(转)利用Auto ARIMA构建高性能时间序列模型(附Python和R代码)
转自:
原文标题:Build High Performance Time Series Models using Auto ARIMA in Python and R
作者:AISHWARYA SINGH;翻译:陈之炎;校对:丁楠雅
原文链接: https://www.analyticsvidhya.com/blog/2018/08/auto-arima-time-series-modeling-python-r/
简介
想象你现在有一个任务:根据已有的历史数据,预测下一代iPhone的价格,可使用的特征包括季度销售、月度支出以及苹果资产负债表上的一系列内容。作为一名数据科学家,你会把这个问题归类为哪一类问题?当然是时间序列建模。
从预测产品销售到估算家庭用电量,时间序列预测是任何数据科学家都应该知道——哪怕不是熟练掌握——的核心技能之一。你可以使用多种不同的方法进行时间序列预测,我们将在本文中讨论Auto ARIMA,它是最为有效的方法之一。
首先,我们来了解一下ARIMA的概念,然后再进入正题——Auto ARIMA。为了巩固概念,我们将使用一个数据集,并用Python和R实现它。
目录
一、什么是时间序列?
二、时间序列预测的方法
三、ARIMA简介
四、ARIMA实现步骤
五、为什么需要Auto ARIMA?
六、用Auto ARIMA实现案例(航空乘客数据集)
七、Auto ARIMA如何选择参数?
如果你熟悉时间序列及其常用方法(如移动平均、指数平滑和ARIMA),则可以直接跳到第4节。对于初学者,请从下面这一节开始,内容包括对时间序列和各种预测方法的简要介绍。
一、什么是时间序列?
在我们学习如何处理时间序列数据之前,首先应理解什么是时间序列,以及它与其他类型的数据的区别。时间序列的正式定义如下:它是一系列在相同时间间隔内测量到的数据点。
简言之,时间序列是指以固定的时间间隔记录下的特定的值,时间间隔可以是小时、每天、每周、每10天等等。时间序列的特殊性是:该序列中的每个数据点都与先前的数据点相关。我们通过下面几个例子来更清楚地理解这一点。
- 例1:
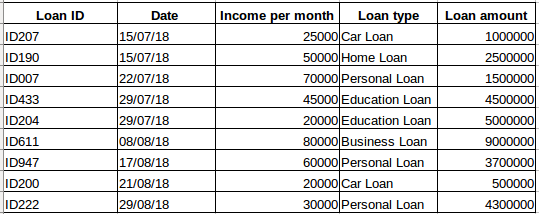
假设你从某公司获得了一个贷款人员的数据集(如下表所示)。你认为每一行都与前面的行相关吗?当然不是!一个人的贷款金额取决于他的经济状况和需要(可能还有其他因素,如家庭规模等,但为了简单起见,我们只考虑收入和贷款类型)。此外,这些数据不是在特定时间间隔内收集的,它仅与公司何时收到贷款申请相关。
- 例2:
再举一个例子。假设你有一个数据集,其中包含每天空气中的二氧化碳水平(下面是截图)。那么可以通过过去几天的数值来预测第二天的二氧化碳水平吗?当然可以。如果你观察到的数据是每天记录下来的,那么,时间间隔便是恒定的(24小时)。

现在你已经有了直觉,第一个例子是简单的回归问题,而第二个例子是时间序列问题。虽然这里的时间序列问题也可以用线性回归来解决,但这并不是最好的方法,因为它忽略了这些值与所有相对过去值之间的关系。下面,我们来了解一下解决时间序列问题的一些常用方法。
二、时间序列预测的方法
有许多种方法可以进行时间序列预测,我们将在这一节中对它们做简要地介绍。下面提到的所有方法的详细说明和Python代码可以在下文中找到:
七种时间序列预测方法(附Python代码):
https://www.analyticsvidhya.com/blog/2018/02/time-series-forecasting-methods/
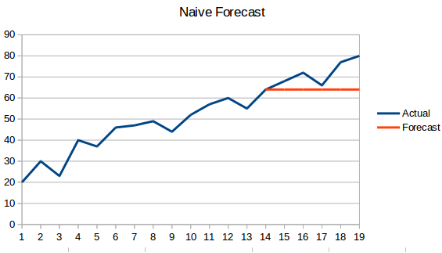
1. 朴素预测法:在这种预测方法中,新数据点预测值等于前一个数据点的值。结果将会是一条平行线,因为所有预测的新值采用的都是先前的值。
