sqoop学习3(数据导入乱码问题)
sqoop将mysql数据库中数据导入hdfs或hive中后中文乱码问题解决办法
[root@spark1 ~]# vi /etc/my.cnf 修改配置文件
在文件内的[mysqld]和client下增加如下1行
[mysqld]
default-character-set=utf8
[client]
default-character-set=utf8
然后在创建数据库和表时都指定字符集为utf8
mysql> create database wujiadong1 character set utf8;
mysql> create table stud_info(
-> stud_code varchar(50) not null,
-> stud_name varchar(50) not null,
-> stud_gend varchar(50) not null default 'M',
-> birthday date null,
-> log_date date null,
-> orig_addr varchar(50) null,
-> lev_date date null,
-> college_code varchar(50) null,
-> college_name varchar(50) null,
-> state varchar(50) null,
-> primary key(stud_code)
-> )character set utf8;
mysql> load data local infile '/root/hive_test/stud_info.csv' into table stud_info
-> fields terminated by ','
-> lines terminated by '\n'
-> ignore 1 lines;
mysql> select * from stud_info; #看中文字符能否正常显示
再向hdfs中导入数据
[root@spark1 ~]# sqoop import --connect jdbc:mysql://192.168.220.144:3306/wujiadong1 --username root --table stud_info --target-dir 'hdfs://spark1:9000/user/sqoop_test1' -m 1
[root@spark1 ~]# hadoop fs -lsr /user/sqoop_test1
[root@spark1 ~]# hadoop fs -cat /user/sqoop_test1/part-m-00000

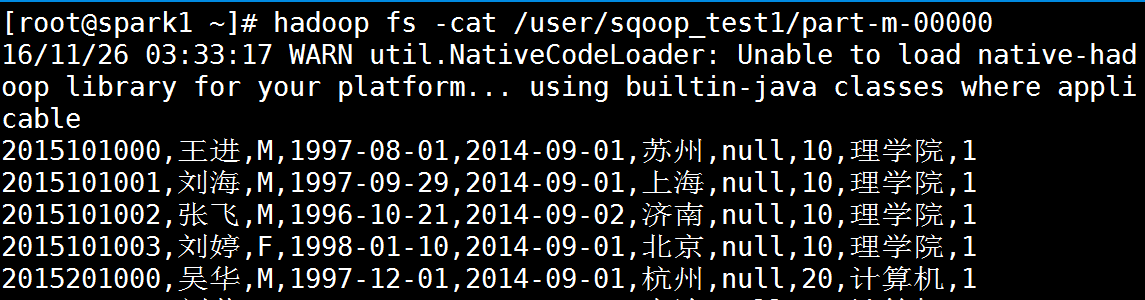
mysql数据导入hdfs中中文乱码问题总结
- 修改mysql里面的my.conf文件
- 创建数据库,指定字符集是utf8
- 再新的数据库里面创建表,在create table语句里面指定字符集是 utf8
- 插入中文汉字记录
- select看到中文是正常的
- 依次完成这些操作以后,再用sqoop导入
导入hdfs解决中文乱码问题后,再去导入hive中就没出现乱码问题了,所以应该是一样的解决方法
mysql中的编码查看和修改方法
查看编码方式
mysql> show variables like 'collation_%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | latin1_swedish_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
mysql> show variables like 'character_set_%'; 查看mysql数据库默认编码
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
修改编码方式在/etc/my.cnf这个文件中修改
[root@spark1 ~]# vi /etc/my.cnf
root@spark1 ~]# service mysqld restart 重启mysql
查看是否变成utf8
mysql> \s
--------------
mysql Ver 14.14 Distrib 5.1.73, for redhat-linux-gnu (x86_64) using readline 5.1
Connection id: 6
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.1.73 Source distribution
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: utf8
Db characterset: utf8
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /var/lib/mysql/mysql.sock
Uptime: 22 min 3 sec
Threads: 1 Questions: 59 Slow queries: 0 Opens: 20 Flush tables: 1 Open tables: 9 Queries per second avg: 0.44
--------------
mysql> show variables like "char%";
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
mysql> show variables like "colla%";
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3 rows in set (0.00 sec)
sqoop学习3(数据导入乱码问题)的更多相关文章
- sqoop将oracle数据导入hdfs集群
使用sqoop将oracle数据导入hdfs集群 集群环境: hadoop1.0.0 hbase0.92.1 zookeeper3.4.3 hive0.8.1 sqoop-1.4.1-incubati ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- 利用sqoop将hive数据导入导出数据到mysql
一.导入导出数据库常用命令语句 1)列出mysql数据库中的所有数据库命令 # sqoop list-databases --connect jdbc:mysql://localhost:3306 ...
