开源超闭源!通义千问Qwen2发布即爆火,网友:GPT-4o危
鱼羊发自凹非寺量子位公众号 QbitAI
开源大模型全球格局,一夜再变。
这不,全新开源大模型亮相,性能全面超越开源标杆 Llama 3。王座易主了。不是“媲美”、不是“追上”,是全面超越。发布两小时,直接冲上 HggingFace 开源大模型榜单第一。
这就是最新一代开源大模型 Qwen2,来自通义千问,来自阿里巴巴。
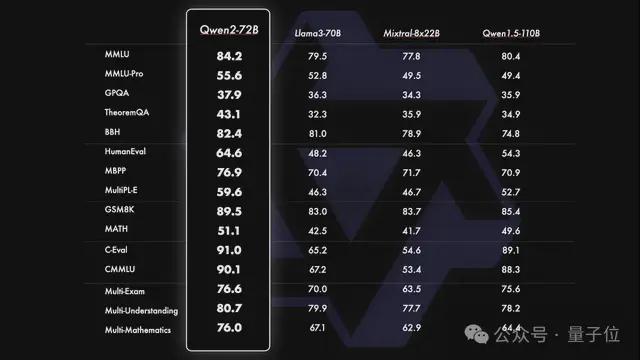
在十几项国际权威测评中,Qwen2-72B 得分均胜过 Llama3-70B,尤其在 HumanEval、MATH 等测试代码和数学能力的基准中表现突出。
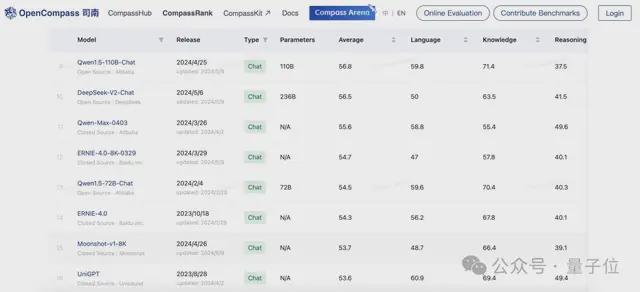
不仅如此,作为国产大模型,Qwen2-72B 也“毕其功于一役”,超过了国内一众闭源大模型:
Qwen2-72B 相比于自家前代模型 Qwen1.5-110B 实现了整体性能的代际提升,而在上海 AI Lab 推出的 OpenCompass 大模型测评榜单上,Qwen1.5-110B 已经超过了文心4、Moonshot-v1-8K 等一众国内闭源模型。随着 Qwen2-72B 的问世,这一领先优势还在扩大。
有网友便感慨说:这还只是刚开始。开源模型很可能在未来几个月,就能击败 GPT-4o 为代表的闭源模型。
Qwen2 的发布,可以说是一石激起千层浪。
上线仅 1 天,下载量已经超过 3 万次。
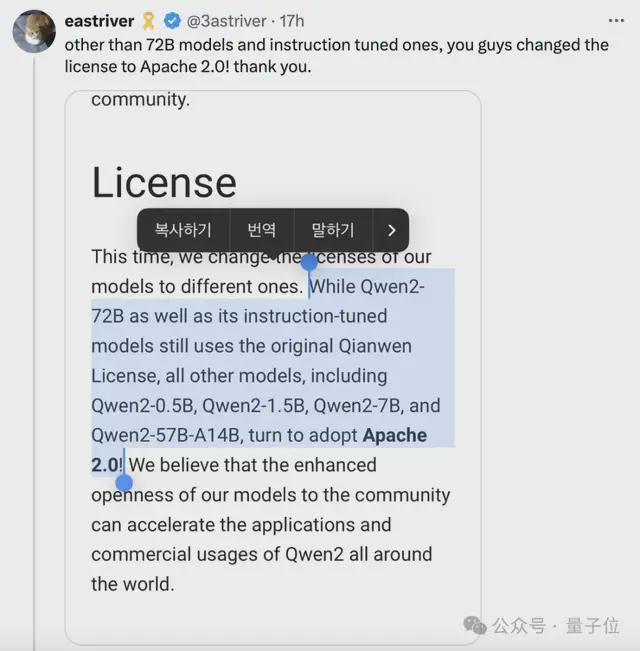
网友们还发现,除了 72B 和指令调优版本,这次同步开源的 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B,开源许可都换成了 Apache 2.0——