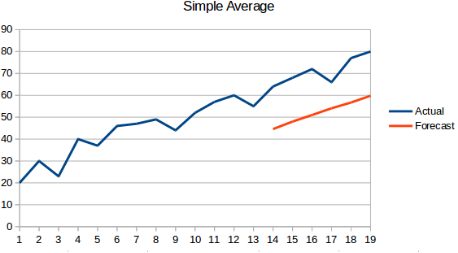
2. 简单平均值法:视下一个值为所有先前值的平均数。这一预测法要优于“朴素预测法”,因为它的结果不会是一条平行线。但是在简单平均值法中,过去的所有值都被考虑进去了,而这些值可能并不都是有用的。例如,当要求预测今天的温度时,你仅需要考虑前七天的温度,而不是一个月前的温度。
3. 移动平均法:这是对前两个方法的改进。不取前面所有点的平均值,而是将n个先前的点的平均值作为预测值。
4. 加权移动平均法:加权移动平均是带权重的移动平均,先前的n个值被赋予不同的权重。

5. 简单指数平滑法:在这种方法中,更大的权重被分配给更近期的观测结果,来自遥远过去的观测值则被赋予较小的权重。
6. 霍尔特(Holt)线性趋势模型:该方法考虑了数据集的趋势。所谓趋势,指的是数据的递增或递减的性质。假设旅馆的预订数量每年都在增加,那么我们可以说预订数量呈现出增加的趋势。该方法的预测函数是值和趋势的函数。
7. 霍尔特-温特斯(Holt Winters)方法:该算法同时考虑了数据的趋势和季节性。例如,一家酒店的预订数量在周末很高,而在工作日则很低,并且每年都在增加;因此存在每周的季节性和增长的趋势。
8. ARIMA:ARIMA是一种非常流行的时间序列建模方法。它描述了数据点之间的相关性,并考虑了数值之间的差异。ARIMA的改进版是SARIMA (或季节性ARIMA)。我们将在下一节中更详细地讨论ARIMA。
三、ARIMA简介
在本节中,我们将简要介绍ARIMA,这将有助于理解Auto Arima。“时间序列完整教程”一文中对ARIMA, (p,q,d) 参数,ACF、 PACF图和具体实现有详细的解释。
ARIMA是一种非常流行的时间序列预测方法,它是自回归综合移动平均(Auto-Regressive Integrated Moving Averages)的首字母缩写。ARIMA模型建立在以下假设的基础上:
- 数据序列是平稳的,这意味着均值和方差不应随时间而变化。通过对数变换或差分可以使序列平稳。
- 输入的数据必须是单变量序列,因为ARIMA利用过去的数值预测未来的数值。
ARIMA有三个分量:AR(自回归项)、I(差分项)和MA(移动平均项)。让我们对每个分量做一下解释:
- AR项是指用于预测下一个值的过去值。AR项由ARIMA中的参数‘p’定义。“p”的值是由PACF图确定的。
- MA项定义了预测未来值时过去预测误差的数目。ARIMA中的参数‘q’代表MA项。ACF图用于识别正确的‘q’值,
- 差分顺序规定了对序列执行差分操作的次数,对数据进行差分操作的目的是使之保持平稳。像ADF和KPSS这样的测试可以用来确定序列是否是平稳的,并有助于识别d值。
四、ARIMA实现步骤
实现ARIMA模型的通用步骤如下:
1. 加载数据:构建模型的第一步当然是加载数据集。
2. 预处理:根据数据集定义预处理步骤。包括创建时间戳、日期/时间列转换为d类型、序列单变量化等。
3. 序列平稳化:为了满足假设,应确保序列平稳。这包括检查序列的平稳性和执行所需的转换。
4. 确定d值:为了使序列平稳,执行差分操作的次数将确定为d值。
5. 创建ACF和PACF图:这是ARIMA实现中最重要的一步。用ACF PACF图来确定ARIMA模型的输入参数。
6. 确定p值和q值:从上一步的ACF和PACF图中读取p和q的值。
7. 拟合ARIMA模型:利用我们从前面步骤中计算出来的数据和参数值,拟合ARIMA模型。
8. 在验证集上进行预测:预测未来的值。
9. 计算RMSE:通过检查RMSE值来检查模型的性能,用验证集上的预测值和实际值检查RMSE值。
五、为什么我们需要Auto ARIMA?
