halcon 深度学习教程(三) 目标检测之水果分类
原文作者:aircraft
原文链接:halcon 深度学习教程(三) 目标检测之水果分类 - aircraft - 博客园
深度学习教程目录如下,还在继续更新完善中
有兴趣可以多看其他的halcon教程
本篇主要讲一下halcon的目标检测案例,都是halcon22版本以后才可以用的哈,没有的话记得安装。在学习之前不要有什么心理负担,要知道halcon的封装算子都是做的非常好的,所以本篇也是写的非常的简单,你们肯定看一遍就会了。要对自己有信心。
虽然本文只讲了水果分类的案例,但是大家都是聪明人,把图片换一下不就是药片分类,球分类,或者行人与汽车自行车分类或者各种其他分类的目标检测了嘛!!!还有在工业里怎么用呢,以LED/半导体的晶圆片举例,不就是把一个个晶圆区域图先裁剪好,然后一个个去把图上的缺陷区域去标注出来吗???
(这里要注意了目标检测的想要好的效果,数据量还是需要比较多的,没有专门的标注训练员工还是不要这样玩哈,halcon的深度学习教程一里的分类倒是数据量会少一点点几百张图可能就有个相对的结果可以用用了)
示例程序如下图,参考博客:https://blog.csdn.net/qq_41373415/article/details/115906517?spm=1001.2014.3001.5502
demo案例代码的百度云下载链接(代码我做了详细处理,下了改一行你们自己路径的代码就可以直接跑噢):
链接:https://pan.baidu.com/s/1dHS_iObY8uHUIIu0czCdVw?pwd=sf7n
提取码:sf7n
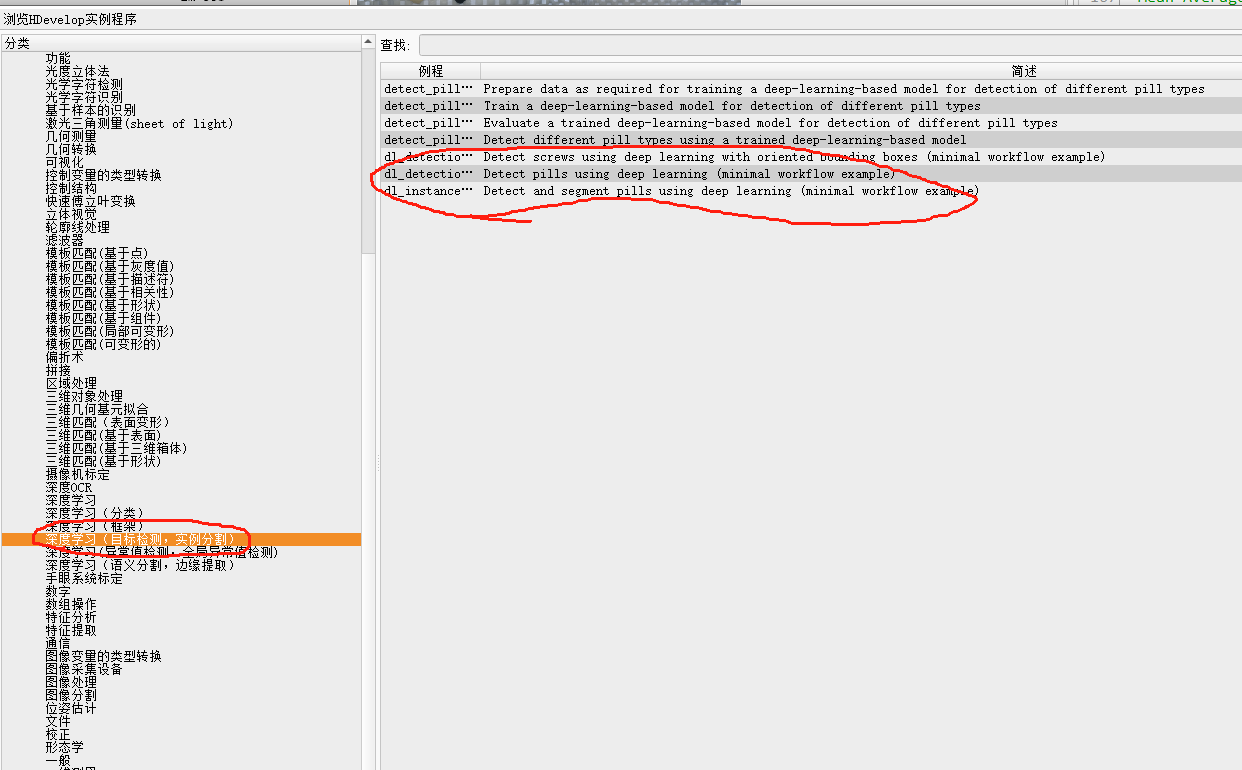
halcon深度学习目标检测的步骤总结一下就是 : 创建目标检测模型,相关数据和预处理,训练模型,评估模型,验证模型。
一.预备准备
首先就是要在补充点深度学习的参数知识(更多的你们再去百度一下哈,写不下了hhh):
一、核心评估指标
精确率(Precision)
- 公式:
TP / (TP + FP) - 解释:预测为正的样本中,有多少是真正的正样本
- 场景:在药品缺陷检测中,精确率高意味着系统标记的缺陷区域大部分真实存在缺陷(减少误报)
- 公式:
召回率(Recall)
- 公式:
TP / (TP + FN) - 解释:真正的正样本中,有多少被正确识别
- 场景:在安全检测中,召回率高意味着系统能捕捉到绝大多数潜在危险品(减少漏检)
- 公式:
F1 Score
- 公式:
2 * (Precision * Recall) / (Precision + Recall) - 作用:平衡精确率和召回率的综合指标,适用于类别不平衡的场景
- 公式:
mAP(mean Average Precision)
- 定义:多个IoU阈值下平均精度的均值(目标检测核心指标)
- 计算:对每个类别计算AP(Precision-Recall曲线下面积),再取平均
- 场景:评估模型在药品包装检测中,对不同大小、位置缺陷的综合识别能力
mAP(平均AP)这里单独拿出来讲一下
平均AP(mean Average Precision,mAP)详解
平均AP(mean Average Precision,简称mAP)是目标检测和图像分类任务中最核心的评估指标,用于衡量模型在不同类别上的综合检测能力。其核心思想是计算所有类别的平均精度(AP)后取均值,反映模型在“定位”和“分类”双重任务中的整体性能。
一、核心概念拆解
AP(Average Precision)单类别平均精度
- 定义:针对某一类别的检测结果,计算其在不同召回率(Recall)下的平均精度(Precision)。
- 计算步骤:
- 按置信度从高到低排序该类别的所有预测框。
- 计算每个预测框的Precision和Recall,绘制PR曲线(Precision-Recall Curve)。
- AP = PR曲线下的面积(AUC)。
mAP(mean Average Precision)多类别平均精度
- 定义:所有类别的AP值取平均。
- 公式:
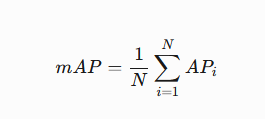
其中 N 为类别总数,APi 为第 i 类的AP值。
二、具体计算过程(以目标检测为例)
假设数据集中包含 3类物体:药片(Pill)、药盒(Box)、缺陷(Defect)。
| 类别 | AP值 |
|---|---|
| 药片 | 0.90 |
| 药盒 | 0.85 |
| 缺陷 | 0.75 |
则 mAP = (0.90 + 0.85 + 0.75) / 3 = 0.83
三、关键影响因素
IoU(Intersection over Union)阈值
- 定义:预测框与真实框的重叠面积占比,阈值越高要求越严格。
- 常见设定:
- mAP@0.5:IoU阈值为0.5(PASCAL VOC标准)。
- mAP@0.5:0.95:IoU从0.5到0.95,每隔0.05计算一次AP后取平均(COCO标准)。
置信度阈值(Confidence Threshold)
- 高于此阈值的预测框才会被保留,直接影响召回率和精确率。