就是说可以更加自由地商用。这是 Llama 3 系列都没做到的。
在 AI 大模型领域,时间和速度都不同了。
因为距离阿里推出 Qwen1.5-110B 模型刷新 SOTA,全球开源大模型形成双雄格局,才刚过去 1 个月时间。
而现在,Qwen2 独领风骚,全球开源第一,国产大模型第一——连不开源的大模型都超越了。
Qwen2 挑战高考数学真题
还是先来整体梳理一下 Qwen2 的基本情况。
根据官方技术博客介绍,Qwen2 的特点和相比 Qwen1.5 的主要升级包括:
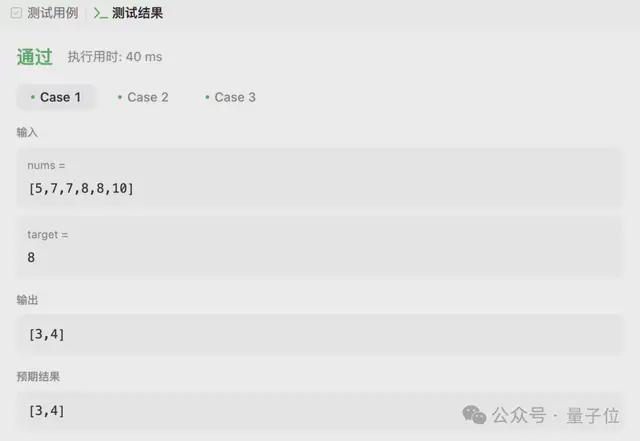
- 发布 5 个尺寸的预训练和指令微调模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 以及 Qwen2-72B。其中 Qwen2-57B-A14B 是一个 MoE 模型。
- 在中文英语的基础上,对 27 种语言进行了增强。有阿拉伯语开发者表示,Qwen 已经成为 4 亿阿拉伯语用户喜欢的大模型,稳居阿拉伯语开源模型榜单第一。
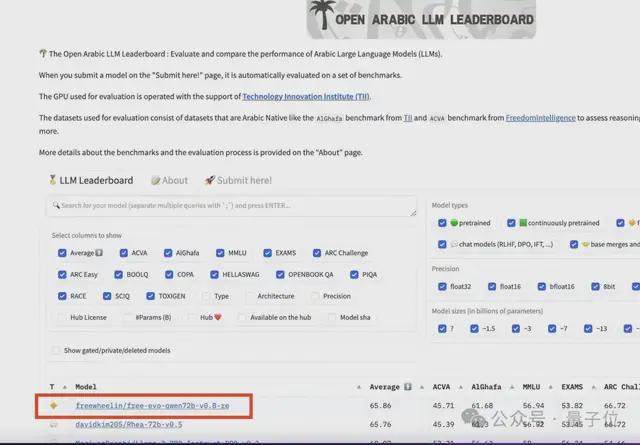
- 在 MMLU、GPQA、HumanEval、GSM8K、BBH、MT-Bench、Arena Hard、LiveCodeBench 等国际权威测评中,Qwen2-72B 斩获十几项世界第一,超过 Llama 3。
- 代码和数学能力显著提升。
- 增大了上下文长度支持,最长实现 128K tokens 上下文长度支持(Qwen2-7B-Instruct 和 Qwen2-72B-Instruct)。
纸面数据上,Qwen2 在开源大模型中已经达成全球最强,那么实际表现又会如何?