虽然ARIMA是一个非常强大的预测时间序列数据的模型,但是数据准备和参数调整过程是非常耗时的。在实现ARIMA之前,需要使数据保持平稳,并使用前面讨论的ACF和PACF图确定p和q的值。Auto ARIMA让整个任务实现起来非常简单,因为它去除了我们在上一节中提到的步骤3至6。下面是实现AUTO ARIMA应该遵循的步骤:
1. 加载数据:此步骤与ARIMA实现步骤1相同。将数据加载到笔记本中。
2. 预处理数据:输入应该是单变量,因此删除其他列。
3. 拟合Auto ARIMA:在单变量序列上拟合模型。
4. 在验证集上进行预测:对验证集进行预测。
5. 计算RMSE:用验证集上的预测值和实际值检查RMSE值。
正如你所看到的,我们完全绕过了选择p和q的步骤。啊!可以松口气了!在下一节中,我们将使用一个假想数据集实现Auto ARIMA。
六、Python和R的实现
我们将使用国际航空旅客数据集,此数据集包含每月乘客总数(以千为单位),它有两栏-月份和乘客数。你可以从以下链接获取数据集:
https://datamarket.com/data/set/22u3/international-airline-passengers-monthly-totals-in-thousands-jan-49-dec-60#!ds=22u3&display=line



以下是同一问题的R代码:

七、Auto ARIMA如何选择最佳参数
在上述代码中,我们仅需用.efit()命令来拟合模型,而不必选择p、q、d的组合,但是模型是如何确定这些参数的最佳组合的呢?Auto ARIMA生成AIC和BIC值(正如你在代码中看到的那样),以确定参数的最佳组合。AIC(赤池信息准则)和BIC(贝叶斯信息准则)值是用于比较模型的评估器。这些值越低,模型就越好。
如果你对AIC和BIC背后的数学感兴趣,请访问以下链接:
- AIC: http://www.statisticshowto.com/akaikes-information-criterion/
- BIC: http://www.statisticshowto.com/bayesian-information-criterion/
八、尾注和进一步阅读
我发现Auto ARIMA是进行时间序列预测的最简单的方法。知道一条捷径是件好事,但熟悉它背后的数学也同样重要的。在这篇文章中,我略过了ARIMA如何工作的细节,但请务必阅读本文中提供的链接的文章。为了方便你参考,这里再次提供一遍链接:
- 时间序列预测初学者综合指南(Python) https://www.analyticsvidhya.com/blog/2016/02/time-series-forecasting-codes-python/
- 时间序列完整教程(R) https://www.analyticsvidhya.com/blog/2015/12/complete-tutorial-time-series-modeling/
- 时间序列预测的七种方法 (附python代码) https://www.analyticsvidhya.com/blog/2018/02/time-series-forecasting-methods/
(转)利用Auto ARIMA构建高性能时间序列模型(附Python和R代码)的更多相关文章
- 利用 Rational ClearCase ClearMake 构建高性能的企业级构建环境
转载地址:http://www.ibm.com/developerworks/cn/rational/r-cn-clearmakebuild/ 构建管理是 IBM® Rational® ClearCa ...
- 时间序列算法(平稳时间序列模型,AR(p),MA(q),ARMA(p,q)模型和非平稳时间序列模型,ARIMA(p,d,q)模型)的模型以及需要的概念基础学习笔记梳理
在做很多与时间序列有关的预测时,比如股票预测,餐厅菜品销量预测时常常会用到时间序列算法,之前在学习这方面的知识时发现这方面的知识讲解不多,所以自己对时间序列算法中的常用概念和模型进行梳理总结(但是为了 ...
- 为物联网而生:高性能时间序列数据库HiTSDB商业化首发!
为什么80%的码农都做不了架构师?>>> 摘要: 近日,阿里云宣布高性能时间序列数据库 (High-Performance Time Series Database , 简称 H ...
