(一)LinkedList集合解析及手写集合
一、LinkedList集合特点
| 问题 | 结 论 |
| LinkedList是否允许空 | 允许 |
| LinkedList是否允许重复数据 | 允许 |
| LinkedList是否有序 | 有序 |
| LinkedList是否线程安全 | 非线程安全 |
LinkedList集合底层是由双向链表组成,而不是双向循环链表。
有一个头结点和一个尾结点,我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
二、LinkedList集合底层实现
1.什么是链表
链表原是一种线性的存储结构,意思是将要存储的数据存在一个存储单元里面,这个存储单元里面除了存放有待存储的数据以外,还存储有其下一个存储单元的地址(下一个存储单元的地址是必要的,有些存储结构还存放有其前一个存储单元的地址),每次查找数据的时候,通过某个存储单元中的下一个存储单元的地址寻找其后面的那个存储单元。
2. 什么是双向链表
双向链表也是链表的一种,它每个数据结点中都有两个结点,分别指向其直接前驱和直接后继。所以我们从双向链表的任意一个结点开始都可以很方便的访问其前驱元素和后继元素。
3.双向链表的定义
双向链表也是链表的一种,它每个数据结点中都有两个结点,分别指向其直接前驱和直接后继。所以我们从双向链表的任意一个结点开始都可以很方便的访问其前驱元素和后继元素。
4.双向链表的存储结构
双向链表也是采用的链式存储结构,它与单链表的区别就是每个数据结点中多了一个指向前驱元素的指针域 ,它的存储结构如下图
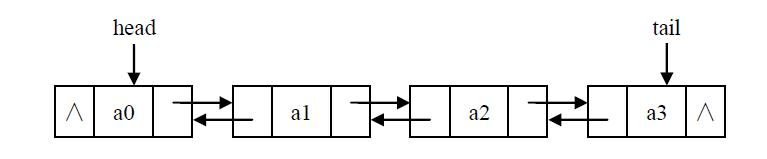
当双向链表只有一个结点的时候它的存储结构如下:
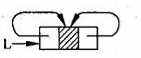
头节点和尾结点指向同一个元素。
三.LinkedList源码分析
1.构造方法,无参构造,有参构造。
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
// 调用无参构造函数
this();
// 添加集合中所有的元素
addAll(c);
}
2.Node结点组成
private static class Node<E> {
E item; // 数据域
Node<E> next; // 后继
Node<E> prev; // 前驱
// 构造函数,赋值前驱后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3.添加元素 add方法
public boolean add(E e) {
linkLast(e);// // 添加元素到末尾
return true;
}
void linkLast(E e) {
// 保存尾结点,l为final类型,不可更改
final Node<E> l = last;
// 新生成结点的前驱为l,后继为null
final Node<E> newNode = new Node<>(l, e, null);
// 重新赋值尾结点
last = newNode;
if (l == null) // 尾结点为空
first = newNode; // 赋值头结点
else // 尾结点不为空
l.next = newNode; // 尾结点的后继为新生成的结点
// 大小加1
size++;
// 结构性修改加1
modCount++;
}
3.查询元素E get(int index)获取指定节点数据
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) { // 插入位置在前半段
Node<E> x = first;
for (int i = 0; i < index; i++) // 从头结点开始正向遍历
x = x.next;
return x; // 返回该结点
} else { // 插入位置在后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
x = x.prev;
return x; // 返回该结点
}
}
4.remove移除结点时
E unlink(Node<E> x) {
// 保存结点的元素
final E element = x.item;
// 保存x的后继
final Node<E> next = x.next;
// 保存x的前驱
final Node<E> prev = x.prev;
if (prev == null) { // 前驱为空,表示删除的结点为头结点
first = next; // 重新赋值头结点
} else { // 删除的结点不为头结点
prev.next = next; // 赋值前驱结点的后继
x.prev = null; // 结点的前驱为空,切断结点的前驱指针
}
if (next == null) { // 后继为空,表示删除的结点为尾结点
last = prev; // 重新赋值尾结点
} else { // 删除的结点不为尾结点
next.prev = prev; // 赋值后继结点的前驱
x.next = null; // 结点的后继为空,切断结点的后继指针
}
x.item = null; // 结点元素赋值为空
// 减少元素实际个数
size--;
// 结构性修改加1
modCount++;
// 返回结点的旧元素
return element;
}
四.手写LinkedList代码:
手写源码主要是为了便于对LinkedList集合的更好理解,主要对add(),remove,add(index,element) ,get(i)这些方法进行简单的写法,写法比较通俗更便于理解。具体可以参考下面的代码。
1.自定义LinkedList集合。
package com.zzw.cn.springmvc.linkList; /**
* @author Simple
* @date 16:58 2019/9/5
* @description 手写LinkList集合
* 思路:
* 1.集合add
* 2.remove
* 3.add(index,element)
*/ public class AnLinkeList<E> {
private Node first;//第一个节点值
private Node last;//最后一个节点值
int size;//集合长度 /**
* 添加
*
* @param e
*/
public void add(E e) {
Node node = new Node();
//增加时判断集合是否为null 1.为null时候位置指向不同
node.object = e;