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- 使用 sqoop 将mysql数据导入到hive表(import)
Sqoop将mysql数据导入到hive表中 先在mysql创建表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` varchar() ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- 使用sqoop将mysql数据导入到hadoop
hadoop的安装配置这里就不讲了. Sqoop的安装也很简单. 完成sqoop的安装后,可以这样测试是否可以连接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): ...
- python脚本 用sqoop把mysql数据导入hive
转:https://blog.csdn.net/wulantian/article/details/53064123 用python把mysql数据库的数据导入到hive中,该过程主要是通过pytho ...
- 如何利用sqoop将hive数据导入导出数据到mysql
运行环境 centos 5.6 hadoop hive sqoop是让hadoop技术支持的clouder公司开发的一个在关系数据库和hdfs,hive之间数据导入导出的一个工具. 上海尚学堂 ...
随机推荐
- 图像处理之Canny边缘检測
图像处理之Canny 边缘检測 一:历史 Canny边缘检測算法是1986年有John F. Canny开发出来一种基于图像梯度计算的边缘 检測算法,同一时候Canny本人对计算图像边缘提取学科的发展 ...
- 回溯法——n后问题
问题描述: 在n*n的棋盘上放置彼此不受攻击的n个皇后.按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子.n后问题等价于在n*n格的棋盘上放置n个皇后,任何2个皇后不放在同一行 ...
- 3N Numbers
D - 3N Numbers Time limit : 2sec / Memory limit : 256MB Score : 500 points Problem Statement Let N b ...
- VS2010编译报错FileTracker error FTK1011
系统重装,TFS重新映射,编译项目报错,出现 FileTracker error FTK1011,折腾半天未搞定,网上找到答案,可能是路径更改导致(未验证): 修改MSNET.Framework 目标 ...
- sql的reader方法注意事项
如果恢复注释. 在数据只有一条时,list将始终为空 原因很简单. 第一个红框已经跑完了.第二次调用的时候,就是第二条了,此时数据为空
- studio显示Surface: getSlotFromBufferLocked: unknown buffer: 0xa2a58be0
根据查询外网资料来看,出现这个错误的原因大致是换个模拟器或者物理机就可以了. 因为我使用的是安卓6.0,貌似都会出现这类的问题. 但是不影响程序运行.
- Java基础—反射(转载)
转载自: JAVA反射与注解 JAVA反射 主要是指程序可以访问,检测和修改它本身状态或行为的一种能力,并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义. 反射机制是什么 反射 ...
- boost之操作系统相关
1.保存I/O流 下面这段代码cout会失效,原因是cout重定向之后失效. #include <iostream> #include <fstream> using name ...
- 分布式计算开源框架Hadoop入门实践(一)
在SIP项目设计的过程中,对于它庞大的日志在开始时就考虑使用任务分解的多线程处理模式来分析统计,在我从前写的文章<Tiger Concurrent Practice --日志分析并行分解设计与实 ...
- 【转】jQuery插件之ajaxFileUpload
转自:http://www.cnblogs.com/kissdodog/archive/2012/12/15/2819025.html 说在前头,本文出自上面的作者,只是以前存的一些网址不见了,怕以后 ...