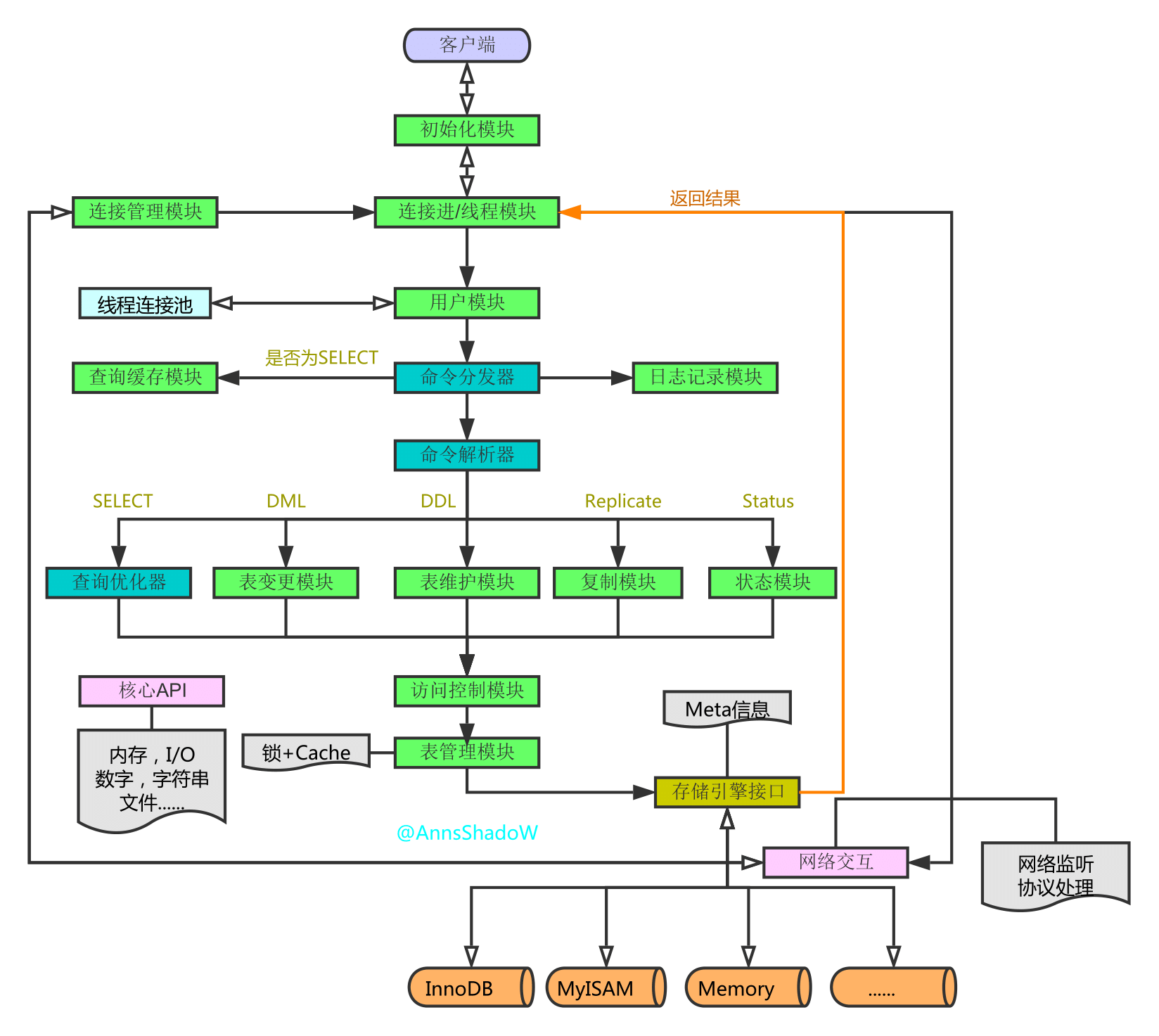
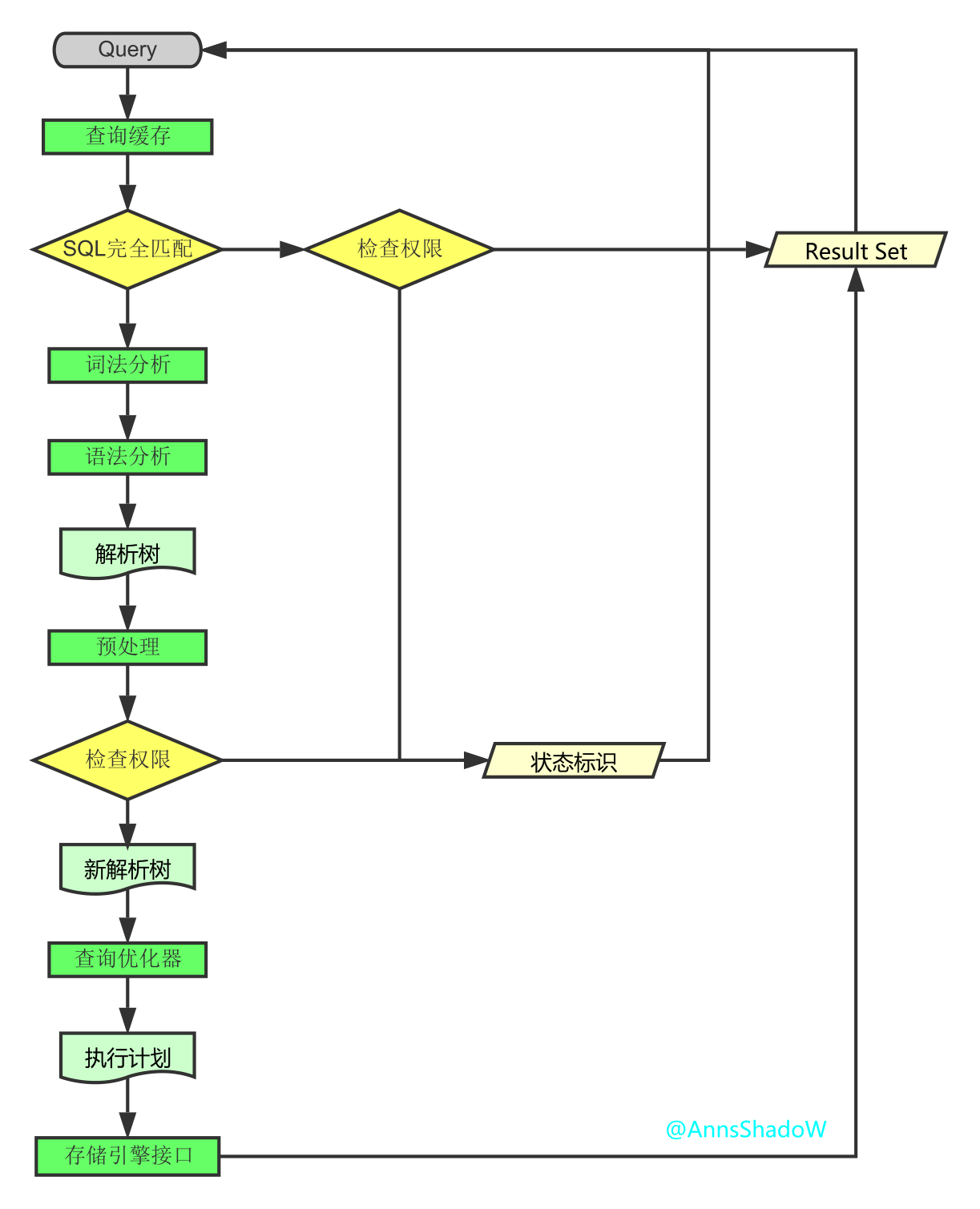
MySQL架构体系-SQL查询执行全过程解析
前言:
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)

mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)
MySQL架构体系-SQL查询执行全过程解析的更多相关文章
- mysql体系结构和sql查询执行过程简析
一: mysql体系结构 1)Connectors 不同语言与 SQL 的交互 2)Management Serveices & Utilities 系统管理和控制工具 备份和恢复的安全性,复 ...
- sql查询语句如何解析成分页查询?
我们公司主要mysql存储数据,因此也封装了比较好用mysql通用方法,然后,我们做大量接口,在处理分页查询接口,没有很好分查询方法.sql查询 语句如何解析成“分页查询”和“总统计”两条语句.可能, ...
- mysql explain 查看sql语句执行计划概述
mysql explain 查看sql语句执行计划概述 id:选择标识符select_type:表示查询的类型.table:输出结果集的表partitions:匹配的分区type:表示表的连接类型po ...
