b站弹幕的爬取以及词云的简单使用
一.B站弹幕的爬取
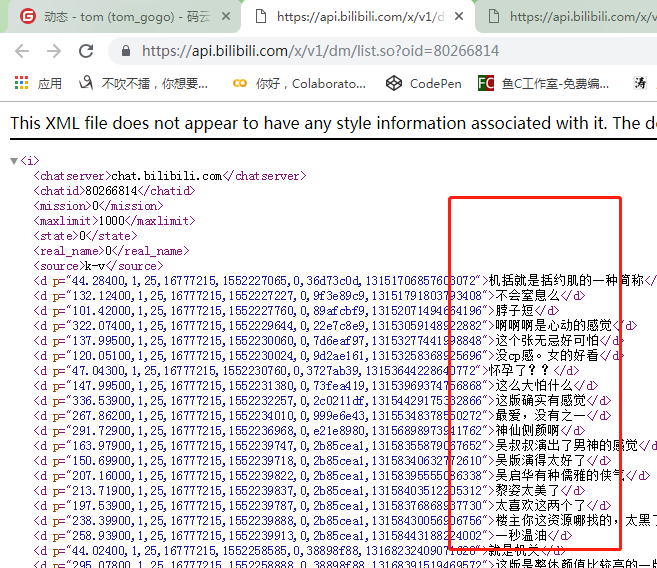
1.分析发现,其弹幕都是通过list.so?=cid这个文件加载出来的,所以我们找到这个文件的请求头的请求url,

2. 打开url就能看到所有的评论
3. 上代码,解析
#!/usr/bin/env python# -*- coding: utf-8 -*-
#author tom import requests
from lxml import etree
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
} #抓取函数
def yitianSpiderf(url):
res=requests.get(url,headers=headers)
tree=etree.HTML(res.content)
comment_list=tree.xpath('//d/text()')
with open('倚天评论.txt','a+',encoding='utf-8') as f:
for comment in comment_list:
f.write(comment+'\n') #主函数,其实所有是视频找到其id就能抓到所有的弹幕
def main():
cid=''
url='https://api.bilibili.com/x/v1/dm/list.so?oid={}'.format(cid)
yitianSpiderf(url) if __name__ == '__main__':
main()
4.词云:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom
import re
import jieba
from collections import Counter #使用结巴分词
with open('倚天评论.txt','r',encoding='utf-8') as f:
txt=f.read()
jbwords=jieba.cut(txt) #遇到这种非常规词不使用
with open('中文停用词表.txt' ,'r',encoding='utf-8') as f1:
stopwords=f1.read()
result=[]
for word in jbwords:
word=re.sub(r'[A-Za-z0-9\!?\%\[\]\,\.~]','',word) #去除英文符号
