机器学习之scikit-learn库
前面讲到了,这个库适合学习,轻量级,所以先学它。
安装就不讲了,简单。不过得先安装numpy和pandas库才能安装scikit-learn库。
如果安装了anaconda得话,会自带有这个库。
----------------------------------------------------------------------------------------------------------
1、首先进行字典特征提取
作用:对字典数据进行特征值提取。
API:sklearn.feature_extraction.DictVectorizer

流程:1、实例化类 DictVectorizer()
2、调用fit_transorm方法输入数据并转换
上代码:
from sklearn.feature_extraction import DictVectorizer def dictvec():
'''
字典数据抽取
:return: None
'''
# 实例化
dict = DictVectorizer() # 调用fit_transorm
data = dict.fit_transform([{'name':'X','score': 80},{'name':'Y','score': 90},{'name':'Z','score': 100}]) print(data) return None if __name__ == '__main__':
dictvec()

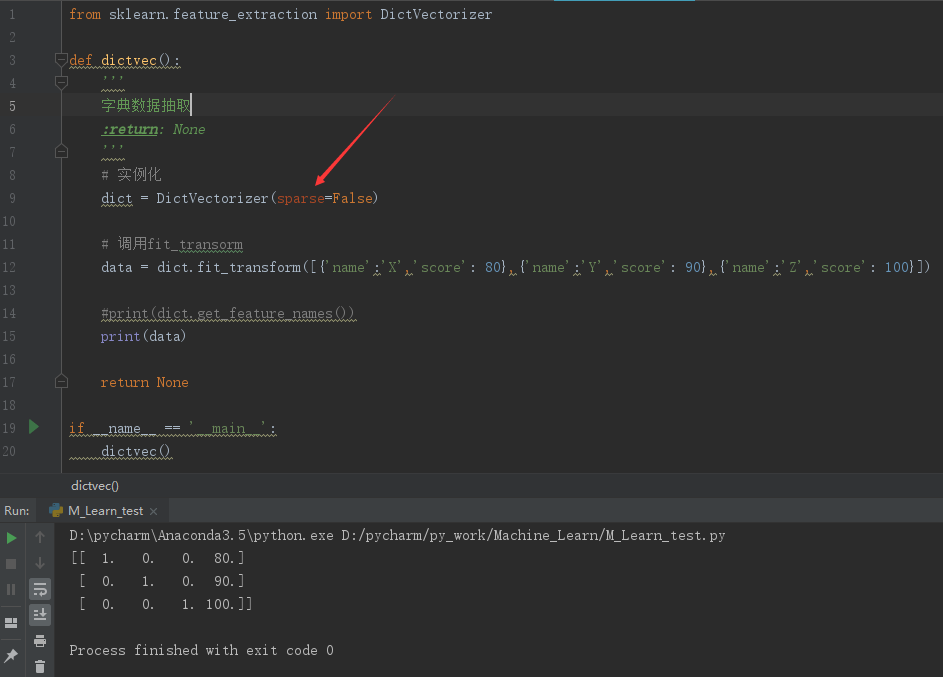
可以看到输出结果是一个Sparse矩阵,前面得括号里面是坐标,后面的数字是这个坐标的值,比如:(0,0) 1.0 表示在第0行0列的值为1。
其他没有列出来的坐标如(0,1)、(0,2)等的值默认为0.
