使用 Scrapy 的 ImagesPipeline 下载图片
下载 百度贴吧-动漫壁纸吧 所有图片
定义item

Spider
spider 只需要得到图片的url,必须以列表的形式给管道处理
class PictureSpiderSpider(scrapy.Spider):
name = 'picture_spider'
allowed_domains = ['tieba.baidu.com']
start_urls = ['https://tieba.baidu.com/f?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8']
def parse(self, response):
# 贴吧中一页帖子的ID和标题
theme_urls = re.findall(r'<a rel="noreferrer" href="/p/(\d+)" title="(.*?)" target="_blank" class="j_th_tit ">',
response.text, re.S)
for theme in theme_urls:
# 帖子的url
theme_url = 'https://tieba.baidu.com/p/' + theme[0]
# 进入各个帖子
yield scrapy.Request(url=theme_url, callback=self.parse_theme)
# 贴吧下一页的url
next_url = re.findall(
r'<a href="//tieba.baidu.com/f\?kw=%E5%8A%A8%E6%BC%AB%E5%A3%81%E7%BA%B8&ie=utf-8&pn=(\d+)" class="next pagination-item " >下一页></a>',
response.text, re.S)
if next_url:
next_url = self.start_urls[0] + '&pn=' + next_url[0]
yield scrapy.Request(url=next_url)
# 下载每个帖子里的所有图片
def parse_theme(self, response):
item = PostBarItem()
# 每个贴子一页图片的缩略图的url
pic_ids = response.xpath('//img[@class="BDE_Image"]/@src').extract()
# 用列表来装图片的url
item['pic_urls'] = []
for pic_url in pic_ids:
# 取出每张图片的名称
item['pic_name'] = pic_url.split('/')[-1]
# 图片URL
url = 'http://imgsrc.baidu.com/forum/pic/item/' + item['pic_name']
# 将url添加进列表
item['pic_urls'].append(url)
# 将item交给pipelines下载
yield item
# 下完一页图片后继续下一页
next_url = response.xpath('//a[contains(text(),"下一页")]/@href').extract_first()
if next_url:
yield scrapy.Request('https://tieba.baidu.com' + next_url, callback=self.parse_theme)
ImagesPipeline
- from scrapy.pipelines.images import ImagesPipeline
- 继承ImagesPipeline,重写get_media_requests()和file_path()方法
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class PostBarPipeline(ImagesPipeline):
# 需要headers的网站,再使用
headers = {
'User-Agent': '',
'Referer': '',
}
def get_media_requests(self, item, info):
for pic_url in item['pic_urls']:
# 为每个url生成一个Request
yield scrapy.Request(pic_url)
# 需要请求头的时候,添加headers参数
# yield scrapy.Request(pic_url, headers=self.headers)
def file_path(self, request, response=None, info=None):
# 重命名(包含后缀名),若不重写这函数,图片名为哈希
pic_path = request.url.split('/')[-1]
return pic_path
settings文件
激活管道

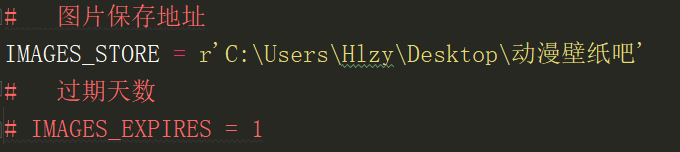
设置图片保存地址
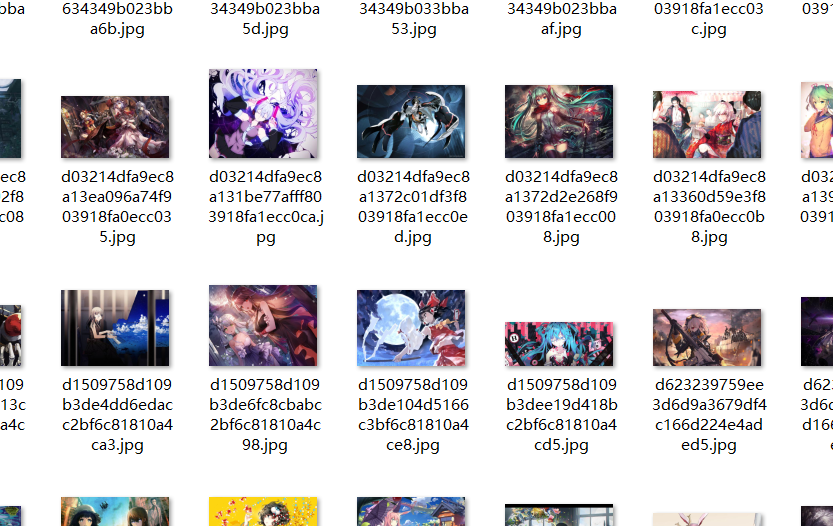
运行结果
使用 Scrapy 的 ImagesPipeline 下载图片的更多相关文章
- Scrapy框架学习 - 使用内置的ImagesPipeline下载图片
需求分析需求:爬取斗鱼主播图片,并下载到本地 思路: 使用Fiddler抓包工具,抓取斗鱼手机APP中的接口使用Scrapy框架的ImagesPipeline实现图片下载ImagesPipeline实 ...
