cs231n线性分类器作业 svm代码 softmax
CS231n之线性分类器
斯坦福CS231n项目实战(二):线性支持向量机SVM
CS231n 2016 通关 第三章-SVM与Softmax
cs231n:assignment1——Q3: Implement a Softmax classifier
cs231n线性分类器作业:(Assignment 1 ):
二 训练一个SVM:
steps:
- 完成一个完全向量化的SVM损失函数
- 完成一个用解析法向量化求解梯度的函数
- 再用数值法计算梯度,验证解析法求得结果
- 使用验证集调优学习率与正则化强度
- 用SGD(随机梯度下降)方法进行最优化
- 将最终学习到的权重可视化
1.SVM
支持向量机(Support Vector Machine, SVM)的目标是希望正确类别样本的分数( )比错误类别的分数越大越好。两者之间的最小距离(margin)我们用
来表示,一般令
=1。
对于单个样本,SVM的Loss function可表示为:
将 ,
带入上式:
其中, 表示正确类别,
表示正确类别的分数score,
表示错误类别的分数score。从
表达式来看,
不仅要比
小,而且距离至少是
,才能保证
。若
,则
。也就是说SVM希望
与
至少相差一个Δ的距离。
该Loss function我们称之为Hinge Loss
此处使用多分类的hinge loss, Δ=1:
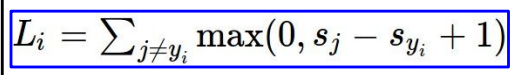
假如一个三分类的输出分数为:[10, 20, -10],正确的类别是第0类 (yi=0),则该样本的Loss function为:
值得一提的是,还可以对hinge loss进行平方处理,也称为L2-SVM。其Loss function为:
这种平方处理的目的是增大对正类别与负类别之间距离的惩罚。
依照scores带入hinge loss:

依次计算,得到最终值,并求和再平均:
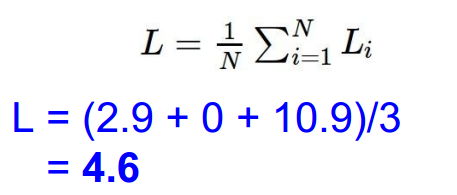
svm 的loss function中bug:
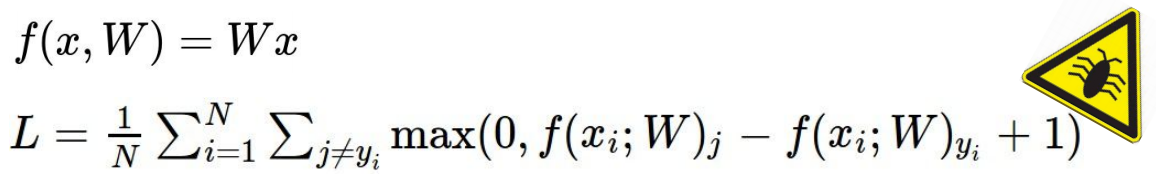
简要说明:当loss 为0,则对w进行缩放,结果依旧是0,如何解决?如下图所示:

加入正则项:

加入正则,对w进行约束,常用的正则有L1 L2
L1趋于选取稀疏的参数,L2趋于选取数值较小且离散的参数。
问题1:如果在求loss时,允许j=y_i
此时L会比之前未包含的L大1
问题2:如果对1个样本做loss时使用对loss做平均,而不是求和,会怎样?
相当于sum乘以常系数
问题4:上述求得的hinge loss的最大值与最小值:
最小值为0,最大值可以无限大。
问题5:通常在初始化f(x,w)中的参数w时,w值范围较小,此时得到的scores接近于0,那么这时候的loss是?
此时正确score与错误score的差接近于0,对于3classes,loss的结果是2。
2.softmax
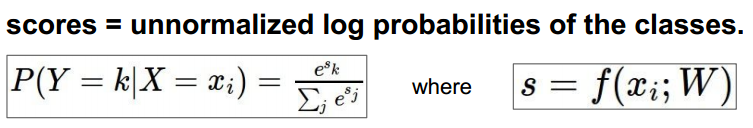
使用似然估计作为loss,本来是似然估计越大越好,但通常loss使用越小时更直观,所以乘以-1:
单一样本:
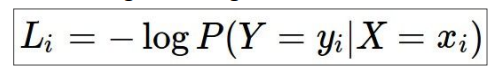
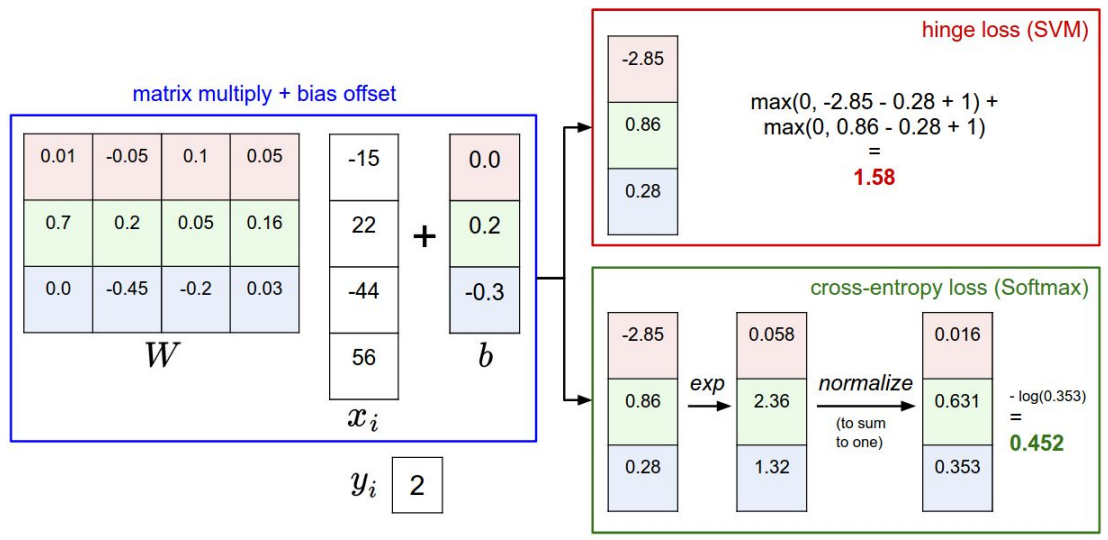
单一样本数值表示:
具体例子:

3、SVM与Softmax比较:
模型不同,loss function不同》》
loss function:
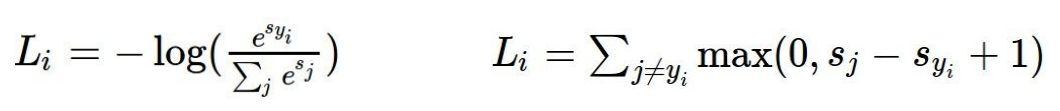
问题8:如果改变对输入数据做改变,即f(x,w)后的值发生变化,此时两个模型的loss分别会怎样变化?(如下例所示)

当改变的值不大时,对svm结果可能没影响,此时改变的点没有超过边界;但当改变较大时,会使得loss变化,此时表示数据点已经跨越了最大边界范围。
但是对softmax而言,无论大小的改变,结果都会相应变化。
4、参数计算
对两种模型loss 求和取平均并加入正则项。

方案1:随机选择w,计算得到相应的loss,选取产生的loss较小的w。
方案2:数值计算法梯度下降
一维求导:
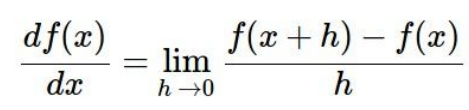
多维时,分别对分量求导。具体步骤如下所示: h为定值


上述计算了2个分量的偏导。按照此方法求其余分量偏导。代码结构如下图:

显然,这种方式计算比较繁琐,参数更新比较慢。
方案三:解析法梯度下降
方案二使用逐一对w进行微量变化,并求导数的方式步骤繁琐,并且产生了很多不必要的步骤。
方案三是直接对w分量求偏导的方式:
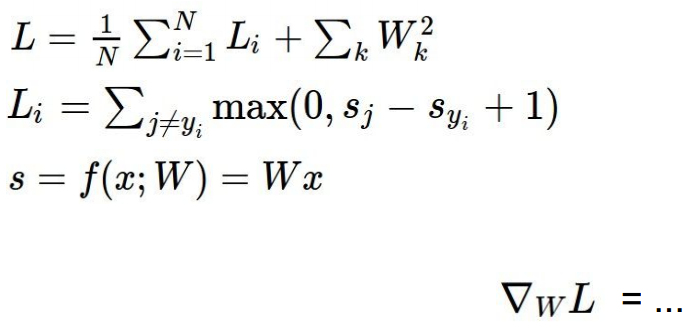