- MySQL架构与SQL执行流程
MySQL架构设计 下面是一张MySQL的架构图: 上方各个组件的含义如下: Connectors 指的是不同语言中与SQL的交互 Management Serveices & Utiliti ...
- MySql基础架构以及SQL语句执行流程
01. mysql基础架构 SQL语句是如何执行的 学习一下mysql的基础架构,从一条sql语句是如何执行的来学习. 一般我们写一条查询语句类似下面这样: select user,password ...
- MySQL开启日志记录查询/执行过的SQL语句
作为后端开发者,遇到数据库问题的时候应该通过分析SQL语句来跟进问题所在,该方法可以记录所有的查询/执行的SQL语句到日志文件. 方法有几种,但是个人觉得以下这种最简单,但是重启MySQL服务后需要重 ...
- mysql系列-⼀条SQL查询语句是如何执⾏的?
⼀条SQL查询语句是如何执⾏的? ⼤体来说,MySQL 可以分为 Server 层和存储引擎层两部分 Server 层 Server 层包括连接器.查询缓存.分析器.优化器.执⾏器等,涵盖 MySQL ...
- 3、myql的逻辑架构和sql的执行流程
msyql逻辑架构 逻辑架构的解析 逻辑架构图如下(序号代表的是:服务器处理客户端请求的流程) 1.1connectors connectors是指使用不同语言的客户端与mysql server服务器 ...
- sql 查询执行的详细时间profile
1.查看profile的设置 SHOW VARIABLES LIKE '%profil%' 结果如下:profiling OFF 为关闭状态 2.开启profile 结果: 3.执行需要执行的sql ...
- Mysql explain分析sql语句执行效率
mysql优化–explain分析sql语句执行效率 Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 ...
随机推荐
- Ros环境创建相关!超级简单!!超级详细!!
1.创建工作空间workspace 其中catkin_ws后面的ws是work_space的简写,指代工作空间 <catkin_ws是你的工作空间的名字,随便取> mkdir -p ~/c ...
- 『玩转Streamlit』--登录认证机制
如果你的Streamlit App中使用的数据的比较敏感,那么,保护这个App及其背后的数据免受未授权访问变得至关重要. 无论是出于商业机密的保护.用户隐私的维护,还是为了满足日益严格的合规要求,确保 ...
- AbstractQueuedSynchronizer源码解析之ReentrantLock(二)
上篇文章分析了ReentrantLock的lock,tryLock,unlock方法,继续分析剩下的方法,首先开始lockInterruptibly,先看其API说明:lockInterruptibl ...
- 解决window.close()在谷歌浏览器不起作用
简单明了直接上解决方法: let url = ' '; // 空字符串中间要加空格 window.open(url, '_self').close();
- linux之Zip
安装: apt-get) apt-get install zip yum) yum install -y unzip zip 语法: zip [选项] 压缩包名 源文件或源目录列表 注意,zip 压缩 ...
- 数据同步之DataX
目前业务中需要进行数据同步, 考虑使用datax数据同步方式替换掉现有的同步方式 业务场景: 即将业务中每天生成的日志表中的数据部分字段同步到自己的库中,进行后台数据的查询 起因: 之前"大 ...
- groovy 内存回收测试
问题 在使用我们的开发平台时,客户怀疑我们的动态执行脚本会导致系统内存回收的问题,导致系统不响应,为此我专门针对这个问题,做一下详细的测试,看看是不是到底有什么影响. 测试步骤 1.使用编写一个控制器 ...
- Net中RabbitMq.Client7.0通过依赖注入DI来管理RabbitMQ客户端的生命周期
在 RabbitMQ.Client 7.0.0 版本中, IModel 在 RabbitMQ.Client 7.0.0-alpha2 版本中已经被重命名,现在应该使用 IChannel 替代 IMod ...
- Java基础 —— 反射
动态语言 动态语言,是指程序在运行时可以改变其结构(新函数可以引进,已有的函数可以被删除等结构上的变化).如:JavaScript.Python就属于动态语言,而C.C++则不属于动态语言,从反射的 ...
- uniapp开发鸿蒙,是前端新出路吗?
相信不少前端从业者一听uniapp支持开发鸿蒙Next后非常振奋.猫林老师作为7年前端er也是非常激动,第一时间体验了下.在这里也给大家分享一下我的看法 对于前端开发者而言,几乎无需增加额外的学习成本 ...