数据分布
- 若某类别样本极少(如缺陷),其AP值可能偏低,导致整体mAP下降。
四、mAP在工业检测中的应用场景
模型选型
- 对比不同模型(如YOLOv5 vs. Faster R-CNN)的mAP值,选择最适合当前任务的架构。
调参依据
- 通过提升mAP优化模型:
* 调整锚框比例(aspect_ratios)适配小物体检测
set_dict_tuple (DLModelDetectionParam, 'aspect_ratios', [0.5, 1.0, 2.0])
* 增加数据增强提升小样本类别AP
set_preprocess_param (DLPreprocessParam, 'augmentation', 'rotation_30')
质量验收标准
- 设定mAP阈值作为模型上线的门槛(如mAP@0.5 ≥ 0.85)。
五、与Accuracy的区别
| 指标 | 适用场景 | 优缺点 |
|---|---|---|
| mAP | 目标检测 | 综合反映定位和分类能力,适合多类别 |
| Accuracy | 分类任务 | 无法处理定位问题,对类别不平衡敏感 |
六、实际案例:药品包装检测报告
| 缺陷类型 | AP@0.5 | AP@0.75 | 主要错误类型 |
|---|---|---|---|
| 印刷模糊 | 0.92 | 0.85 | 误检背景纹理为缺陷 |
| 包装破损 | 0.88 | 0.78 | 小尺寸破损漏检 |
| 密封不严 | 0.80 | 0.65 | 光照反光导致误判 |
- 全局mAP@0.5 = 0.87 → 模型达到上线标准
- 优化方向:针对密封不严类别增加侧面光照样本训练。
通过理解mAP,开发者可精准定位模型弱点(如特定类别AP低),针对性优化数据或模型结构,在工业检测场景中实现高效可靠的质量控制。
二、训练过程参数
学习率(Learning Rate)
- 作用:控制参数更新的步长
- 示例:
0.001(常用初始值),过高导致震荡,过低收敛慢 - 调整策略:学习率衰减(如每10个epoch减少50%)
批次大小(Batch Size)
- 影响:
- 小批量(如16):更频繁更新,适合小显存
- 大批量(如128):训练稳定,适合分布式训练
- 场景:在工业检测中,若图像分辨率高(如4096x4096),需减小batch size防止显存溢出
- 影响:
Epoch
- 定义:完整遍历一次训练集的迭代次数
- 选择原则:早停法(当验证集损失不再下降时停止)
三、模型结构相关
Anchor Boxes
- 作用:预设的边界框模板,用于生成候选区域
- 参数示例:
python
AspectRatios := [1.0, 0.5, 2.0] // 宽高比(正方形、高窄框、宽扁框)
NumSubscales := 3 // 缩放级别数- 场景:检测药片时,设置适合圆形物体的宽高比(如1:1)
IoU(Intersection over Union)
- 公式:两个框的交集面积 / 并集面积
- 用途:判断预测框与真实框的重合程度,阈值常设为0.5
NMS(非极大值抑制)
- 作用:去除冗余检测框,保留置信度最高的预测
- 参数:
NMS阈值(如0.3),高于此值的重叠框将被抑制
四、正则化与优化
Dropout
- 作用:随机丢弃神经元,防止过拟合
- 参数:
丢弃率(如0.5),训练时生效,推理时关闭
L2正则化
- 公式:损失函数中增加
λ * ||权重||² - 效果:限制权重过大,提升泛化能力
- 公式:损失函数中增加
优化器
- Adam:自适应学习率,适合大多数场景(默认参数β1=0.9, β2=0.999)
- SGD:需手动调学习率,配合动量(如0.9)可加速收敛
五、数据相关
数据增强(Data Augmentation)
- 方法:旋转(±15°)、缩放(0.8-1.2倍)、平移、颜色抖动
- 场景:在药品检测中,模拟不同光照条件下的包装缺陷
迁移学习(Transfer Learning)
- 策略:使用预训练模型(如ResNet)的权重初始化,仅微调最后几层
- 优势:在小样本(如1000张缺陷图)场景下快速收敛
六、理解精确率和召回率的意思
* 假设药片检测结果:
* TP(真正): 90(正确识别有缺陷的药片)
* FP(假正): 10(将正常药片误判为缺陷)
* FN(假负): 5(漏检的缺陷药片) 精确率 = 90 / (90+10) = 90%
召回率 = 90 / (90+5) = 94.7%
F1 = 2*(0.9 * 0.947)/(0.9+0.947) ≈ 92.3%
F1 Score 详细解释
1. 基本定义
F1 Score 是综合评估模型性能的核心指标,专门用于平衡精确率(Precision)和召回率(Recall)之间的矛盾。它通过两者的调和平均数,帮助判断模型在“不漏检”和“不误报”之间的综合表现。
2. 计算公式
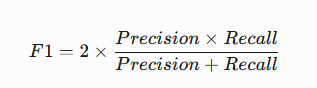
调和平均数特性:更注重两者中较低的值。
例如:若 Precision=0.9,Recall=0.1,F1≈0.18(接近较差值)
3. 为什么需要F1?