- 【读书笔记】2016.12.10 《构建高性能Web站点》
本文地址 分享提纲: 1. 概述 2. 知识点 3. 待整理点 4. 参考文档 1. 概述 1.1)[该书信息] <构建高性能Web站点>: -- 百度百科 -- 本书目录: 第1章 绪论 ...
- 构建高性能web站点--读书大纲
用户输入你的站点网址,等了半天..还没打开,裤衩一下就给关了.好了,流失了一个用户.为什么会有这样的问题呢.怎么解决自己站点“慢”,体验差的问题呢. 在这段等待的时间里,到底发生了什么?事实上这并不简 ...
- 构建高性能WEB站点笔记三
构建高性能WEB站点笔记三 第10章 分布式缓存 10.1数据库的前端缓存区 文件系统内核缓冲区,位于物理内存的内核地址空间,除了使用O_DIRECT标记打开的文件以外,所有对磁盘文件的读写操作都要经 ...
- 构建高性能WEB站点笔记二
构建高性能WEB站点笔记 因为是跳着看的,后面看到有提到啥epoll模型,那就补充下前面的知识. 第三章 服务器并发处理能力 3.2 CPU并发计算 进程 好处:cpu 时间的轮流使用.对CPU计算和 ...
- 构建高性能web站点-1
以下为阅读<构建高性能web站点>郭欣 著 这本书的适合读者: 1.编写web程序.关心站点性能,并且希望自己做的更加出色的开发人员 2.关心性能和可用性的web架构师 3.希望构建高性能 ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...
随机推荐
- Codeforces Round #451 (Div. 2) A B C D E
Codeforces Round #451 (Div. 2) A Rounding 题目链接: http://codeforces.com/contest/898/problem/A 思路: 小于等于 ...
- springmvc运行流程简单解释(源码解析,文末附自己画的流程图)
首先看一下DispatcherServlet结构: 观察HandlerExecutionChain对象的创建与赋值,这个方法用来表示执行这个方法的整条链. 进入getHandler方法: 此时的变量h ...
- 2019-2020-1 20199304《Linux内核原理与分析》第三周作业
1.操作系统是如何工作的? 计算机三个法宝(3个关键性的方法机制): 存储程序计算机.函数调用堆栈.中断机制. 1.1堆栈: 在计算机领域,堆栈是一个不容忽视的概念,堆栈是一种数据结构.堆栈都是一种数 ...
- 【nodejs原理&源码赏析(2)】KOA中间件的基本运作原理
[摘要] KOA中间件的基本运作原理 示例代码托管在:http://www.github.com/dashnowords/blogs 在中间件系统的实现上,KOA中间件通过async/await来在不 ...
- 自学PHP的第22天---ThinkPHP中的路由、ThinkPHP目录结构
这一切的一切都得从“Hello world”说起!!! 有很多东西在thinkPHP的官方开发文档上其实都有讲到,我在这里只是想记录自己每天坚持学习PHP的情况,今天接触ThinkPHP的路由,路由这 ...
- HDU-6113
度度熊是一个喜欢计算机的孩子,在计算机的世界中,所有事物实际上都只由0和1组成. 现在给你一个n*m的图像,你需要分辨他究竟是0,还是1,或者两者均不是. 图像0的定义:存在1字符且1字符只能是由一个 ...
- Chapter 3 :代码的坏味道
"如果尿布臭了,就换掉它." --Beck奶奶,论保持小孩清洁的哲学 代码的坏味道这一章集中论述该何时重构.具体的重构方法在后面的章节. "没有任何度量规矩比得上见识广博 ...
- UWP 中的全局异常处理
问题 在开发一款应用的过程中,我们开发者很难考虑到所有问题,往往会忘记处理一些可能发生的异常.随之而来的结果就是用户使用过程中接连不断的崩溃.所以,我们有必要处理所有未被我们处理的异常. 本文介绍了 ...
- python + selenium WebDriver的环境配置
想试用python语言来学习selenium WebDriver,首先需要搭建一个测试环境,从python安装到浏览器插件配置的详细步骤,总结如下: 一.python环境配置 1.从官网下载最新的一个 ...
- 了解web漏洞-sql注入
1:为什么要学web漏洞? 作为一个运维人员,日常工作就是保障服务器和网站的业务正常运行,平时也需要对服务器的安全工作加固,说到防护攻击问题,那么久必须去了解攻击者是怎么对服务器发动的一个流程,这样才 ...