将DictVectorizer()中的sparse参数设置为False可以使得结果容易可读。
2、文本特征提取
作用:对文本数据进行提取 API:sklearn.feature_extraction.text.CountVectorizer上代码:假设有两篇文章分别为:'life is shortm,i like Python'和'life is too long, i dislike Python'
from sklearn.feature_extraction.text import CountVectorizer def countvec():
'''
对文本进行特征值提取
:return: None
'''
# 实例化
cv = CountVectorizer() # 调用fit_transorm
data = cv.fit_transform(['life is shortm,i like Python','life is too long, i dislike Python']) print(data) return None if __name__ == '__main__':
countvec()
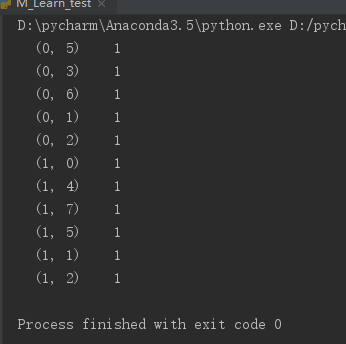
结果和字典提取是一样的,值得注意的是这里要将parse矩阵转换成比较容易读的二维矩阵的话,是在结果中调用toarray(),而不是设置sparse参数
如下图:
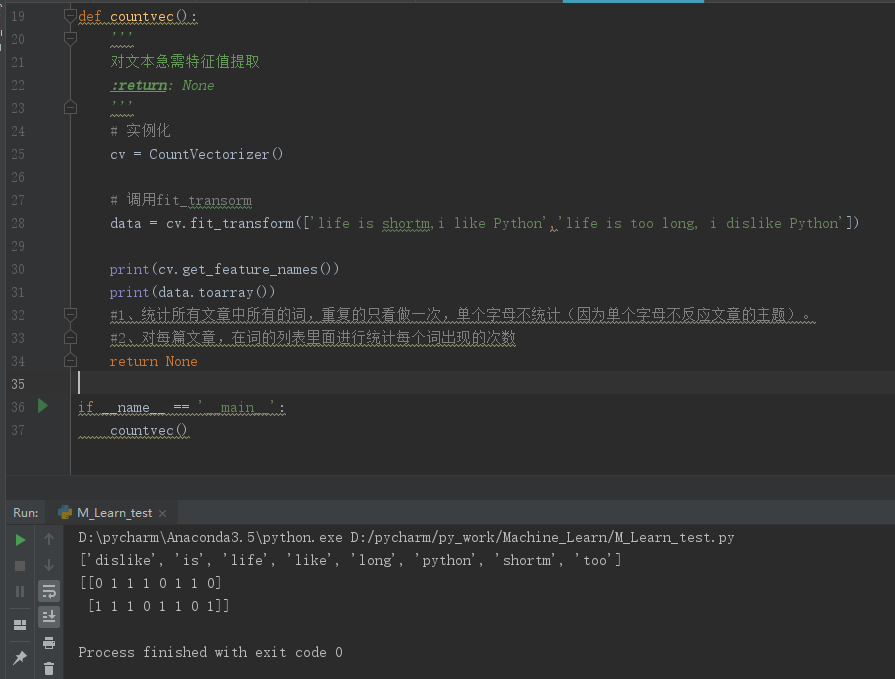
get_feature_names()返回一个列表,列表里面是提取的所有特征(本例中提取出了8个单词,单个字母不统计)。
结果中有两个列表,每个列表对应一篇文章。第一个列表中第一个0表示第一篇文章中dislike没有出现,第一个列表中第一个1表示is出现了,依次类推
机器学习之scikit-learn库的更多相关文章
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 机器学习三剑客之Numpy库基本操作
NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
随机推荐
- Github配合Jenkins,实现vue等前端项目的自动构建与发布
本篇文章前端项目以vue为例(其实前端工程化项目的操作方法都相同),部署在Linux系统上(centos). 之前做前端项目的部署,一直都是手动运行打包命令,打包完.再使用FTP.Xshell等这类的 ...
- redis相关缓存知识
Redis redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorte ...
- 网页布局——grid弹性网格布局
网格布局(Grid)是最强大的 CSS 布局方案. Flexbox 是为一维布局设计的,而 Grid 是为二维布局设计. grid目前兼容性目前还可以,主流浏览器对它的支持力度很大,ie9,10宣布它 ...
- 复杂模型可解释性方法——LIME
一.模型可解释性 近年来,机器学习(深度学习)取得了一系列骄人战绩,但是其模型的深度和复杂度远远超出了人类理解的范畴,或者称之为黑盒(机器是否同样不能理解?),当一个机器学习模型泛化性能很好时 ...
- C语言-正序输出一个一个多位数
//正序输出一个多位数,所有的数字中间用空格分隔 int main() { ;//是可变化的 ; int d; int t =x; //先计算x的位数 ){ t /= ; mask *=; } pri ...
- conversion function——转换函数
类型转换函数 与 explicit关键字 1.类型转换函数 在C++中,可以使用构造函数将一个指定类型的数据转换为类的对象,也可以使用类型转换函数 (type conversion function) ...
- EF通过导航属性取出从表的集合后,无法删除子表
主从表是配了级联删除的,如果通过导航属性去除从表明细删除时将报错The relationship could not be changed because one or more of the for ...
- Python_文本的读写操作
[需求] 1. 获取文本内容,提取内容中的可用信息,对信息进行清洗等一系列处理 2. 算法输出一些内容,保存到文本文件中,便于使用 [函数] 在Python中open()函数是用来打开文件的,包括文本 ...
- [插件化开发] Poc之后,我选择放弃OSGI
Poc之后,我选择放弃OSGI TIPS: 如贵司允许重构老系统或者允许使用OSGI的第三方框架改造所带来的投入成本,并且评估之后ROI乐观,那么还是可以使用的. Runtime Version 以下 ...
- 阻塞IO模型
#include<stdio.h> #include<stdlib.h> #include<string.h> #include<unistd.h> # ...