python爬虫之认识爬虫和爬虫原理
python爬虫之基础学习(一)
网络爬虫
网络爬虫也叫网络蜘蛛、网络机器人。如今属于数据的时代,信息采集变得尤为重要,可以想象单单依靠人力去采集,是一件无比艰辛和困难的事情。网络爬虫的产生就是代替人力在互联网中自动进行信息采集和整理。
网络爬虫的组成
网络爬虫由控制节点、爬虫节点以及资源库构成,简单而言就是控制节点控制爬虫节点爬取和处理网页存储到资源库中。网络爬虫中有多个控制节点和爬虫节点,一个控制节点控制着多个爬虫节点,同一个控制节点下的多个爬虫节点可以相互通信,多个控制节点也可以相互通信。
网络爬虫的类型
通用网络爬虫:也称为全网爬虫,爬取目标是整个互联网,主要应用于大型搜索引擎。主要应用的爬行策略:深度优先爬行策略和广度优先爬行策略。
聚焦网络爬虫:爬取选择的特定网页。主要应用的爬行策略:基于内容评价的爬行策略、基于链接评价的爬行策略、基于增强学习的爬行策略和基于语境图的爬行策略。
增量式网络爬虫:只爬取内容更新的网页或者新产生的网页。
深层网络爬虫:爬取互联网中的深层页面。网页分为表层页面和深层页面,表层页面是指通过静态链接可以直接获取的页面,而深层页面则是需要通过验证表单获取的页面。因此,深层网络爬虫需要表单填写,而对于表单的填写又分为两种类型:基于领域知识的表单填写和基于网页结构分析的表单填写。基于领域知识的表单填写:建立一个关键词库,填写表单时,根据语义选择关键词填写;基于网页结构分析的表单填写:当领域知识有限,根据网页结构进行分析,自动填写。
平时我们日常说的爬虫多是指聚焦网络爬虫,聚焦网络爬虫的基本流程为:
- 通过网络域名获取HTML数据
- 解析数据获取目标信息
- 存储目标信息
- 移动至另一个网页重复上述过程
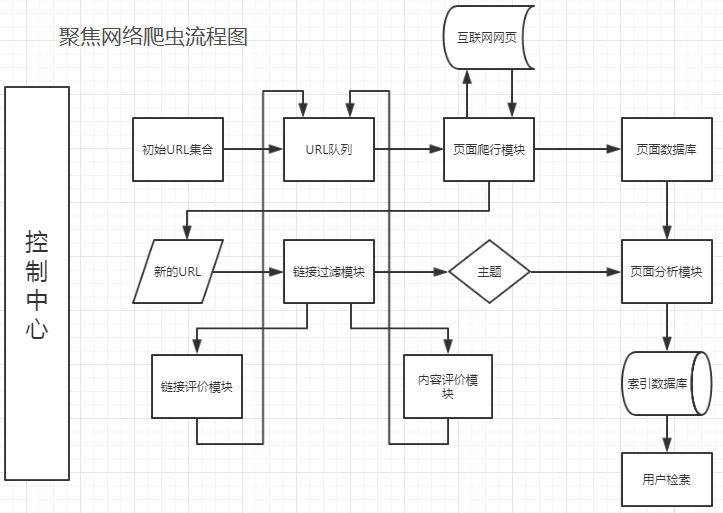
聚焦网络爬虫控制中心负责整个爬虫系统的管理和监控。初始URL集合传递到URL队列,页面爬行模块从URL队列取出一批URL列表,后爬取互联网中的页面并传送到页面数据库中存储。与此同时,爬取页面获取的新的URL会使用链接过滤模块结合选定的主题滤除无用链接,剩余URL通过链接评价模块和内容评价模块进行优先级排序后推入URL队列。另一方面,存储在页面数据块的页面需要经过页面分析模块对页面信息进行处理,根据处理结果建立索引数据库,方便用户检索。
搜索引擎核心
爬虫与搜索引擎是密不可分的,搜索引擎核心工作流程:
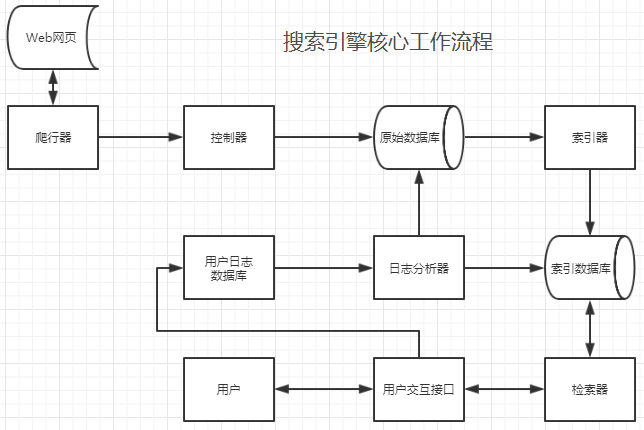
搜索引擎利用爬虫模块(爬行器和控制器)爬取网页,后把爬取的网页存储在原始数据库中。索引器对原始数据库中数据建立索引,并存储到索引数据库。用户通过用户交互接口检索信息时,一方面通过检索器和索引数据库搜索信息;另一方面,产生的用户日志通过用户日志数据库和日志分析器进行存储和处理,处理结果反馈给原始数据库和索引数据库,根据用户检索要求对数据库中信息进行调整排名等操作。