我们用新鲜出炉的高考数学真题上手实测了一波。
先来个简单题:已知集合A={x-5<x^3<5},B={-3,-1,0,2,3},则A∩B=()
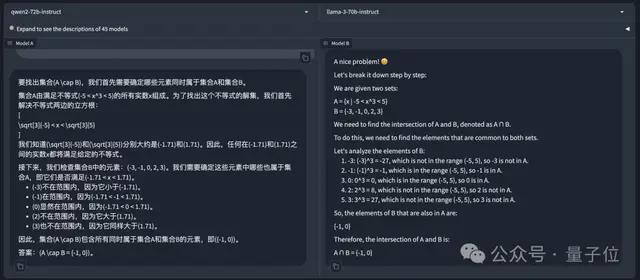
左边是 Qwen2-72B-Instruct,右边是 Llama-3-70B-Instruct。除了 Llama 3 原版的老问题不咋支持中文外,两边的答案都是正确的。
那么就稍微上点难度:当x∈[0, 2π]时,曲线y=sinx 与y=2sin (3x-π/6) 的交点个数为?
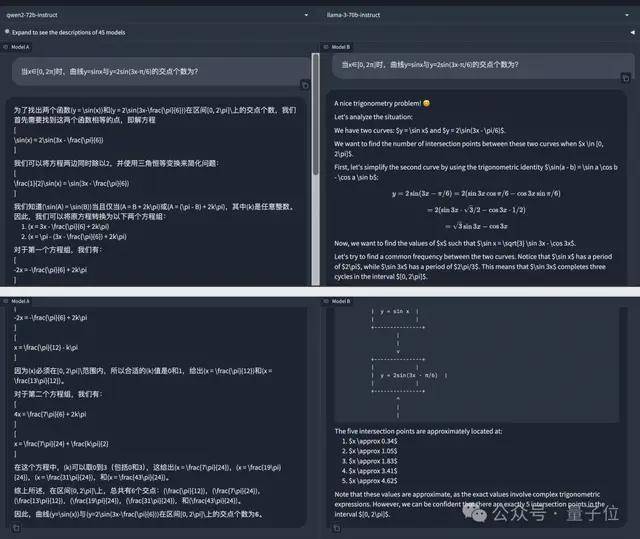
Qwen2-72B-Instruct 依然没有被难住,一通计算后给出正确答案:交点个数为 6 个。
而 Llama-3-70B-Instruct 则计算错误,扣 5 分。
Qwen2 在数学能力方面,已经到了高考考场接受真题检验的水平。
通义千问此番升级,官方和评测数据还突出了代码能力的提升,我们也有 LeetCode 中等难度真题浅测了一下:给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。如果数组中不存在目标值 target,返回 [-1, -1]。你必须设计并实现时间复杂度为 O (log n) 的算法解决此问题。

Qwen2-72B-Instruct 给出的 python 实现如下:
defsearchRange (nums, target):defbinary_search_left (nums, target):
left, right =0, len (nums) whileleft < right:
mid = (left + right) //2ifnums[mid] < target:
left = mid +1else:
right = midreturn left
defbinary_search_right (nums, target):
left, right =0, len (nums) whileleft < right:
mid = (left + right) //2ifnums[mid] <= target:
left = mid +1else:
right = midreturn left
left, right = binary_search_left (nums, target), binary_search_right (nums, target) return[left, right -1]ifleft <= right -1andnums[left] == targetandnums[right -1] == targetelse[-1,-1]
一开始没有定义 Solution 类导致报错,不过直接把报错信息反馈给 Qwen2,它自己就能完成 debug:
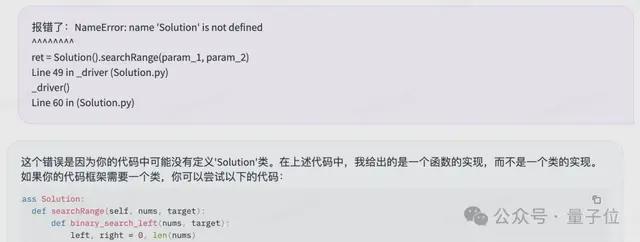
顺利通过测试。
全尺寸模型标配 GQA
这波实测,你给通义千问打几分?
