数据库数据实时采集--Maxwell
1、Maxwell 简介
Maxwell 是一个能实时读取 MySQL 二进制日志文件binlog,并生成 Json格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、
Google Cloud Pub/Sub、文件或其它平台的应用程序。它的常见应用场景有ETL、维护缓存、收集表级别的dml指标、增量到搜索引擎、数据分区迁移、
切库binlog回滚方案等。Maxwell主要提供了下列功能
- 支持SELECT * FROM table的方式进行全量数据初始化。
- 支持在主库发生failover后,自动恢复binlog位置,实现断点续传。
- 可以对数据进行分区,解决数据倾斜问题,发送到Kafka的数据支持库、表、列等级别的数据分区。
- 工作方式是伪装为slave接收binlog events,然后根据schema信息拼装,可以接受ddl、xid、row等event。
2、Mysql Binlog介绍
2.1 Binlog 简介
MySQL中一般有以下几种日志
日志类型 写入日志的信息 错误日志 记录在启动,运行或停止mysqld时遇到的问题 通用查询日志 记录建立的客户端连接和执行的语句 二进制日志 binlog 记录更改数据的语句 中继日志 从服务器 复制 主服务器接收的数据更改 慢查询日志 记录所有执行时间超过 long_query_time秒的所有查询或不使用索引的查询DDL日志(元数据日志) 元数据操作由DDL语句执行 在默认情况下,系统仅仅打开错误日志,关闭了其他所有日志,以达到尽可能减少IO损耗提高系统性能的目的,但是在一般稍微重要一点的实际应用场景中,都至少需要打开二进制日志,因为这是MySQL很多存储引擎进行增量备份的基础,也是MySQL实现复制的基本条件
接下来主要介绍二进制日志 binlog。
- MySQL 的二进制日志 binlog 可以说是 MySQL 最重要的日志,它记录了所有的
DDL和DML语句(除了数据查询语句select、show等),以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。binlog 的主要目的是复制和恢复。
- MySQL 的二进制日志 binlog 可以说是 MySQL 最重要的日志,它记录了所有的
Binlog日志的两个最重要的使用场景
- MySQL主从复制
- MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
- 数据恢复
- 通过使用 mysqlbinlog工具来使恢复数据。
- MySQL主从复制
2.2 Binlog 的日志格式
记录在二进制日志中的事件的格式取决于二进制记录格式。支持三种格式类型:
- Statement:基于SQL语句的复制(statement-based replication, SBR)
- Row:基于行的复制(row-based replication, RBR)
- Mixed:混合模式复制(mixed-based replication, MBR)
Statement
- 每一条会修改数据的sql都会记录在binlog中。
- 优点
- 不需要记录每一行的变化,减少了binlog日志量,节约了IO, 提高了性能。
- 缺点
- 在进行数据同步的过程中有可能出现数据不一致。
- 比如 update tt set create_date=now(),如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
Row
- 它不记录sql语句上下文相关信息,仅保存哪条记录被修改。
- 优点
- 保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,它只记录执行后的效果。
- 缺点
- 每行数据的修改都会记录,最明显的就是update语句,导致更新多少条数据就会产生多少事件,占用较大空间。
Mixed
- 从5.1.8版本开始,MySQL提供了Mixed格式,实际上就是Statement与Row的结合。
- 在Mixed模式下,一般的复制使用Statement模式保存binlog,对于Statement模式无法复制的操作使用Row模式保存binlog, MySQL会根据执行的SQL语句选择日志保存方式(因为statement只有sql,没有数据,无法获取原始的变更日志,所以一般建议为Row模式)。
- 优点
- 节省空间,同时兼顾了一定的一致性。
- 缺点
- 还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
3、Mysql 实时数据同步方案对比
mysql 数据实时同步可以通过解析mysql的 binlog 的方式来实现,解析binlog可以有多种方式,可以通过canal,或者maxwell等各种方式实现。以下是各种抽取方式的对比介绍。

其中
canal由 Java开发,分为服务端和客户端,拥有众多的衍生应用,性能稳定,功能强大;canal 需要自己编写客户端来消费canal解析到的数据。Maxwell相对于canal的优势是使用简单,Maxwell比Canal更加轻量级,它直接将数据变更输出为json字符串,不需要再编写客户端。对于缺乏基础建设,短时间内需要快速迭代的项目和公司比较合适。
另外
Maxwell有一个亮点功能,就是Canal只能抓取最新数据,对已存在的历史数据没有办法处理。而Maxwell有一个bootstrap功能,可以直接引导出完整的历史数据用于初始化,非常好用。
4、开启Mysql的Binlog
1、服务器当中安装mysql(省略)
- 注意:mysql的版本尽量不要太低,也不要太高,最好使用5.6及以上版本。
2、添加mysql普通用户
maxwell为mysql添加一个普通用户maxwell,因为maxwell这个软件默认用户使用的是maxwell这个用户。
进入mysql客户端,然后执行以下命令,进行授权
mysql -uroot -p123456
执行sql语句
--校验级别最低,只校验密码长度
mysql> set global validate_password_policy=LOW;
mysql> set global validate_password_length=6; --创建maxwell库(启动时候会自动创建,不需手动创建)和用户
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY '123456';
mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%';
mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE on *.* to 'maxwell'@'%';
--刷新权限
mysql> flush privileges;
3、修改配置文件
/etc/my.cnf执行命令 sudo vim /etc/my.cnf, 添加或修改以下三行配置
#binlog日志名称前缀
log-bin= /var/lib/mysql/mysql-bin #binlog日志格式
binlog-format=ROW #唯一标识,这个值的区间是:1到(2^32)-1
server_id=1
4、重启mysql服务
执行如下命令
sudo service mysqld restart
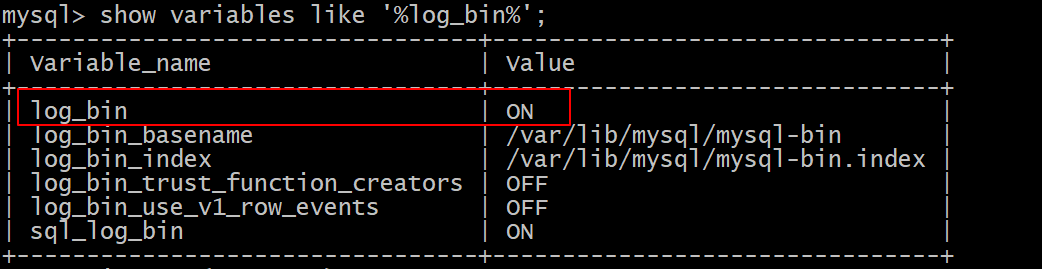
5、验证binlog是否配置成功
进入mysql客户端,并执行以下命令进行验证
mysql -uroot -p123456
mysql> show variables like '%log_bin%';
6、查看binlog日志文件生成
进入
/var/lib/mysql目录,查看binlog日志文件.
Maxwell安装部署
1、下载对应版本的安装包
- 地址:https://github.com/zendesk/maxwell/releases/download/v1.21.1/maxwell-1.21.1.tar.gz
- 安装包名称:
maxwell-1.21.1.tar.gz
2、上传服务器,这里我们选择在hadoop03节点安装Maxwell
3、解压安装包到指定目录
tar -zxvf maxwell-1.21.1.tar.gz -C /bigdata/install/
4、修改Maxwell配置文件
- 进入到安装目录
/bigdata/install/maxwell-1.21.1进行如下操作
cd /bigdata/install/maxwell-1.21.1
cp config.properties.example config.properties
vim config.properties
- 配置文件
config.properties内容如下:
# choose where to produce data to
producer=kafka
# list of kafka brokers
kafka.bootstrap.servers=hadoop01:9092,hadoop02:9092,hadoop03:9092
# mysql login info
host=hadoop03
port=3306
user=maxwell
password=123456
# kafka topic to write to
kafka_topic=maxwell
- 注意:一定要保证使用
maxwell用户和123456密码能够连接上mysql数据库。
- 进入到安装目录
Maxwell实时采集mysql表数据到kafka
1、启动kafka集群和zookeeper集群
启动zookeeper集群
[hadoop@hadoop01 bin]zk.sh start
启动kafka集群
[hadoop@hadoop01 bin]kafka.sh start
2、创建topic
[hadoop@hadoop01 ~]kafka-topics.sh --create --topic maxwell --partitions 3 --replication-factor 2 --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
3、启动maxwell服务
[hadoop@hadoop03 ~]/bigdata/install/maxwell-1.21.1/bin/maxwell
4、进入hadoop02的mysql数据库,插入数据并进行测试
- 向mysql当中创建数据库和数据库表,向表中插入一条数据。
CREATE DATABASE `test_db`; USE `test_db`; /*Table structure for table `user` */ DROP TABLE IF EXISTS `user`; CREATE TABLE `user` (
`id` varchar(10) NOT NULL,
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; /*Data for the table `user` */
#插入数据
insert into `user`(`id`,`name`,`age`) values ('1','xiaokai',20);
#修改数据
update `user` set age= 30 where id='1';
#删除数据
delete from `user` where id='1';
- 向mysql当中创建数据库和数据库表,向表中插入一条数据。
5、启动kafka的自带控制台消费者
测试maxwell主题是否有数据进入
[hadoop@hadoop01 ~]kafka-console-consumer.sh --topic maxwell --bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 --from-beginning
SHELL 复制 全屏观察输出结果
{"database":"test_db","table":"user","type":"insert","ts":1621244407,"xid":985,"commit":true,"data":{"id":"1","name":"xiaokai","age":20}} {"database":"test_db","table":"user","type":"update","ts":1621244413,"xid":999,"commit":true,"data":{"id":"1","name":"xiaokai","age":30},"old":{"age":20}} {"database":"test_db","table":"user","type":"delete","ts":1621244419,"xid":1013,"commit":true,"data":{"id":"1","name":"xiaokai","age":30}}
数据库数据实时采集--Maxwell的更多相关文章
- 大数据学习——采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs 根据需求,首先定义以下3大要素 l 采集源,即source——监控文件内容更新 : ...