if word:
if word not in stopwords:
result.append(word)
'+++++++++++++++统计'
print('=====',result,len(result))
print(Counter(result)) #制作词云图
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
from PIL import Image
import numpy as np #指定字体,打开图片,转为数组
myfon=r'C:\Windows\Fonts\simkai.ttf'
# img1=Image.open('dog.jpg')
# graph1=np.array(img1)
img2=Image.open('1.png')
graph2=np.array(img2)
text='/'.join(result)
#词语对象
wc=WordCloud(font_path=myfon,background_color='white',max_font_size=50,max_words=500, mask=graph2)
wc.generate(text)
img_color=ImageColorGenerator(graph2)#从背景图中生成颜色值
plt.imshow(wc.recolor(color_func=img_color))
plt.imshow(wc)
plt.axis('off')
plt.show()
5. 效果:

二.关于B站直播弹幕的爬取
1. 分析发现,b站直播的弹幕存放在一个名为msg的文件当中
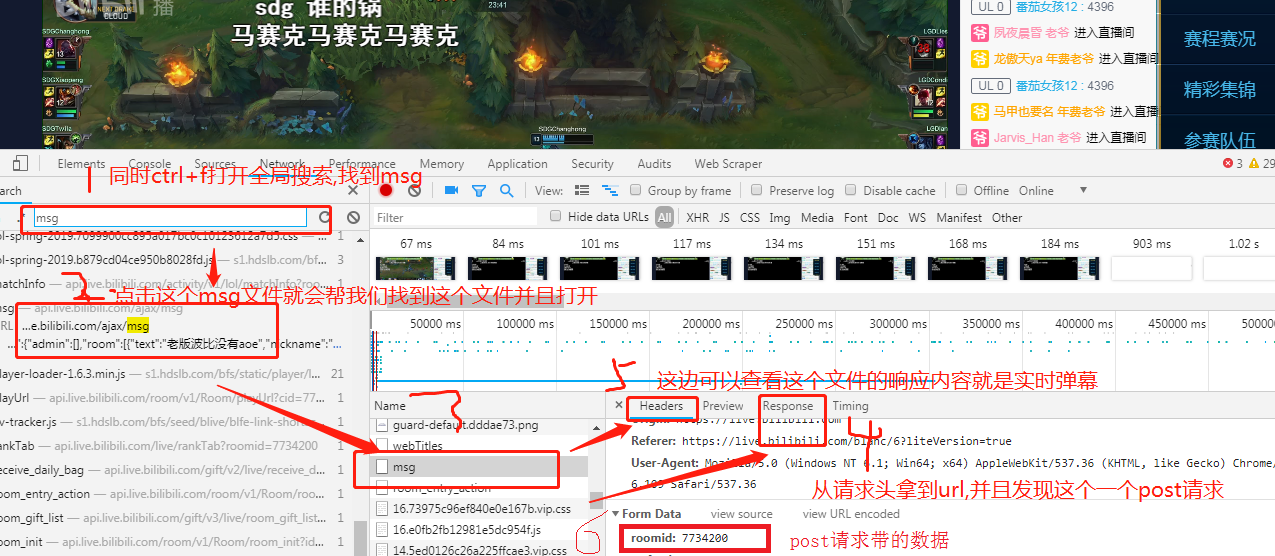
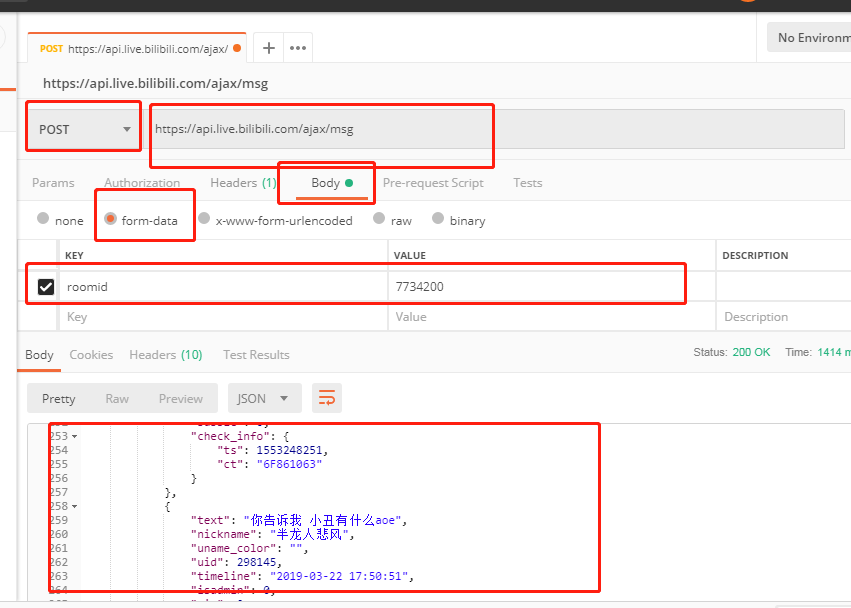
2.我们利用postman对这个网站发起post请求,果然可以拿到数据,
3.代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#author tom
import requests
import time
from jsonpath import jsonpath #抓取函数
def crawl(url,headers,data):
res=requests.post(url=url,headers=headers,data=data)
#拿到响应,res.json就直接转化成字典格式了,jsonpath要处理的也需要是一个python字典