- 场景矛盾:实际需求:多数任务需平衡两者(如医疗诊断既不能漏掉患者,也不能误诊健康人)。
- 高精确率 = 严格模型(宁可漏检,也不错报)
- 高召回率 = 宽松模型(宁可错报,也不漏检)
- F1接近1(如0.95):模型在精确率和召回率间达到完美平衡。
- F1较低(如0.6):需检查是 Precision 还是 Recall 拖后腿:
- 若 Precision 低 → 模型误报多(优化分类阈值或减少FP)。
- 若 Recall 低 → 模型漏检多(调整Anchor尺寸或增强特征提取)。
4. 应用场景
- 类别不平衡任务:如缺陷检测(缺陷样本远少于正常样本)。
- 多类别比较:计算每个类别的F1后取平均(宏平均/Macro-F1)。
- Halcon中的使用:
调用evaluate_dl_model后,可通过输出的EvaluationResult字典查看各类别F1值。
5. 与准确率(Accuracy)的区别
- Accuracy = (TP+TN)/(TP+TN+FP+FN)F1:更适用于关注少数类(如缺陷)的场景。
- 问题:在数据不平衡时失效(如99%正常品+1%缺陷品,全预测正常Accuracy=99%但Recall=0)。
七、参数调优建议
- 高精确率低召回:模型保守,需降低分类阈值
- 低精确率高召回:模型激进,需提高阈值或增加FP惩罚
- 目标检测调参优先级:
- 先调Anchor比例(匹配物体形状)
- 再调学习率和数据增强策略
- 最后优化NMS和置信度阈值
掌握这些概念后,再结合Halcon的evaluate_dl_model输出结果,可快速定位模型问题并优化参数。
然后就是要知道我们的环境是halcon22版本以后的,还要下载一下halcon的深度学习标注训练工具(记得选中文语言的设置比较好看哦):Deep Learning tool
打开软件,我们直接选择对象检测(也就是目标检测的意思),里面的分类,OCR,实例分割都可以用起来,我其他深度学习教程里也是用这个工具测试训练评估查看的。
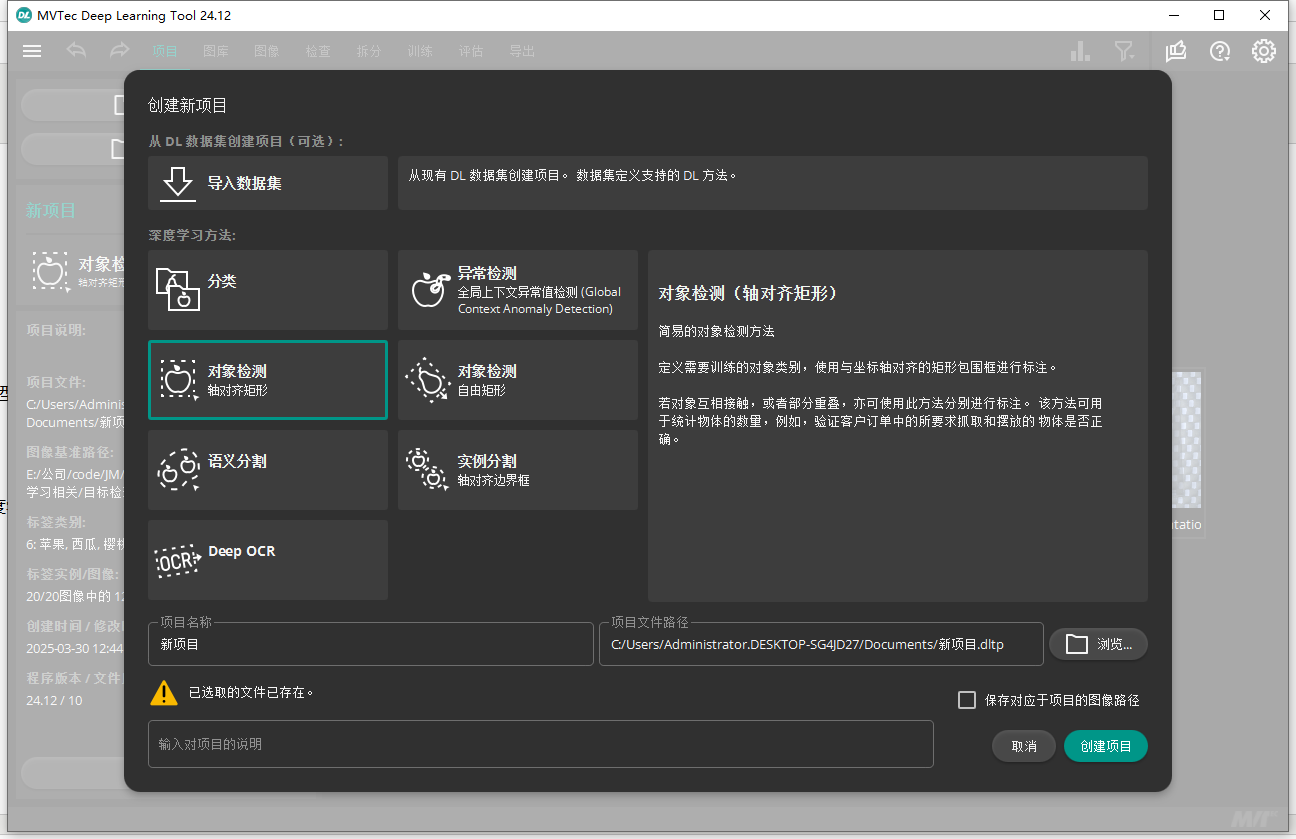
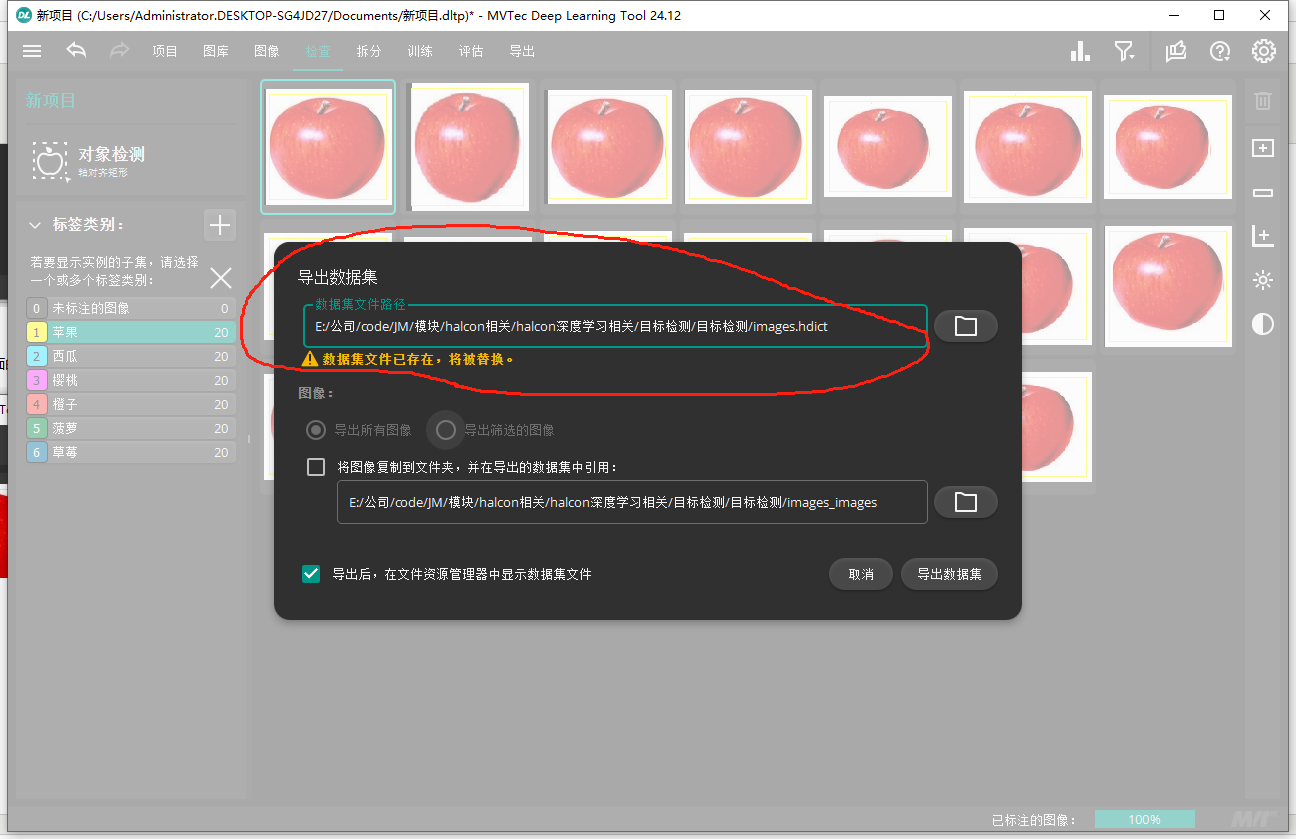
左上角按钮里倒入我项目里的数据集(或者直接导入images里的水果图像,然后一个个打上标签,在导出数据集,注意导出的数据集如果已经拆分,代码里就不要用拆分算子了):
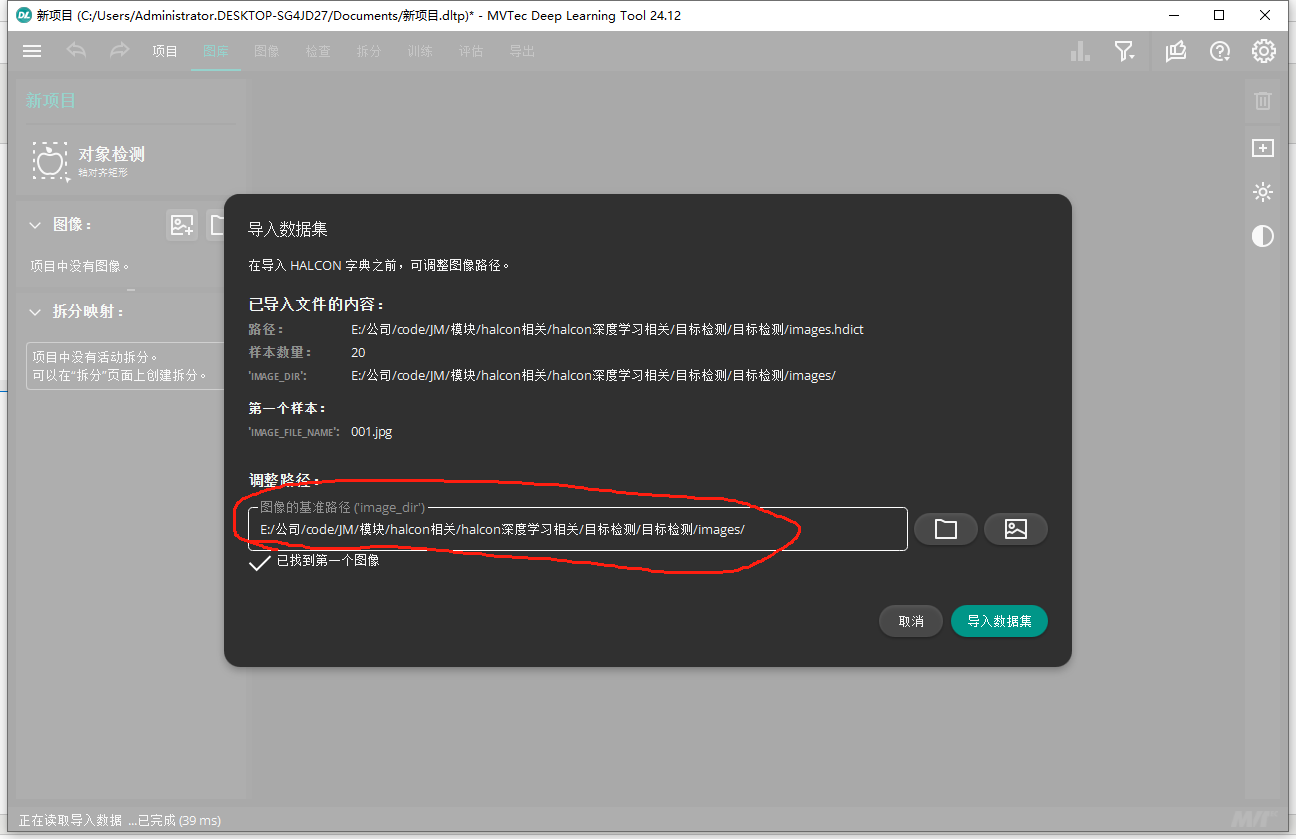
路径记得改自己目录的
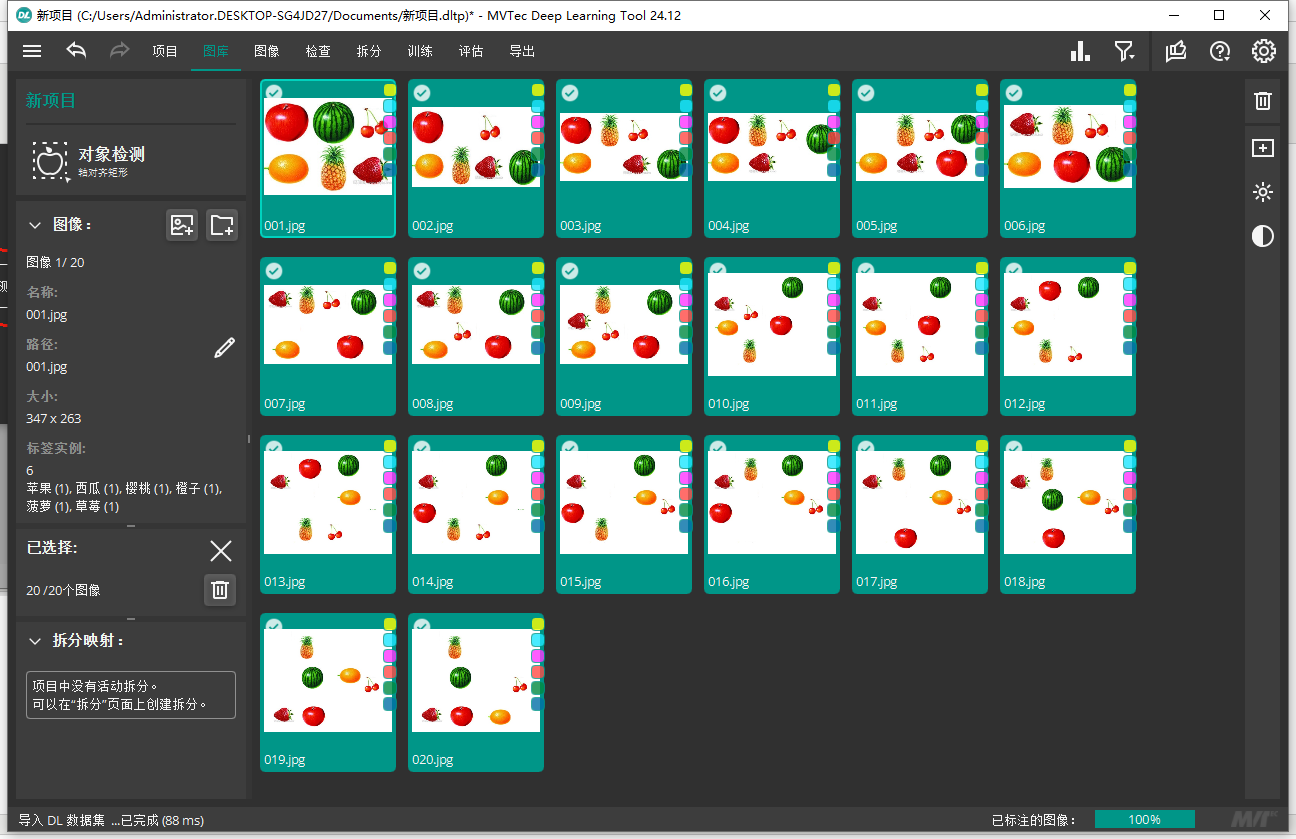
然后可以到图像那边去看看怎么标注的,就是新建几个标签,然后框选目标物体,打上标签就可以了
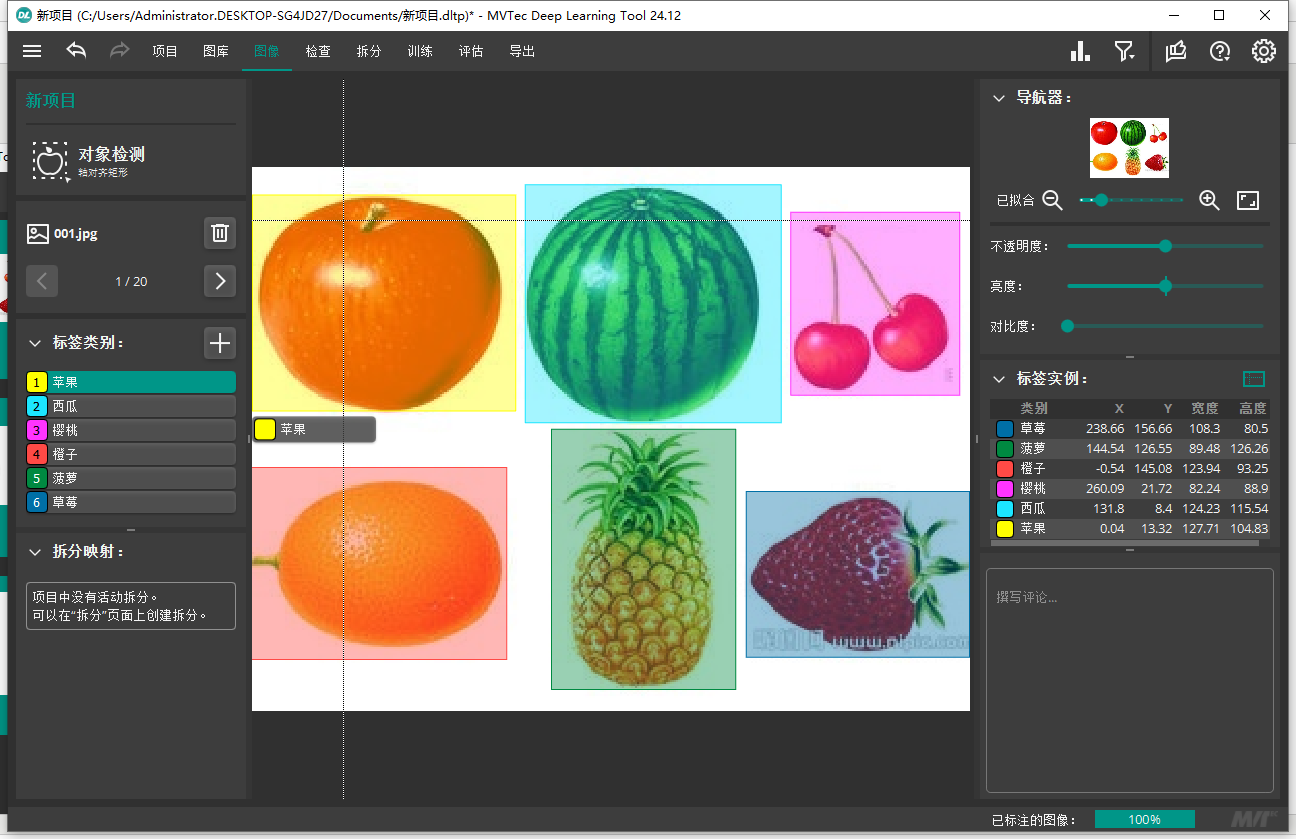
这里要注意的是,不要乱打标签,像这里给苹果打了三个矩形框的标签,一个是标准的只把苹果框选,留白的区域很少,一个框选很大,很多无关的区域,一个框选半个苹果。这样打标签你以为是增加了数据量,其实这样会让神经网络错误的学习到了其他数据,导致你的召回率降低。

然后到检查那边去检查一下标注
后面的拆分,训练,评估和导出模型可以自己玩一下(因为halcon代码里有后续的部分这里就不搞后面的),我都玩了好久各种参数乱改去测试结果的变化。
最后就是左上角导出数据集了,路径记得改自己的哈
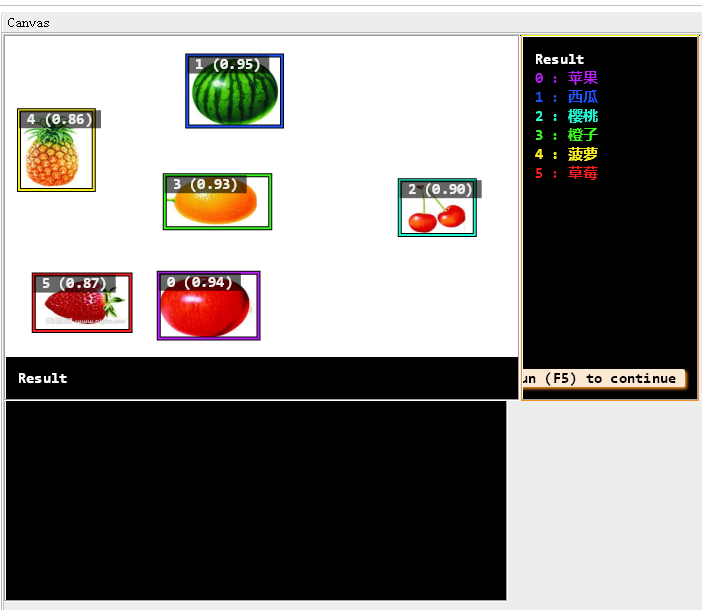
后面训练出来的模型去测试图片会给出每个对象的分数,我们自己用在自己的项目里就可以设置分数阈值比如大于0.8我就认为你预测的没有问题,分数多好还是要根据自己的模型的好坏来设置哈
二.相关算子学习
1.创建目标检测模型算子create_dl_model_detection( : : Backbone, NumClasses, DLModelDetectionParam : DLModelHandle)详解:
功能描述
create_dl_model_detection 用于在Halcon中创建一个基于深度学习的目标检测模型。该函数通过组合预训练的主干网络(Backbone)与自定义的检测头(Detection Head),构建一个完整的检测模型架构,适用于工业检测、物体识别等场景。
参数说明
| 参数名 | 类型 | 描述 | 示例值 |
|---|---|---|---|