- 实时采集MySQL数据之轻量工具Maxwell实操
@ 目录 概述 定义 原理 Binlog说明 Maxwell和Canal的区别 部署 安装 MySQL准备 初始化Maxwell元数据库 Maxwell进程启动 命令行参数 配置文件 实时监控Mysq ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 测试环境 环境搭建 使用前提 使用方法 运行程序 效果展 ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机或Docker容器性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 3 使用前提 3 使用方法 ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- DirectSound播放PCM(可播放实时采集的音频数据)
前言 该篇整理的原始来源为http://blog.csdn.net/leixiaohua1020/article/details/40540147.非常感谢该博主的无私奉献,写了不少关于不同多媒体库的 ...
- Sqlserver2000联系Oracle11G数据库进行实时数据的同步
Sqlserver2000联系Oracle11G数据库进行实时数据的同步 1,前提条件 我有sqlserver2000环境,已经存在oracle11g环境,准备这两个数据库,建立各自的訪问账号,两者之 ...
- 采用Flume实时采集和处理数据
它已成功安装Flume在...的基础上.本文将总结使用Flume实时采集和处理数据,详细过程,如下面: 第一步,在$FLUME_HOME/conf文件夹下,编写Flume的配置文件,命名为flume_ ...
- Flume和Kafka完成实时数据的采集
Flume和Kafka完成实时数据的采集 写在前面 Flume和Kafka在生产环境中,一般都是结合起来使用的.可以使用它们两者结合起来收集实时产生日志信息,这一点是很重要的.如果,你不了解flume ...
- 大数据实时多维OLAP分析数据库Apache Druid入门分享-上
@ 目录 概述 定义 MPP和Lambda补充说明 概述 特征 适用场景 不适用场景 横向对比 部署 单机部署 入门示例 概述 定义 Apache Druid 官网地址 https://druid.a ...
随机推荐
- 4年经验来面试20K的测试岗,连基础都不会,还不如招应届生。
公司前段时间缺人,也面了不少测试,结果竟然没有一个合适的.一开始瞄准的就是中级的水准,也没指望来大牛,提供的薪资在10-20k,面试的人很多,但平均水平很让人失望.看简历很多都是3.4年工作经验,但面 ...
- 如何看待:以色列在真主党订购的5000台寻呼机中放了TNT
日常生活等关键物品的生产必须要有国内完全掌握,美国.日本.以色列等国惯用的这种暗杀方法.如果不能在本国国内做到自主可控的产品生产,那么无疑是把自己的脑袋交给敌人来保护,随时都有丢命的可能. 同时,这也 ...
- VLAN技术
VLAN是虚拟局域网的缩写,它是一种将网络设备(如交换机.路由器等)分割成多个虚拟网络的技术.每个VLAN都是一个独立的广播域,使得可以在同一物理网络上创建多个逻辑网络,从而提高网络的安全性和灵活性. ...
- An expression evaluator
An expression evaluator Download source code (17 kb) Two weeks ago, I saw an article on codeproject ...
- Codeforces Round 890 (Div. 2)
Tales of a Sort 题解 找到最大的能够产生逆序对的数即可 暴力\(O(n^2)\)枚举即可 const int N = 2e5 + 10, M = 4e5 + 10; int n; in ...
- Mybatis【5】-- Mybatis多种增删改查那些你会了么?
前面我们学会了Mybatis如何配置数据库以及创建SqlSession,那怎么写呢?crud怎么写? 代码直接放在Github仓库[https://github.com/Damaer/Mybatis- ...
- mysql 自定义函数写法
1.业务场景 有时候我们希望通过sql语句解决一些复杂的问题,比如根据一个ID 查询组织的路径.这个时候我们可以使用函数来实现. 2.函数编写 CREATE FUNCTION getGroupById ...
- 关于tomcat在idea上的中文编码问题
一.问题引入 在国内,无论是新手还是有一定码龄的开发人员,汉字编码问题一直都是绕不开的魔咒,本文主要对tomcat在jetbrain系列产品idea上的乱码问题提供解决经验. 二.详情描述 新手在初学 ...
- 生成条形码二维码DataMatrix条码.EAN码.39码.交叉25码.UPC码.128码.93码.ISBN码.Codabar等
1.引用Spire.Barcode 在Nuget包中安装Spire.Barcode 2.生成条形码 //创建 BarcodeSettings对象 BarcodeSettings settings = ...
- Scrum 和我主张的管理方式的同与异
虽然零零星星接触过scrum的一些知识,之前并没有深入了解过.这次机缘巧合,将 Jeff Sutherland 的<用一半的时间做两倍的事>拜读完毕,感觉 scrum 的做法其实很多和我自 ...