大数据学习——采集文件到HDFS
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
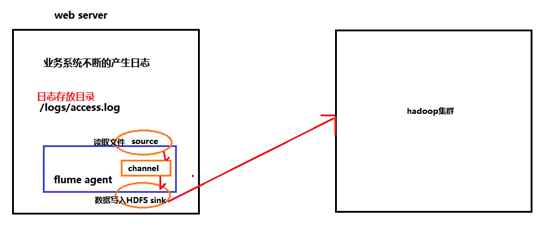
根据需求,首先定义以下3大要素
l 采集源,即source——监控文件内容更新 : exec ‘tail -F file’
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
vi exec-hdfs-sink.conf
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure tail -F source1
agent1.sources.source1.type = exec
agent1.sources.source1.command = tail -F /root/logs/access_log
agent1.sources.source1.channels = channel1
#configure host for source
agent1.sources.source1.interceptors = i1 i2
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#agent1.sources.source1.interceptors.i1.useIP=true 表示使用ip地址或者主机名
agent1.sources.source1.interceptors.i1.useIP=false
agent1.sources.source1.interceptors.i2.type = timestamp
# Describe sink1
agent1.sinks.sink1.type = hdfs
#a1.sinks.k1.channel = c1
agent1.sinks.sink1.hdfs.path=hdfs://mini1:9000/file/%{hostname}/%y-%m-%d/%H-%M
agent1.sinks.sink1.hdfs.filePrefix = access_log
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
agent1.sinks.sink1.hdfs.rollSize = 10240
agent1.sinks.sink1.hdfs.rollCount = 1000
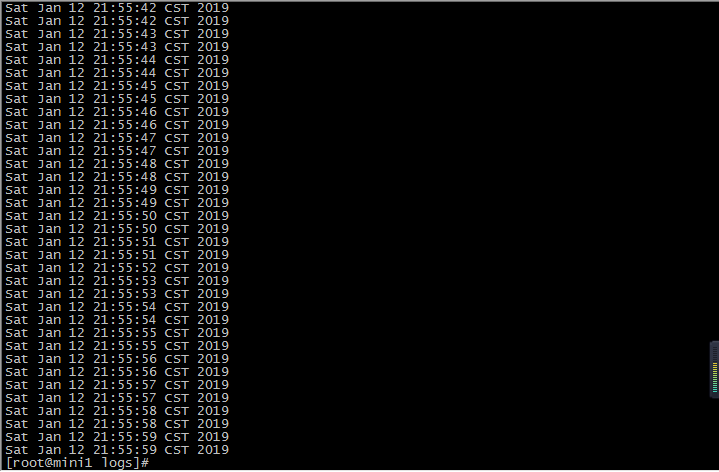
模拟数据
mkdir logs
cd logs
while true; do date >>access_log ;sleep 0.5s; done

启动
bin/flume-ng agent -c conf -f conf/exec-hdfs-sink.conf -n agent1 -Dflume.root.logger=INFO,console
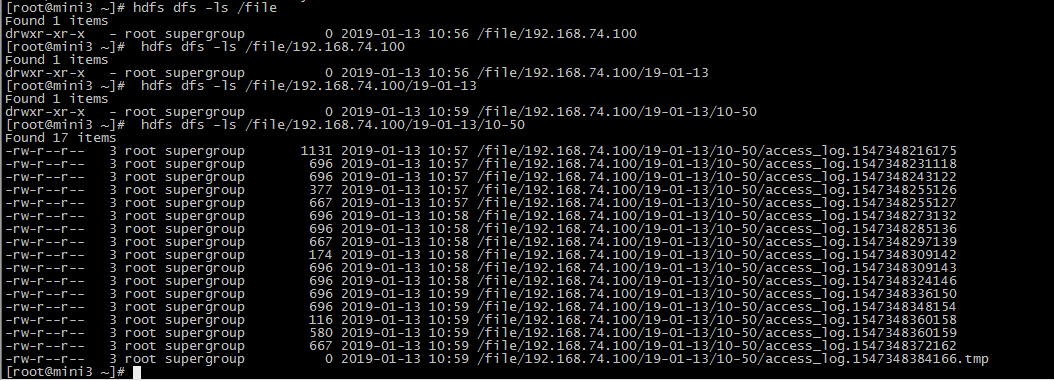
查看结果
大数据学习——采集文件到HDFS的更多相关文章
- 大数据学习——采集目录到HDFS
采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去 根据需求,首先定义以下3大要素 l 采集源,即source——监控文件目录 : spoold ...