if (null == first) { //第一个元素添加是第一个节点和最后一个节点指向位置都为第一个
first = node;
} else {
//存放上一个节点内容
node.prev = last;
//将上一个节点值指向当前节点
last.next = node;
}
//对最后一个节点赋值
last = node;
size++;
} public E get(int index) {
Node node = null;
if (null != first) {
node = first;
//循环遍历指向最后一个节点
for (int i = 0; i < index; i++) {
node = node.next;
}
return (E) node.object;
}
return null;
} public Node getNode(int index) {
Node node = null;
if (null != first) {
node = first;
//循环遍历指向最后一个节点
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
}
return null;
} //删除
public void remove(int index) {
//1找到当前元素 删除时,将当前元素B的pre指向上一个A节点,将上一个元素A的节点指向当前元素B的next节点。
checkElementIndex(index);
Node node = getNode(index);
Node prevNode = node.prev;
Node nextNode = node.next;
if (prevNode.next != null) {
prevNode.next = nextNode;
}
if (nextNode != null) {
nextNode.prev = prevNode;
}
size--; } private boolean isElementIndex(int index) {
return index >= 0 && index <= size;
} private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException("越界啦!");
} private void add(int index, E e) {
checkElementIndex(index);
if (index == size)
add(e);
else
addEle(index, e); } private void addEle(int index, E e) {
/**
*
* 新增E 上一个节点是A 下一个节点是B
* A->next=E
* E->pre=A
* E->next=B
* B->pre=E
*/
Node newNode = new Node();
newNode.object = e;
Node oldNode = getNode(index);
Node oldPrev = oldNode.prev;
//当前节点上一个对应新节点
oldNode.prev = newNode;
//如果当前节点为第一个时候
if (oldPrev == null) {
first = newNode;
} else {
//新节点的下一个对应当前节点
oldPrev.next = newNode;
}
//新节点的上一个对应老节点之前的
newNode.prev = oldPrev;
//老节点的下一个对应新节点
newNode.next = oldNode;
size++; } }
2.节点的定义
package com.zzw.cn.springmvc.linkList; /**
* @author Simple
* @date 17:01 2019/9/5
* @description 定义节点
*/
public class Node {
Node prev;//上一个节点
Node next;//下一个节点
Object object;//节点值
}
3.测试类的编写。
package com.zzw.cn.springmvc.linkList; /**
* @author Simple
* @date 19:45 2019/9/5
* @description
*/
public class TestLinkeList {
public static void main(String[] args) {
AnLinkeList<String> list = new AnLinkeList<>();
list.add("1");
list.add("2");
list.add("3");
System.out.println("add方法后结果");
for (int i = 0; i < list.size; i++) {
System.out.print(list.get(i)+" ");
}
System.out.println();
list.remove(2);
System.out.println("remove方法后结果");
for (int i = 0; i < list.size; i++) {
System.out.print(list.get(i)+" ");
}
System.out.println("根据索引值添加的");
list.add(1,"3");
for (int i = 0; i < list.size; i++) {
System.out.print(list.get(i)+" ");
}
}
}
4.运行结果

五、LinkedList和ArrayList的对比
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;
LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
(一)LinkedList集合解析及手写集合的更多相关文章
- 性能学习笔记之四--事务,思考时间,检查点,集合点和手写lr接口
一.事物,思考时间,检查点,集合点 1.事务 lr里面的事物是lr运行脚本的基础.lr里面 要测试的三个维度都以事物为单位,所以一定要有事物.事务的概念贯穿loadrunner的使用,比如我们说的响应 ...
- 2 手写Java LinkedList核心源码
上一章我们手写了ArrayList的核心源码,ArrayList底层是用了一个数组来保存数据,数组保存数据的优点就是查找效率高,但是删除效率特别低,最坏的情况下需要移动所有的元素.在查找需求比较重要的 ...