- 使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的. 优势: 将下载图片转换成通用的JPG和RGB格式 避免重复下载 缩略图生成 图片大小过滤 异步下载 . ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
- scrapy批量下载图片
# -*- coding: utf-8 -*- import scrapy from rihan.items import RihanItem class RihanspiderSpider(scra ...
- scrapy下载图片到自己的目录,创建缩略图,存储入库
环境和工具:python2.7,scrapy 实验网站:http://www.27270.com/tag/333.html 爬去所有兔女郎图片,下面的推荐需要过滤 逻辑:分析网站信息,下载图片和入库 ...
- 通过scrapy内置的ImagePipeline下载图片到本地、并提取本地保存地址
1.通过scrapy内置的ImagePipeline下载图片到本地 2.获取图片保存本地的地址 1.通过scrapy内置的ImagePipeline下载图片到本地 1)在settings.py中打开 ...
- Scrapy Item用法示例(保存item到MySQL数据库,MongoDB数据库,使用官方组件下载图片)
需要学习的地方: 保存item到MySQL数据库,MongoDB数据库,下载图片 1.爬虫文件images.py # -*- coding: utf-8 -*- from scrapy import ...
- Scrapy——6 APP抓包—scrapy框架下载图片
Scrapy——6 怎样进行APP抓包 scrapy框架抓取APP豆果美食数据 怎样用scrapy框架下载图片 怎样用scrapy框架去下载斗鱼APP的图片? Scrapy创建下载图片常见那些问题 怎 ...
随机推荐
- C语言笔记 02_基本语法&数据类型&变量
基本语法 令牌 C 程序由各种令牌组成,令牌可以是关键字.标识符.常量.字符串值,或者是一个符号.例如,下面的 C 语句包括五个令牌: printf("Hello, World! \n&qu ...
- C# List与Dictionary相互转换与高效查找
TestModel类定义: public class TestModel{ public int Id { get; set; } public string Name { get; se ...
- 设计模式之观察者模式C#实现
说明:主要参考<Head First设计模式(中文版)>,使用C#代码实现. 代码:Github 1.观察者模式UML图 2.气象监测类图 3.气象监测代码(书中C#版) 3.1 Obse ...
- Git实战指南----跟着haibiscuit学Git(第六篇)
笔名: haibiscuit 博客园: https://www.cnblogs.com/haibiscuit/ Git地址: https://github.com/haibiscuit?tab=re ...
- MySQL8.0+常用命令
开启远程访问 通过以下命令开启root用户远程访问权限: CREATE USER 'root'@'%' IDENTIFIED BY 'password'; GRANT ALL ON *.* TO 'r ...
- WordPress 文件下载漏洞
Google dork:inurl:"/wp-content/themes/liberator/inc/php/download.php" exploit:https://www. ...
- std::map自定义类型key
故事背景:最近的需求需要把一个结构体struct作为map的key,时间time作为value,定义:std::map<struct, time> _mapTest; 技术调研:众所周知, ...
- InnoDB On-Disk Structures(五)-- Redo Log & Undo Logs (转载)
1.Redo Log The redo log is a disk-based data structure used during crash recovery to correct data wr ...
- 一步一步创建聊天程序2-利用epoll来创建简单的聊天室
如图,这个是看视频时,最后的作业,除了客户端未使用select实现外,其它的要求都有简单实现. 服务端代码如下: #include <stdio.h> #include <strin ...
- vue使用--vuex快速学习与使用
什么是vuex? Vuex核心概念 Vuex安装与使用 1.安装 2.目录结构与vuex引入 3.store中变量的定义.管理.派生(getter) 4.vuex辅助函数的使用说明 Vuex刷新数据丢 ...