值得关注的是,这次阿里官方的技术博客中,还透露出了不少Qwen 变强的技术细节。
首先,是GQA(Grouped Query Attention)的全面加持。
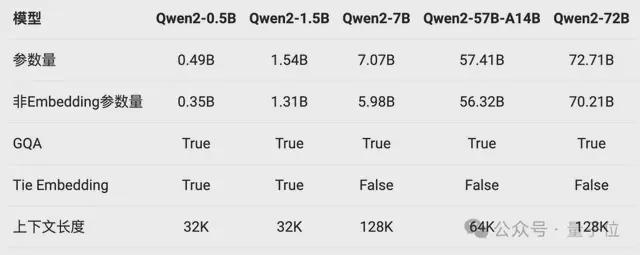
GQA,即分组查询注意力机制,主要思想将输入序列划分成若干个组,在组内和组间分别应用注意力机制,以更好地捕捉序列内的局部和全局依赖关系。
GQA 能够有效降低计算复杂度,同时很容易实现并行化从而提高计算效率。
在 Qwen1.5 系列中,只有 32B 和 110B 模型使用了 GQA。而 Qwen2 则全系列用上了这一注意力机制。也就是说,无论是高端玩家还是爱好者入门,这回都能在 Qwen2 各个尺寸模型中体验到 GQA 带来的推理加速和显存占用降低的优势。
另外,针对小模型(0.5B 和 1.5B),由于 embedding 参数量较大,研发团队使用了 tie embedding 的方法让输入和输出层共享参数,以增加非 embedding 参数的占比。
其次,在上下文长度方面,Qwen2 系列中所有 Instruct 模型,均在 32K 上下文长度上进行训练,并通过 YARN 或 Dual Chunk Attention 等技术扩展至更长的上下文长度。
其中,Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 支持 128K 上下文。72B 版本的最长上下文长度可以达到 131072 个 token。
Qwen2-57B-A14B-Instruct 能处理 64K 上下文,其余两个较小的模型(0.5B 和 1.5B)则支持 32K 的上下文长度。
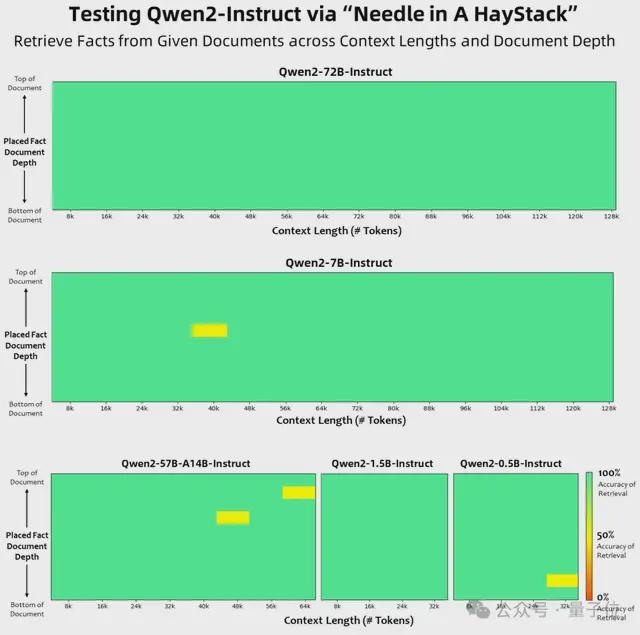
大海捞针的实验结果如下。可以看到,Qwen2-72B-Instruct 在处理 128K 上下文长度内的信息抽取任务时,表现称得上完美。
除此之外,在数据方面,Qwen2 继续探索 Scaling Law 的路线。
比如数学能力的提升,就是研究团队给模型喂了大规模高质量数学数据的结果。
在多语言能力方面,研究团队也针对性地在训练数据中增加了 27 种语言相关的高质量数据。

博客还透露,接下来,通义千问研究团队还将继续探索模型及数据的 Scaling Law,还会把 Qwen2 扩展为多模态模型。
重新认识中国开源大模型
更强的性能、更开放的态度,Qwen2 刚一发布,堪称好评如潮。
而在此前,生态方面,Qwen 系列下载量已突破 1600 万次。海内外开源社区也已经出现了超过 1500 款基于 Qwen 二次开发的模型和应用。
已经有开发者感受到了:在开源路线上,现在中国大模型正在成为引领者。

Qwen2 的最新成绩单,至少印证了两个事实。
其一,中国开源大模型,从性能到生态,都已具备跟美国最强开源大模型 Llama 3 全面对垒的硬实力。
其二,如图灵奖得主 Yann LeCun 所预言,开源大模型已经走在了超越闭源模型的道路上,拐点已现。
事实上,这也是包括阿里在内,开源大模型玩家的明牌——
大模型的持续优化和进步,一方面依赖于强大的 AI 研发能力、领先的基础设施能力,也就是人工智能和云的强强联合。
以阿里为例,作为中国云厂商份额第一,依托于强大的云计算能力,能为 AI 训练、AI 应用提供稳定高效的 AI 基础服务体系,同时在人工智能方面有长期的积累。