#jsonpath第一个参数是python字典,第二个参数是匹配规则,这边代表的是从根目录递归搜索text和nicname
comment_list=jsonpath(res.json(),'$..text')
nicname_list=jsonpath(res.json(),'$..nickname')
#同时循环两个列表,需要用到zip打包
for (nicname,comment) in zip(nicname_list,comment_list):
dic={
'nicname':nicname,
'comment':comment
}
print(dic) def main():
url = 'https://api.live.bilibili.com/ajax/msg'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
data = {'roomid': ''}
#使用while循环最好呀睡觉,哪怕0.1也好,否则内存扛不住
while True:
crawl(url,headers,data)
time.sleep(2) if __name__ == '__main__':
main()
三.b站小视频的爬取
需求:爬取b站的小视频
url=url = http://vc.bilibili.com/p/eden/rank#/?tab=全部
1. 分析:打开这个网址我们发现这是一个ajax请求,并且这个请求里面包含了我们要的小视频地址
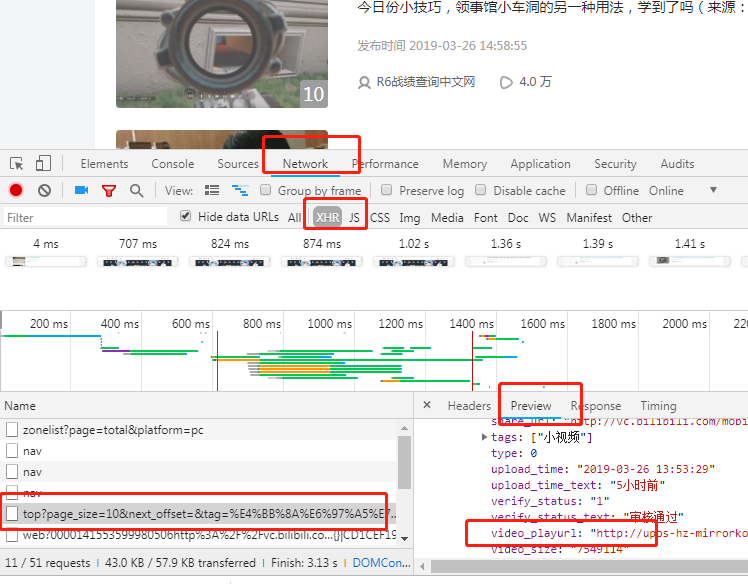
2.对vedio_playurl请求就直接把视频下载下来了

3. 上面的不方便查看,我们就对这个地址发起请求,利用jsonview来帮助查看
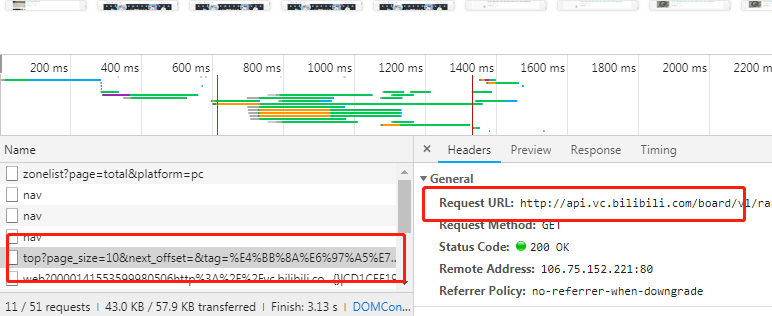
4.看一下请求结果
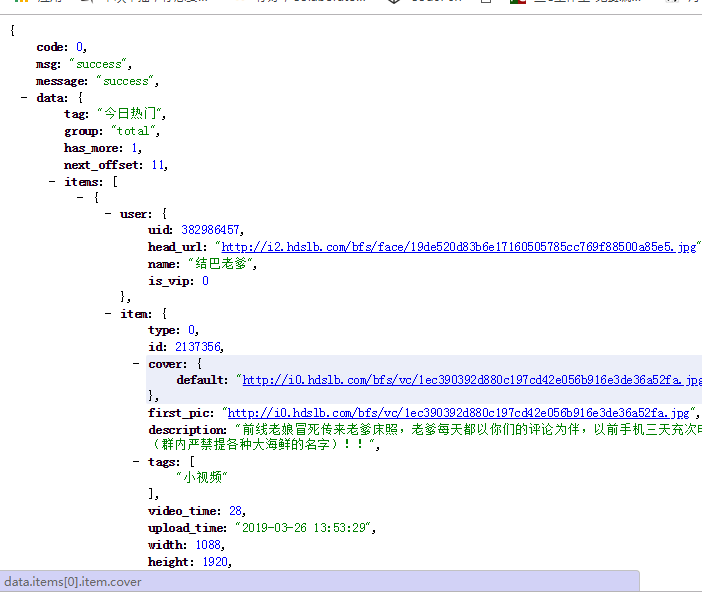
5.对ajax发起跟过请求

可以看到,带着参数就可以拿到欧更多的数据,现在知道怎么抓去了把
b站弹幕的爬取以及词云的简单使用的更多相关文章
- Python 爬取 热词并进行分类数据分析-[简单准备] (2020年寒假小目标05)
日期:2020.01.27 博客期:135 星期一 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备](本期博客) b.[云图制作+数据导入] ...