对于SVM:
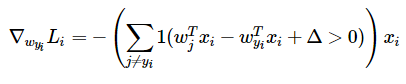
对于softmax:
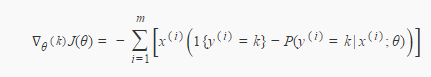
softmax梯度推导
(1)概率

(2)似然函数

(3)对似然函数关于θq求导
似然函数展开:
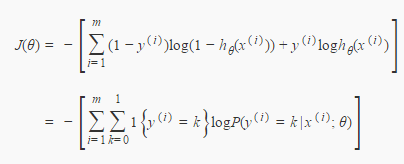
求导:
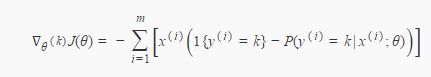
SVM代码 返回loss和dw 给出两种写法 :
(1)循环的写法:
def loss_naive(self, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs:
- X: A numpy array of shape (num_train, D) contain the training data
consisting of num_train samples each of dimension D
- y: A numpy array of shape (num_train,) contain the training labels,
where y[i] is the label of X[i]
- reg: float, regularization strength
Return:
- loss: the loss value between predict value and ground truth
- dW: gradient of W
""" # Initialize loss and dW
loss = 0.0
dW = np.zeros(self.W.shape) # Compute the loss and dW
num_train = X.shape[0]
num_classes = self.W.shape[1]
for i in range(num_train):
scores = np.dot(X[i], self.W)
for j in range(num_classes):
if j == y[i]:
margin = 0
else:
margin = scores[j] - scores[y[i]] + 1 # delta = 1
if margin > 0:
loss += margin
dW[:,j] += X[i].T
dW[:,y[i]] += -X[i].T
# Divided by num_train
loss /= num_train
dW /= num_train # Add regularization
loss += 0.5 * reg * np.sum(self.W * self.W)
dW += reg * self.W return loss, dW
(2)矩阵操作;
def loss_vectorized(self, X, y, reg):
"""
Structured SVM loss function, naive implementation (with loops).
Inputs:
- X: A numpy array of shape (num_train, D) contain the training data
consisting of num_train samples each of dimension D
- y: A numpy array of shape (num_train,) contain the training labels,
where y[i] is the label of X[i]
- reg: (float) regularization strength
Outputs:
- loss: the loss value between predict value and ground truth
- dW: gradient of W
""" # Initialize loss and dW
loss = 0.0
dW = np.zeros(self.W.shape) # Compute the loss
num_train = X.shape[0]
scores = np.dot(X, self.W)
correct_score = scores[range(num_train), list(y)].reshape(-1, 1) # delta = -1
margin = np.maximum(0, scores - correct_score + 1)
margin[range(num_train), list(y)] = 0
loss = np.sum(margin) / num_train + 0.5 * reg * np.sum(self.W * self.W) # Compute the dW
num_classes = self.W.shape[1]
mask = np.zeros((num_train, num_classes))
mask[margin > 0] = 1
mask[range(num_train), list(y)] = 0
mask[range(num_train), list(y)] = -np.sum(mask, axis=1)
dW = np.dot(X.T, mask)
dW = dW / num_train + reg * self.W return loss, dW
dw是Li中j不等于yi时hingeloss大于0的个数的和乘对应的xi的负数,就是下面的式子
每一列是一个样本经过参数矩阵计算得到的对不同类别的score,Li计算每个样本得分与真实标签的hinge loss
每个score都是由下面的矩阵计算得到,xi是一个样本,w和b是参数矩阵,f(xi;W,b)是样本对每一类的score:

cs231n线性分类器作业 svm代码 softmax的更多相关文章
- 深度学习与计算机视觉系列(3)_线性SVM与SoftMax分类器
作者: 寒小阳 &&龙心尘 时间:2015年11月. 出处: http://blog.csdn.net/han_xiaoyang/article/details/49949535 ht ...
- cs231n笔记:线性分类器
cs231n线性分类器学习笔记,非完全翻译,根据自己的学习情况总结出的内容: 线性分类 本节介绍线性分类器,该方法可以自然延伸到神经网络和卷积神经网络中,这类方法主要有两部分组成,一个是评分函数(sc ...
- 【Python 代码】CS231n中Softmax线性分类器、非线性分类器对比举例(含python绘图显示结果)
1 #CS231n中线性.非线性分类器举例(Softmax) #注意其中反向传播的计算 # -*- coding: utf-8 -*- import numpy as np import matplo ...
- cs231n --- 1:线性svm与softmax
cs231n:线性svm与softmax 参数信息: 权重 W:(D,C) 训练集 X:(N,D),标签 y:(N,1) 偏置量bias b:(C,1) N:训练样本数: D:样本Xi 的特征维度, ...
- 线性SVM与Softmax分类器
1 引入 上一篇介绍了图像分类问题.图像分类的任务,就是从已有的固定分类标签集合中选择一个并分配给一张图像.我们还介绍了k-Nearest Neighbor (k-NN)分类器,该分类器的基本思想是通 ...
- cs231n笔记 (一) 线性分类器
Liner classifier 线性分类器用作图像分类主要有两部分组成:一个是假设函数, 它是原始图像数据到类别的映射.另一个是损失函数,该方法可转化为一个最优化问题,在最优化过程中,将通过更新假设 ...
- [基础]斯坦福cs231n课程视频笔记(一) 图片分类之使用线性分类器
线性分类器的基本模型: f = Wx Loss Function and Optimization 1. LossFunction 衡量在当前的模型(参数矩阵W)的效果好坏 Multiclass SV ...
- 『cs231n』线性分类器损失函数
代码部分 SVM损失函数 & SoftMax损失函数: 注意一下softmax损失的用法: SVM损失函数: import numpy as np def L_i(x, y, W): ''' ...
- CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3 2===本节课的收获 ===熟悉SVM及其多分类问题 ===熟悉softmax分类问题 ===了解优化思想 由上节课即KNN的分析步骤 ...
随机推荐
- Node.js小白开路(一)-- Buffer篇
Buffer是nodeJS中的二进制缓存操作模块内容.先来看一段简短的代码. // 创建一个长度为 10.且用 0 填充的 Buffer. const buf1 = Buffer.alloc(10); ...
- ZOJ 3203 Light Bulb(数学对勾函数)
Light Bulb Time Limit: 1 Second Memory Limit: 32768 KB Compared to wildleopard's wealthiness, h ...
- L133
The U.S. Food and Drug Administration is considering a ban on flavorede-cigarettes in response to an ...
- 《Drools7.0.0.Final规则引擎教程》第4章 4.2 no-loop
no-loop 定义当前的规则是否不允许多次循环执行,默认是 false,也就是当前的规则只要满足条件,可以无限次执行.什么情况下会出现规则被多次重复执行呢?下面看一个实例: package com. ...
- Git常用命令以及用法
一 如何让单个文件回退到指定的版本 1. 进入到文件所在文件目录,或者能找到文件的路径 查看整个目录的修改记录 git log . 2. 回退到指定的版本 git reset f7a22076 ...
- jmeter 查看提取的参数
需求:查看“传入的参数”或者“正则表达提取的参数”等...... 解决:添加Debug Sampler组件,不需要配置,直接使用默认 1.使用CSV Data Set Config组件“传入的参数”直 ...
- 在zxing开源项目里,camera.setDisplayOrientation(90)出现错误
[错误提示] setDisplayOrientation(int)未定义 [错误原因] sdk版本过低,这个方法在Android2.2之后才有 [解决方法] 直接在project.propert ...
- PS更换证件照颜色
PS是我们经常使用的设计软件,在生活中使用的范围也很广,但是对于普通的用户来说,也就是平时给自己的照片美化一下,还有就是做一些证件照.今天和大家分享的是更改证件照的颜色,网上可能有很多,但是个人感觉都 ...
- Info.plist字段列表详解
常用字段: 1.获取版本信息: NSDictionary*infoDic = [[NSBundle mainBundle] infoDictionary]; NSString *localVersio ...
- 关于app集成支付宝应用内支付的问题总结
pem文件生成,将合作伙伴密钥复制到notepad++中,每45个字符回车,去除空格,头尾加上标题,文件需保存为无BOM的UTF8格式,就OK. 可以每行64个字符,共216个字符. 近来处理了 ...