另一方面也需要来自外界的不断反馈和技术推动。
开源社区的技术反哺,从 Qwen2 上线第一天,GitHub 上的 Issues 数量就可见一斑。
在技术领域,开源就是我为人人、人人为我,是全球科技互联网繁荣发展至今最核心的精神要素。
不论任何一个时代,不管哪种新兴技术浪潮,没有程序员、工程师不以开源感到骄傲,甚至快乐。
阿里高级算法专家、开源负责人林俊旸,曾对外分享过通义千问进展飞快的“秘籍”:
快乐。
因为面向全球开发者服务,面向其他开发者交流,给别人带去实实在在的帮助,这样通义千问大模型的打造者们快乐又兴奋,关注着每一个开发者的反馈,激动于全新意想不到的落地应用。
这也是科技互联网世界曾经快速发展的核心原因,黄金时代,开源才是约定俗成的,不开源反而要遭受质疑。
然而时移世易,在大模型时代,由于研发成本、商业模式和竞争多方面的原因,闭源的光芒一度掩盖了开源,Close 成了宠儿。
所以 Meta 的 Llama 也好,阿里通义千问的 Qwen 也好,复兴传统,重新证明科技互联网领域不变的精神和内核。
这种精神和内核,在通义千问这里,也拥有不言自明的可持续飞轮。
阿里巴巴董事长蔡崇信已经对外分享了思考,在全球云计算和 AI 的第一梯队中,有领先的云业务又有自研大模型能力的,仅谷歌和阿里两家。其他有云服务的微软、亚马逊,都是合作接入大模型;其他自研大模型的 OpenAI、Meta,没有领先的云服务。
全球唯二,中国唯一。
而在开源生态的推动中,技术迭代会更快,云计算的服务延伸会越广,技术模型和商业模式,飞轮闭环,循环迭代,在固有基础设施的基础上垒起新的基础设施,形成稳固持续的竞争力。
但开源大模型,最大的价值和意义依然回归开发者,只有足够强大的开源大模型,AI for All、AI 无处不在才不会成为纸上空谈。
所以通义千问 Qwen2,此时此刻,登顶的是全球开源性能最高峰,引领的是开源对闭源的超越阶段,象征着中国大模型在新 AI 时代中的竞争力。
但更值得期待的价值是通过开源大模型,让天下没有难开发的 AI 应用、让天下没有难落地的 AI 方案。完整兑现 AI 价值,让新一轮 AI 复兴,持续繁荣,真正改变经济和社会。
开源超闭源!通义千问Qwen2发布即爆火,网友:GPT-4o危的更多相关文章
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- Docker与k8s的恩怨情仇(四)-云原生时代的闭源落幕
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 在本系列前几篇文章中,我们介绍了从Cloud Foundry到Docker等PaaS平台的发展迭代过程.今天 ...
- Linux开源系统对比Windows闭源系统的优势解析
当我们听到linux的时候是不是觉得高大上的感觉呢?在我刚上大学的时候,听着学长们给我讲他们的大学的学习经历,先学习C语言.单片机.然后做一些项目,现在正学习linux操作系统,当我听到linux操作 ...
- 凉凉了,Eureka 宣布闭源,Spring Cloud 何去何从?
今年 Dubbo 活了,并且被 Apache 收了.同时很不幸,Spring Cloud 下的 Netflix Eureka 组件项目居然宣布闭源了.. 已经从 Dubbo 迁移至 Spring Cl ...