| Backbone | 字符串 | 预训练主干模型文件路径(.hdl格式),提供基础特征提取能力 | 'pretrained_dl_classifier_compact.hdl' |
| NumClasses | 整型 | 待检测的物体类别数量(不包含背景类) | 6 |
| DLModelDetectionParam | 字典 | 包含模型配置参数的字典,定义输入尺寸、锚框参数等 | 见下方参数字典配置 |
| DLModelHandle | 模型句柄 | 输出参数,生成的检测模型句柄,用于后续训练、推理等操作 | - |
参数字典(DLModelDetectionParam)配置项
| 键名 | 类型 | 必选 | 描述 | 示例值 | 默认值(若有) |
|---|---|---|---|---|---|
| image_width | 整型 | 是 | 输入图像的宽度(像素),需与预处理尺寸一致 | 512 | 无 |
| image_height | 整型 | 是 | 输入图像的高度(像素) | 320 | 无 |
| image_num_channels | 整型 | 是 | 输入图像的通道数(3表示RGB,1表示灰度) | 3 | 无 |
| min_level | 整型 | 是 | 特征金字塔网络(FPN)中的最小层级,用于检测大物体(值越大特征图越小) | 2 | 无 |
| max_level | 整型 | 是 | 特征金字塔网络中的最大层级,用于检测小物体 | 4 | 无 |
| num_subscales | 整型 | 是 | 每个特征层级上的锚框(Anchor)缩放级别数 | 3 | 无 |
| aspect_ratios | 浮点数组 | 是 | 锚框的宽高比配置(如[1.0, 0.5, 2.0]表示1:1、1:2、2:1三种比例) | [1.0, 0.5, 2.0] | 无 |
| capacity | 字符串 | 否 | 模型容量级别('light'、'medium'、'high'),控制网络宽度/深度,影响速度与精度 | 'medium' |
使用示例
* 步骤1:定义模型参数
Backbone := 'pretrained_dl_classifier_compact.hdl' // 预训练主干模型
NumClasses := 6 // 检测6类物体 * 步骤2:创建参数字典
create_dict (DLModelDetectionParam)
set_dict_tuple (DLModelDetectionParam, 'image_width', 512)
set_dict_tuple (DLModelDetectionParam, 'image_height', 320)
set_dict_tuple (DLModelDetectionParam, 'image_num_channels', 3)
set_dict_tuple (DLModelDetectionParam, 'min_level', 2)
set_dict_tuple (DLModelDetectionParam, 'max_level', 4)
set_dict_tuple (DLModelDetectionParam, 'num_subscales', 3)
set_dict_tuple (DLModelDetectionParam, 'aspect_ratios', [1.0,0.5,2.0])
set_dict_tuple (DLModelDetectionParam, 'capacity', 'medium') * 步骤3:创建检测模型
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
关键概念解析
主干网络(Backbone)
- 作用:提取图像特征,通常为预训练的卷积神经网络(如ResNet、MobileNet)。
- 选择建议:
- 高精度场景 → ResNet50
- 实时检测 → MobileNetV3
特征金字塔(FPN)
- min_level/max_level:
- 层级越低(如2),特征图越大,适合检测大物体(如药盒包装)。
- 层级越高(如5),特征图越小,适合检测小物体(如药片表面划痕)。
- 示例配置:
min_level=2,max_level=4表示使用第2、3、4层特征图。
- min_level/max_level:
锚框(Anchor Boxes)