- 大数据学习(一)-------- HDFS
需要精通java开发,有一定linux基础. 1.简介 大数据就是对海量数据进行数据挖掘. 已经有了很多框架方便使用,常用的有hadoop,storm,spark,flink等,辅助框架hive,ka ...
- 大数据学习之旅1——HDFS版本演化
最近开始学习大数据,发现大数据有很多很多组件,我现在负责的是HDFS(Hadoop分布式储存系统)的学习,整理了一下HDFS的版本情况.因为HDFS是Hadoop的重要组成部分,所以有关HDFS的版本 ...
- 大数据学习(02)——HDFS入门
Hadoop模块 提到大数据,Hadoop是一个绕不开的话题,我们来看看Hadoop本身包含哪些模块. Common是基础模块,这个是必须用的.剩下常用的就是HDFS和YARN. MapReduce现 ...
- 大数据学习第二章、HDFS相关概念
1.HDFS核心概念: 块 (1)为了分摊磁盘读写开销也就是大量数据间分摊磁盘寻址开销 (2)HDFS块比普通的文件块大很多,HDFS默认块大小为64MB,普通的只有几千kb 原因:1.支持面向大规模 ...
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- 大数据学习(2)HDFS文件管理
命令行管理HDFS [root@server1 bin]# hadoop fs Usage: hadoop fs [generic options] [-appendToFile <locals ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
随机推荐
- 牛客国庆集训派对Day_1~3
Day_1 A.Tobaku Mokushiroku Kaiji 题目描述 Kaiji正在与另外一人玩石头剪刀布.双方各有一些代表石头.剪刀.布的卡牌,每局两人各出一张卡牌,根据卡牌的内容决定这一局的 ...
- [在读]functional javascript
讲javascript函数化编程的一本书,逛淘宝正好看到有一家卖英文书的,顺手就买了,目前搁置.
- Vijos p1688 病毒传递 树形DP
https://vijos.org/p/1688 看了下别人讨论的题解才想到的,不过方法和他的不同,感觉它的是错的.(感觉.感觉) 首先N只有1000, 如果能做到暴力枚举每一个节点,然后O(N)算出 ...
- 分布式数据存储 之 Redis(一) —— 初识Redis
分布式数据存储 之 Redis(一) -- 初识Redis 为什么要学习并运用Redis?Redis有什么好处?我们步入Redis的海洋,初识Redis. 一.Redis是什么 Redis 是一个 ...
- pre-network android 网络优化预加载框架
网络优化是所有app开发中非常重要的一部分,如果将网络请求前置就是在点击跳转activity之前开始网络加载那么速度将会有质的提升.也就是网络预先加载框框架. 网络预加载框架,监听式网络前置加载框架- ...
- python中的get函数
>>> a={1:'a',2:'b'}>>> print a.get(1)a>>> print a.get(3)None
- 激活eclipse自动提示功能
eclipse设置: Window->Preferences->Java->Editor->Content Assist
- 设置QtreeWidget水平滚动条
转载请注明出处:http://www.cnblogs.com/dachen408/p/7552603.html //设置treewidget水平滚动条 ui.treeWidget->header ...
- css广告弹窗满屏跑
window.onload=function(){ //广告滚动 var oneInner = $('#divid')[0]; //定时器 var a1a = setInterval(moves,10 ...
- SQL Server数据库锁机制及类型
原文地址:http://blog.csdn.net/zp752963831/article/details/3906477