- Python 爬取 热词并进行分类数据分析-[云图制作+数据导入]
日期:2020.01.28 博客期:136 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入](本期博客) ...
- Python 爬取 热词并进行分类数据分析-[拓扑数据]
日期:2020.01.29 博客期:137 星期三 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[数据修复]
日期:2020.02.01 博客期:140 星期六 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- Python 爬取 热词并进行分类数据分析-[热词分类+目录生成]
日期:2020.02.04 博客期:143 星期二 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[ ...
- python爬虫爬取安居客并进行简单数据分析
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 爬取过程一.指定爬取数据二.设置请求头防止反爬三.分析页面并且与网页源码进行比对四.分析页面整理数据 ...
- bibli直播弹幕实时爬取
1 分析数据来源 在不知道弹幕信息在哪里的时候,只能去all里面查看每一个相应的信息,看信息是否含有弹幕信息 在知道弹幕信息文件的时候,我们可以直接用全局文件搜索,定位到弹幕数据文件.操作如下图 2 ...
- Python 爬取 热词并进行分类数据分析-[App制作]
日期:2020.02.14 博客期:154 星期五 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
随机推荐
- Vue.js组件调用用及其组件通信
1.需要import,然后components注册.然后如下代码调用. <template> <header></header> //注册后才能这样使用 <b ...
- Smarty3——变量修饰器
变量修饰器可以用于变量, 自定义函数或者字符串. 使用修饰器,需要在变量的后面加上|(竖线)并且跟着修饰器名称. 修饰器可能还会有附加的参数以便达到效果. 参数会跟着修饰器名称,用:(冒号)分开. 同 ...
- 半平面交 (poj 1279(第一道半平面NlogN)完整注释 )
半平面交的O(nlogn)算法(转载) 求n个半平面的交有三种做法: 第一种就是用每个平面去切割已有的凸多边形,复杂度O(n^2). 第二种就是传说中的分治算法.将n个半平面分成两个部分,分别求完交之 ...
- MVC下的cshtml和aspx页面
MVC中的aspx页面是System.Web.Mvc.ViewPage类的实例. 表示将视图呈现为 Web 窗体页所需的属性和方法. 继承层次结构 System.Object System.Web.U ...
- Discrete cosine transform(离散余弦转换)
A discrete cosine transform (DCT) expresses a finite sequence of data points in terms of a sum of co ...
- 【转】MOCK方法介绍
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://baidutech.blog.51cto.com/4114344/743740 1 ...
- XE中rectangle实现渐变
Fill -> Kind -> Gradient(选项) -> Gradient(Edit) 添加颜色即可
- 使用C#代码发送邮件,不完整的demo
作为一只入行不久的小菜鸟,最近接触到利用C#代码发送邮件,做了一点小的demo练习.首先,需要配置,这边我做的是QQ邮箱的相关的练习,练习之前,首先应该解决的问题肯定是关于服务器的配置,这边偷一个懒, ...
- angular 基本依赖注入
import { Injectable } from '@angular/core'; @Injectable() export class ProductServiceService { const ...
- 自建脚手架之配置中心--LightConf的实现
常规项目开发过程中, 通常会将配置信息位于在项目resource目录下的properties文件文件中, 配置信息通常包括有: jdbc地址配置.redis地址配置.活动开关--等等.因此每次上线或者 ...