- Eureka 2.0 闭源--选择Consul???
在上个月我们知道 Eureka 2.0 闭源了,但其实对国内的用户影响甚小,一方面国内大都使用的是 Eureka 1.X 系列,另一方面 Spring Cloud 支持很多服务发现的软件,Eureka ...
- Ubuntu 16.04安装GTX960闭源驱动
GTX960的闭源要Nvidia 346版才行,闭源驱动能很大提升显卡的性能,例如双显示输出等,缺点是不开源. 有以下方式来安装: 1.命令行: sudo add-apt-repository -y ...
- Eureka 2.0 闭源--选择Consul???[转]
原文链接: https://www.cnblogs.com/williamjie/p/9369800.html 在上个月我们知道 Eureka 2.0 闭源了,但其实对国内的用户影响甚小,一方面国内大 ...
- deepin20 安装英伟达闭源驱动
第一步.安装深度的"显卡驱动器" 在deepin v20 中默认没有显卡驱动管理器,需要命令行安装,命令如下(刚开始一直出错,当我第一次打开应用商店,就可以安装了,好神奇): su ...
- 【原】Android热更新开源项目Tinker源码解析系列之三:so热更新
本系列将从以下三个方面对Tinker进行源码解析: Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Android热更新开源项目Tinker源码解析系列之二:资源文件热更新 A ...
- 【原】Android热更新开源项目Tinker源码解析系列之一:Dex热更新
[原]Android热更新开源项目Tinker源码解析系列之一:Dex热更新 Tinker是微信的第一个开源项目,主要用于安卓应用bug的热修复和功能的迭代. Tinker github地址:http ...
随机推荐
- Python基础—初识函数(二)
1.给函数参数增加元信息 写好一个函数,然后想为这个函数的参数增加一些额外的信息,这样的话其他使用者就能清楚的知道这个函数应该怎么使用. 使用函数参数注解是一个很好的办法,它能提示程序员应该怎样正确使 ...
- Springboot笔记<1>版本控制器、场景启动器与自动配置原理
springboot版本控制器 SpringBoot应用的pom.xml中引入了一个父项目parent:spring-boot-starter-parent,spring-boot-starter-p ...
- 浅谈pytest+HttpRunner如何展开接口测试
数栈是云原生-站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变 ...
- hot100之二叉树下
二叉树的右视图(199) class Solution { List<Integer> res = new ArrayList<>(); public List<Inte ...
- 🔥《刚刚问世》系列初窥篇-Java+Playwright自动化测试-19- 操作鼠标悬停(详细教程)
1.简介 在实际工作中,我们往往会遇到有些测试场景或者事件,playwright根本就没有直接提供方法去操作,而且也不可能面面俱到地把各种测试场景都全面覆盖提供方法去操作,这个时候就需要我们去掌握一些 ...
- 7.Java SDK源码分析系列笔记-JDK1.8 HashMap
目录 1. 是什么 2. 如何使用 3. 原理分析 3.1. uml 3.2. 构造方法 3.3. put方法 3.3.1. 计算key的hash值 3.3.2. 第一次进来table肯定为空,那么扩 ...
- 云筑集采研发团队的Scrum敏捷实践总结
Edison作为团队内部敏捷教练,这是我正式辅导的第一个Scrum Master童鞋(花名:大师兄)的敏捷迭代实践总结,在互联网公司做敏捷转型,难而正确! Scrum 是用于开发.交付和持续支持复杂产 ...
- apche服务器下无后缀文件配置浏览器访问自动下载
1.在配置最新的IOS app 微信授权登录时 SDK时,碰到一个问题.服务器端需要配置IOS唤起微信APP授权的通用链接地址. 2.关于通用链接 3. 必须将ios的配置文件放入网址根目录下的app ...
- Xamarin.Andorid 调用相机拍照
https://www.jianshu.com/p/29b349ff7f1a 第一步:XML布局文件 <?xml version="1.0" encoding="u ...
- C# 通过 HttpClient 上传图片 POST
public string PostUploadImage(string uploadUrl, string imgPath, string fileparameter = "file&qu ...