- num_subscales:每个层级上的缩放系数数量(如3种尺寸)。
- aspect_ratios:锚框形状比例,需根据目标物体调整。
- 计算示例:
若某特征图位置生成3种缩放尺寸 × 3种宽高比 → 共9个锚框。
常见问题与解决方案
错误:Invalid backbone model
- 原因:
Backbone文件路径错误或格式不支持。 - 解决:
- 检查文件路径是否存在,扩展名是否为
.hdl。 - 使用Halcon预训练模型或官方支持的转换工具生成模型。
- 检查文件路径是否存在,扩展名是否为
- 原因:
训练时报错维度不匹配
- 可能原因:
NumClasses与实际标注类别数不一致。- 输入图像尺寸与
image_width/image_height不符。
- 验证步骤:
- 检查数据集标注文件中的类别ID范围。
- 确保预处理后的图像尺寸与模型参数一致。
- 可能原因:
检测小物体效果差
- 优化方向:
- 提高
max_level(如从4→5)以利用更高层特征。 - 增加小尺寸锚框的比例(调整
aspect_ratios和num_subscales)。
- 提高
- 优化方向:
高级配置建议
- 多尺度训练:在参数字典中添加
multiscale_training: 'true',增强模型对不同尺寸物体的适应性。 - 自定义锚框:通过
get_anchor_dims分析训练集标注,生成适配数据集的锚框参数。 - 混合精度训练:设置
set_dl_model_param (DLModelHandle, 'mixed_precision', 'true')加速训练(需GPU支持)。
通过合理配置create_dl_model_detection参数,可快速构建适应工业检测需求的高效目标检测模型。
2.设置模型参数算子set_dl_model_param( : : DLModelHandle, GenParamName, GenParamValue : )详解:
功能描述
set_dl_model_param 用于动态配置已创建的深度学习模型的参数。通过该函数,可以在模型训练或推理前调整超参数、优化策略、数据预处理设置等,是灵活控制模型行为的核心接口。
函数原型
set_dl_model_param(
DLModelHandle, // 输入:模型句柄(由 create_dl_model_* 系列函数生成)
GenParamName, // 输入:待设置的参数名(字符串或数组)
GenParamValue // 输入:参数值(类型取决于参数名)
)
参数详解(按应用场景分类)
一、训练过程控制参数
| 参数名 | 数据类型 | 作用 | 示例值 | 注意事项 |
|---|---|---|---|---|
| **'batch_size'** | 整型 | 设置训练/推理时的批大小 | 16 | 需适配GPU显存(过大导致OOM) |
| **'learning_rate'** | 浮点型 | 初始学习率 | 0.001 | 常配合学习率调度策略使用 |
| **'momentum'** | 浮点型 | SGD优化器的动量参数(加速收敛) | 0.9 | 仅对SGD生效 |
| **'weight_prior'** | 浮点型 | 分类损失权重(用于类别不平衡场景) | [1.0, 2.0, 2.0] | 数组长度需等于类别数 |
| **'epochs'** | 整型 | 最大训练轮次 | 50 | 需配合早停法使用 |
二、模型结构与优化
| 参数名 | 数据类型 | 作用 | 示例值 | 注意事项 |
|---|---|---|---|---|
| **'optimizer'** | 字符串 | 优化器类型('adam'、'sgd'、'rmsprop') | 'adam' | 不同优化器需配不同参数 |
| **'dropout_rate'** | 浮点型 | 随机丢弃神经元的比例(防止过拟合) | 0.5 | 通常在全连接层生效 |
| **'l2_regularization'** | 浮点型 | L2正则化系数(控制权重复杂度) | 0.0001 | 避免设置过大导致欠拟合 |
三、推理与后处理
| 参数名 | 数据类型 | 作用 | 示例值 | 注意事项 |
|---|---|---|---|---|
| **'nms_threshold'** | 浮点型 | 非极大值抑制阈值(过滤重叠框) | 0.3 | 值越小保留框越少 |