网络爬虫实现原理
网络爬虫实现过程
通用网络爬虫
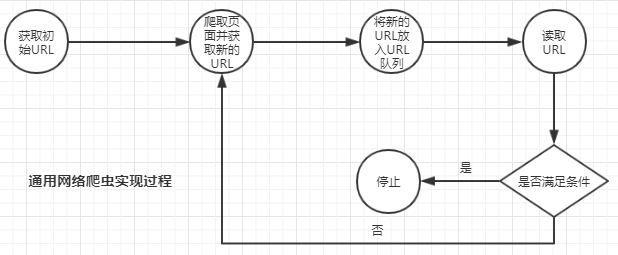
- 获取初始URL。初始URL可以是用户人为指定,也可以是用户指定初始爬取页面决定。
- 根据初始URL爬取页面获得新URL。按照初始URL爬取页面以后,将网页存储原始数据库中,已使用的URL存放在一个URL列表,同时也会新发现URL地址。
- 将新发现的URL放到URL队列中。
- 从URL队列中读取新URL,按照新的URL继续爬取网页,同时继续从页面中发现新的URL,并重复上述2、3步。
- 满足爬虫系统设置的停止条件是,停止爬取。一般爬虫系统会设置停止条件,如果没有设置,爬虫会一直爬取下去。
聚焦网络爬虫
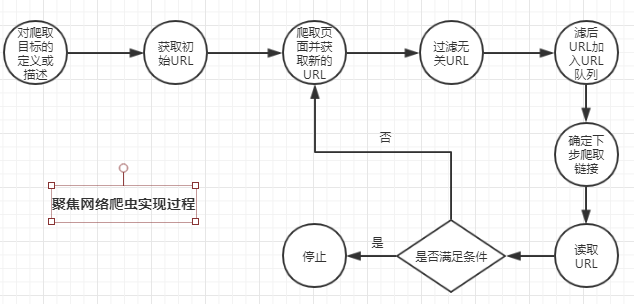
- 对爬取目标的定义和描述。在聚焦网络爬虫中,首先要依据爬虫需求定义好爬取目标,以及相关描述。
- 获取初始的URL。
- 根据初始的URL爬取页面,并获得新的URL。
- 从新的URL中过滤掉与爬取目标无关的链接。聚焦网路爬虫是具有目的性的,与目标无关的网页需要被过滤掉,同时对已爬取的URL需要存放在一个URL列表中,用于去重和判断爬取进程。
- 将过滤后的链接加入到URL队列。
- 从URL队列中,根据搜索算法,确定URL的优先级以及下一步要爬取的URL。在通用网络爬虫中,下一步爬取哪些URL以及爬取顺序是不太重要的,而在聚焦网络爬虫中,下一步爬取的URL和爬取顺序会影响爬取效率。因此,需要根据搜索策略来确定。
- 从下一步要爬取的URL中读取URL,根据新的URL爬取网页,并重复上述爬取过程。
- 满足系统设置的停止条件或者无法获取新的与爬取目标有限的URL时,停止爬取。
爬行策略
前面说过,确定URL队列中爬取优先顺序在聚焦网络爬虫中尤为重要,而爬取URL优先级需要根据爬行策略来确定。主要的爬行策略有:深度优先策略、广度优先策略、大站优先策略、反链爬行策略等。
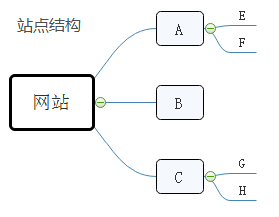
深度优先策略:深度表现为纵向,深度优先策略会按照爬取的网页依次爬取该网页下层的所有链接在返回上层继续爬取。顺序为:A-E-F-B-C-G-H。
广度优先策略:广度表现为横向,广度优先策略会按照爬取的网页依次爬取同一层级的所有网页再爬取下一层级。顺序为:A-B-C-E-F-G-H。
大站优先策略:大站是指网页所在站点分类,单个站点所包含网页数量多少依次排序,按照网页数量多的站点开始爬取。
反向链策略:反向链是指该网页被其他页面指向链接,爬行策略为优先爬取反向链接数多的网页,即按网页被其他网页链接指向次数排序。
其他爬行策略还有OPIC策略、PageRank策略...
