待实现的C程序 1 void main() { ; -) { : printf("excellence"); break; : printf("good") ...
- Vue报错 [Vue warn]: Cannot find element
在前端开发全面进入前端的时代 作为一个合格的前端开发工作者 框架是不可或缺的Vue React Anguar 作为前端小白,追随大佬的脚步来到来到博客园,更新现在正在学习的Vue 注 : 相信学习Vu ...
- css3圆角矩形、盒子阴影
css3圆角矩形 div{ width: 200px; height: 200px; border: #f00 solid 1px; margin-bottom: 10px; } 1.设置 borde ...