| **'confidence_threshold'** | 浮点型 | 检测框置信度阈值(过滤低置信度预测) | 0.5 | 平衡召回率与精确率 |
| **'max_num_detections'** | 整型 | 单图最大检测框数量(防止过多误检) | 100 | 按实际场景需求调整 |
四、硬件与性能
| 参数名 | 数据类型 | 作用 | 示例值 | 注意事项 |
|---|---|---|---|---|
| **'runtime'** | 字符串 | 推理设备('cpu'、'gpu') | 'gpu' | 需安装对应计算库(如CUDA) |
| **'mixed_precision'** | 布尔型 | 启用混合精度训练(节省显存,加速计算) | 'true' | 需GPU支持半精度运算 |
使用示例
场景:药品包装缺陷检测模型配置
* 创建模型后设置关键参数
set_dl_model_param (DLModelHandle, 'batch_size', 8) // 小批量适应高分辨率图像
set_dl_model_param (DLModelHandle, 'learning_rate', 0.0005) // 小学习率精细调优
set_dl_model_param (DLModelHandle, 'nms_threshold', 0.25) // 严格过滤重叠缺陷框
set_dl_model_param (DLModelHandle, 'confidence_threshold', 0.6) // 减少误报 * 设置复合参数(数组传参)
set_dl_model_param (DLModelHandle, ['optimizer','momentum'], ['sgd', 0.9]) * 启用混合精度训练(需GPU支持)
set_dl_model_param (DLModelHandle, 'mixed_precision', 'true')
常见问题与解决方案
1. 参数设置无效
- 现象:修改参数后模型行为未变化
- 排查:
- 检查参数名拼写(区分大小写,如
'batch_size'vs'BatchSize')。 - 确认参数是否在模型当前阶段生效(例如某些参数仅在训练时生效)。
- 检查参数名拼写(区分大小写,如
2. GPU显存不足(OOM)
- 场景:设置
batch_size=32时报错 - 优化:
- 逐步减小
batch_size(如32→16→8)。 - 启用混合精度:
set_dl_model_param (..., 'mixed_precision', 'true')。 - 减少输入分辨率(需与
create_dl_model_detection中的image_width/height一致)。
- 逐步减小
3. 类别不平衡导致训练偏差
- 现象:多数类(如正常品)检测准确率高,少数类(缺陷)召回率低
- 解决:
* 设置类别权重(假设缺陷类为第2类,权重加倍)
set_dl_model_param (DLModelHandle, 'weight_prior', [1.0, 2.0])
最佳实践建议
分阶段调参
- 初期:使用较大学习率(如0.01)快速收敛。
- 中期:每隔5个epoch衰减学习率(如
set_dl_model_param (..., 'learning_rate', 0.001 * 0.5))。 - 后期:微调
confidence_threshold和nms_threshold优化部署效果。
参数依赖关系
- 当调整
image_width/height时,需重新生成锚框参数(通过create_dl_preprocess_param_from_model)。 - 修改
optimizer后,需检查关联参数(如momentum对SGD有效,但对Adam无效)。
- 当调整
版本兼容性
- Halcon 20.11+ 支持
mixed_precision参数。 - 使用
get_dl_model_param查询当前版本支持的参数列表:
- Halcon 20.11+ 支持
get_dl_model_param (DLModelHandle, 'all', GenParamNames)
通过合理运用set_dl_model_param,开发者可精准控制模型行为,在工业检测等高要求场景中实现精度与效率的最佳平衡。