网页更新策略
我们知道网站的网页是经常更新,产品上新或者新闻更新等等。那作为爬虫什么时间重新爬取网页呢?考虑两个问题:一是网页更新过慢情况,爬虫爬取时间间隔短,势必产生多次爬取无效内容,对爬虫和服务器而言都会增加不必要的压力;二是网页更新过快,而爬虫爬取时间间隔过长,那么必然会存在数据获取不完整的情况。显然,只有爬取时间间隔和网页更新时间间隔一致的情况下,效果会更好。因此,当爬虫服务器资源有限时,制定合理网页更新策略,更有助于我们对网页获取以及网站服务器的减负。常见的网页更新策略有:用户体验策略、历史数据策略以及聚类分析策略等。
用户体验策略:用户体验表现在什么时候呢?打开百度,搜索关键词出现一系列搜索结果,当我们作为用户时,一般优先关注前几条或者前几页的网页。而用户体验策略则是优先更新搜索结果排名靠前的网页,并依据爬虫爬取网页多个历史版本的内容更新、搜索质量影响、用户体验等信息,确定爬虫的爬取周期。
历史数据策略:爬虫爬取某个网页的多个历史版本,可以得出网页的历史更新数据,历史数据策略是根据历史数据借助数学手段建模分析,预测网页下一次更新时间,进而确定爬虫爬取周期。
聚类分析策略:用户体验策略和历史数据策略都需要网页历史数据进行分析,对于新网页而言是不友好的。聚类分析策略是采取对具有相同或者相似属性的网页划归分类,这种分类称之为聚类。对一个聚类而言,因为存在相同或者相似的属性,我们认定网页更新时间也比较相近,对一个聚类抽样分析更新间隔,再对多个样本结果求均值减小误差,以此确定爬虫爬取周期。
网页分析算法
前面说过,搜索引擎搜索结果会按照先后排名出现,那么怎么实现搜索结果的网页排序呢?网页分析算法就是实现爬取网页排序问题的方法,常见的网页分析算法有:基于用户行为的网页分析算法、基于网络拓扑的网页分析算法、基于网页内容的网页分析算法。
基于用户行为的网页分析算法:简单来说就是通过用户对网页的访问行为,对网页进行评价排序。访问行为有:访问频率、访问时长等。
基于网络拓扑的网页分析算法:依据网页之间的链接关系、结构关系以及网页数据等对网页进行分析、评价、排序。基于网页拓扑的网页分析算法按照粒度有可细分为:基于网页粒度的分析算法、基于网页块粒度的分析算法、基于网站粒度分析算法。
- 基于网页粒度的分析算法:网页之间一般存在多个链接关系,一个网页链接关系越多说明网页的重要程度越高,表现为其权值越高。权值高的,排名越前。例如,Google搜索引擎使用PageRank算法。影响因素:网页链接数量
- 基于网页块粒度的分析算法:上面说过网页存在多个链接关系,一个网页的链接按照与主题相关程度又可以划分多个层次,其重要程度也会不同。那么网页含有与主题相关程度高的链接越多,排名越前。影响因素:网页与主题相关的链接数量
- 基于网站粒度的分析算法:同基于网页粒度的分析算法相似,对网站的层次和等级划分,网站层次和等级越高,相应的排名越前。
基于网页内容的分析算法:依据网页中的数据和文本信息对网页进行评价排序。
身份识别
爬虫爬取网页时,一般是需要先访问网页的。对于爬虫而言,爬取网页时,服务器是可以识别出不是用户行为的,进而采取拒绝访问或者封IP等行为。那么如何让爬虫伪装成用户呢?爬虫爬取访问网页的时候,可以在HTTP请求中添加User-Agent信息来告诉服务器身份信息。
一般爬虫访问一个网站的时候,需要先检查一下站点下的Robots.txt文件来确定可以爬取的网页范围,对于一些禁止的URL,按照Robot协议是不应爬取访问的。
一般Robots.txt查看方式:根URL/Robots.txt。
具体添加User-Agent信息方法,查看:python爬虫之User-Agent用户信息
python爬虫之认识爬虫和爬虫原理的更多相关文章
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 【Python爬虫】01:网络爬虫--规则
Python网络爬虫与信息提取 目标:掌握定向网络数据爬取和网页解析的基本能力. the website is the API 课程分为以下部分: 1.requsets库(自动爬取HTML页面.自动网 ...