- 第4.4节 Python解析与推导:列表解析、字典解析、集合解析
一. 引言 经过前几个章节的介绍,终于把与列表解析的前置内容介绍完了,本节老猿将列表解析.字典解析.集合解析进行统一的介绍. 前面章节老猿好几次说到了要介绍列表解析,但老猿认为涉及知识层面比较多 ...
- 【Machine Learning in Action --2】K-近邻算法构造手写识别系统
为了简单起见,这里构造的系统只能识别数字0到9,需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小:宽高是32像素的黑白图像.尽管采用文本格式存储图像不能有效地利用内存空间,但是为了方便理 ...
- LoadRunner手写脚本、检查点、集合点、事务、思考时间
手写脚本 什么时候要手写? 可以有条件手写脚本的场景有两类: 有接口说明文档 没有借口说明文档,要去录制,录制不了,抓包手写 所需函数 我们这里讲的例子是基于 http 协议的,也是常见的两种请求类型 ...
- map,set,list等集合解析以及HashMap,LinkedHashMap,TreeMap等该选谁的的区别
前言: 今天在整理一些资料时,想起了map,set,list等集合,于是就做些笔记,提供给大家学习参考以及自己日后回顾. Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允 ...
- 【Java】 ArrayList和LinkedList实现(简单手写)以及分析它们的区别
一.手写ArrayList public class ArrayList { private Object[] elementData; //底层数组 private int size; //数组大小 ...
- Atiit 如何手写词法解析器
Atiit 如何手写词法解析器 1.1. 通过编程直接从正则->nfa->dfa->表驱动词法解析一条龙自动生成.那是用程序自动生成是需要这样的,自己手写完全不必要这么复杂1 1.2 ...
- c#集合解析
什么是集合(collection)? 提供了一种结构化组织任意对象的方式,从.NET 的角度看,所谓的集合可以定义为一种对象,这种对象实现一个或者多个System.Collections.IColle ...
随机推荐
- Python3的日志添加功能
python日志添加功能,主要记录程序运行中的日志,统一收集并分析 一.日志的级别 debug(调试信息) info() warning(警告信息)error(错误信息) critical(致命信息) ...
- 原创:微信小程序如何使用自定义组件
本博文是通过实际开发中的一个实例来讲解自定义组件的使用. 第一步:新建自定义组件目录,如图,我新建了个componts和tabList目录,然后右键tabList目录选择新建compont取名为tab ...
- 二进制文件安装安装etcd
利用二进制文件安装安装etcd etcd组件作为一个高可用强一致性的服务发现存储仓库. etcd作为一个受到ZooKeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更专注于以下四点 ...
- Linux进程间通信——信号
一.认识信号 信号(Signals)是Unix.类Unix以及其他POSIX兼容的操作系统中进程间通讯的一种有限制的方式.它是一种异步的通知机制,用来提醒进程一个事件已经发生.当一个信号发送给一个进程 ...
- HTML5 第二章 列表和表格和媒体元素
列表: (1)什么是列表? 列表就是信息资源的一种展示形式. (2)无序列表: 语法: <ul> <li>第1项</li> <li>第2项</li ...
- 集成方法 Ensemble
一.bagging 用于基础模型复杂.容易过拟合的情况,用来减小 variance(比如决策树).基础模型之间没有太多联系(相对于boosting),训练可以并行.但用 bagging 并不能有助于把 ...
- Java 安全之:csrf攻击总结
最近在维护一些老项目,调试时发现请求屡屡被拒绝,仔细看了一下项目的源码,发现有csrf token校验,借这个机会把csrf攻击学习了一下,总结成文.本文主要总结什么是csrf攻击以及有哪些方法来防范 ...
- Consul的反熵
熵 熵是衡量某个体系中事物混乱程度的一个指标,是从热力学第二定律借鉴过来的. 熵增原理 孤立系统的熵永不自动减少,熵在可逆过程中不变,在不可逆过程中增加.熵增加原理是热力学第二定律的又一种表述,它更为 ...
- Mock Server的搭建
一.概述 我们系统与第三方开票系统有交互,场景是我们系统请求第三方开票系统,第三方开票系统根据我们的请求数据,生成开票信息然后返回发票号或异常信息,我们根据返回的信息做对应的处理.因为配合上存在一些障 ...
- Netbeans courier new 乱码问题
Netbeans 默认的字体 monospaced,显示英文的单引号及字体非常的不好看,在网上查了下资料可以变得很好看. 1.仍然保持默认字体 monospaced 2.在Netbeans 的安装目 ...