3.训练目标检测模型算子train_dl_model( : : DLDataset, DLModelHandle, TrainParam, StartEpoch : TrainResults, TrainInfos, EvaluationInfos)详解:
功能描述
train_dl_model 是Halcon中用于执行深度学习模型训练的核心函数。它通过输入数据集、模型句柄及训练参数,启动训练流程,并输出训练结果、过程指标及评估信息,广泛应用于工业检测、目标识别等场景。
函数原型
train_dl_model(
DLDataset, // 输入:预处理后的数据集(包含训练/验证/测试集划分)
DLModelHandle, // 输入:已配置的模型句柄(通过create_dl_model_*创建)
TrainParam, // 输入:训练参数字典(定义训练轮次、验证频率等)
StartEpoch, // 输入:起始训练轮次(用于继续训练,首次训练设为0)
TrainResults, // 输出:训练结果状态(成功/失败)
TrainInfos, // 输出:训练过程信息(损失、准确率等)
EvaluationInfos // 输出:验证集评估结果(精确率、召回率等)
)
参数详解
一、输入参数
| 参数名 | 类型 | 描述 | 示例值/说明 |
|---|---|---|---|
| DLDataset | 字典 | 包含预处理后的数据集,需通过split_dl_dataset划分训练/验证/测试集 |
由preprocess_dl_dataset生成 |
| DLModelHandle | 句柄 | 已配置参数的模型句柄(需提前设置batch_size、learning_rate等) |
- |
| TrainParam | 字典 | 训练控制参数,需通过create_dl_train_param生成 |
见下方TrainParam配置 |
| StartEpoch | 整型 | 起始训练轮次(从0开始,用于断点续训) | 0(从头训练) |
二、输出参数
| 参数名 | 类型 | 描述 |
|---|---|---|
| TrainResults | 元组 | 训练状态(如 'success' 或错误信息) |
| TrainInfos | 字典 | 每个epoch的训练指标(损失、学习率、耗时等) |
| EvaluationInfos | 字典 | 验证集评估结果(精确率、召回率、mAP等) |
TrainParam 参数字典配置
通过 create_dl_train_param 生成参数字典,关键参数如下:
| 参数名 | 类型 | 描述 | 示例值 | 默认值 |
|---|---|---|---|---|
| num_epochs | 整型 | 总训练轮次(完整遍历训练集的次数) | 50 | - |
| evaluation_interval | 整型 | 每隔多少epoch执行一次验证集评估 | 1 | 1 |
| display | 布尔 | 是否显示训练进度条(需Halcon窗口支持) | 'true' | 'true' |
| seed_rand | 整型 | 随机种子(确保实验可复现) | 42 | - |
| save_best_model | 字符串 | 保存最佳模型的方式('none'、'last'、'best') | 'best' | 'none' |
使用示例
场景:药品包装缺陷检测模型训练
* 步骤1:创建训练参数字典
create_dl_train_param (DLModelHandle, 30, 1, 'true', 42, [], [], TrainParam)
* 参数说明:
* - 30: 训练30个epoch
* - 1: 每个epoch后验证一次
* - 'true': 显示进度条
* - 42: 固定随机种子 * 步骤2:启动训练
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos) * 步骤3:解析输出
* 检查训练状态
if (TrainResults == 'success')
* 提取最终epoch的损失值
get_dict_tuple (TrainInfos, 'epoch_loss', EpochLoss)
* 获取最佳模型在验证集的mAP
get_dict_tuple (EvaluationInfos, 'mean_ap', MeanAP)
* 输出结果
dev_inspect_ctrl (WindowHandle)