- python 全栈开发,Day134(爬虫系列之第1章-requests模块)
一.爬虫系列之第1章-requests模块 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的 ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬取mc皮肤【爬虫项目】
首先,找到一个皮肤网站,其中一个著名的皮肤网站就是 https://littleskin.cn .进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤.给各位分享一下代码. PS:另外很多人在学习 ...
- python爬虫:一些常用的爬虫技巧
python爬虫:一些常用的爬虫技巧 1.基本抓取网页 get方法: post方法: 2.使用代理IP 在开发爬虫过程中经常会遇到IP被封掉的情况,这时就需要用到代理IP; 在urllib2包中有Pr ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- 【python】一个简单的贪婪爬虫
这个爬虫的作用是,对于一个给定的url,查找页面里面所有的url连接并依次贪婪爬取 主要需要注意的地方: 1.lxml.html.iterlinks() 可以实现对页面所有url的查找 2.获取页面 ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
随机推荐
- C# DateTime.ToString()的各种日期格式
DateTime.ToString()的各种日期格式 例: ToString:2016/9/27 0:00:00 ToString("yyyy/MM/dd"):2016/09/27 ...
- 一些webGL地球的网址
测试浏览器的webgl支持情况:https://browserleaks.com/webgl 或者 https://github.com/AnalyticalGraphicsInc/webglrepo ...
- C# winform中窗口的关闭按钮的隐藏与禁用的几种方式说明
首先说一句:不存任何一种方式可以单独隐藏关闭按钮,隐藏的话会把所有最大化,最小化,帮助,关闭按钮都给隐藏掉. 第一 种: 禁用窗口上部的关闭按钮 方法一:在Form1的窗口程序中desigener ...
- HYSBZ 1036 树的统计Count (水题树链剖分)
题意:中文题. 析:就是直接维护一个最大值和一个和,用线段树维护即可,这个题很简单,但是我卡了一晚上,就是在定位的时候,位置直接反过来了,但是样例全过了...真是... 代码如下: #pragma c ...
- JavaEE互联网轻量级框架整合开发(书籍)阅读笔记(5):责任链模式、观察者模式
一.责任链模式.观察者模式 1.责任链模式:当一个对象在一条链上被多个拦截器处理(烂机器也可以选择不拦截处理它)时,我们把这样的设计模式称为责任链模式,它用于一个对象在多个角色中传递的场景. 2. ...
- IIS 6.0 发布网站使用教程
原文地址:http://wenku.baidu.com/view/95d8b49851e79b89680226aa.html
- js实现深拷贝
type函数 首先我们要实现一个getType函数对元素进行类型判断,直接调用Object.prototype.toString 方法. function getType(obj){ //tostri ...
- Timer(定时器)
默认情况下,在每个采样器之前没有任何延时,这样不能很好的模拟现实生活中人们访问网页,因为现实生活中人们点击一个请求后,会有一定的时间,然后再点击下一个请求,JMeter提供了定时器来模拟这种行为. 定 ...
- React + Dva + Antd + Umi 概况
Dva 由阿里架构师 sorrycc 带领 team 完成的一套前端框架,在作者的 github 里是这么描述它的:"dva 是 react 和 redux 的最佳实践". Ant ...
- 洛谷P4014 分配问题(费用流)
传送门 可以把原图看做一个二分图,人在左边,任务在右边,求一个带权的最大和最小完美匹配 然而我并不会二分图做法,所以只好直接用费用流套进去,求一个最小费用最大流和最大费用最大流即可 //minamot ...