dev_disp_text ('训练成功!最终mAP: ' + MeanAP, 'window', 'top', 'left', 'black', [], [])
endif
关键输出解析(以药品检测为例)
1. TrainInfos 内容
{
'epoch': [1, 2, ..., 30], // 训练轮次
'loss': [0.85, 0.62, ..., 0.12], // 训练集损失
'learning_rate': [0.001, 0.001, ..., 0.0001], // 动态学习率
'time': [120, 118, ..., 115] // 每轮耗时(秒)
}
2. EvaluationInfos 内容
{
'precision': [0.72, 0.81, ..., 0.95], // 各类别平均精确率
'recall': [0.65, 0.78, ..., 0.93], // 各类别平均召回率
'mean_ap': 0.89, // 验证集mAP(主要评估指标)
'f1_score': [0.68, 0.79, ..., 0.94] // 各类别F1值
}
常见问题与解决方案
1. 训练损失不下降
- 现象:前5个epoch损失值波动或持平
- 解决:
* 调整学习率(初始值可能过高)
set_dl_model_param (DLModelHandle, 'learning_rate', 0.0001)
* 检查数据预处理(如标注错误导致模型无法学习)
2. 验证集mAP低于训练集
- 现象:训练集mAP=0.95,验证集mAP=0.70
- 原因:模型过拟合
- 优化:
* 增加正则化
set_dl_model_param (DLModelHandle, 'l2_regularization', 0.0005)
* 启用数据增强
set_preprocess_param (DLPreprocessParam, 'augmentation', 'rotation_15')
3. 训练中途中断
- 续训方法:
* 假设上次训练到第10个epoch
StartEpoch := 10
* 加载已保存的模型
read_dl_model ('model_epoch_10.hdl', DLModelHandle)
* 继续训练剩余20个epoch
create_dl_train_param (..., 30, ..., TrainParam) // total epochs=30
train_dl_model (..., StartEpoch, ...)
性能优化建议
分布式训练:
在Halcon中通过set_dl_model_param (DLModelHandle, 'parallelize', 'data')启用数据并行,加速大规模数据集训练。自动早停:
监控验证集mAP,若连续N个epoch未提升则终止训练:
* 自定义回调函数(伪代码)
if (EvaluationInfos.mean_ap 未提升 in 5 epochs)
stop_training = true
混合精度训练:
set_dl_model_param (DLModelHandle, 'mixed_precision', 'true') // 减少显存占用
4.评估模型算子evaluate_dl_model( : : DLDataset, DLModelHandle, SampleSelectMethod, SampleSelectValues, GenParam : EvaluationResult, EvalParams)详解:
功能描述
evaluate_dl_model 用于对训练好的深度学习模型进行性能评估,生成精确率、召回率、mAP(目标检测核心指标)等关键指标。该函数是验证模型在工业检测场景中实际表现的核心工具。
函数原型
evaluate_dl_model(
DLDataset, // 输入:预处理后的数据集(需包含测试集)
DLModelHandle, // 输入:已训练的模型句柄
SampleSelectMethod, // 输入:样本选择方法(如'split'按数据集划分)
SampleSelectValues, // 输入:选择方法对应的值(如'test'表示测试集)
GenParam, // 输入:评估控制参数(显示进度、详细输出等)
EvaluationResult, // 输出:评估结果(字典形式,含mAP等指标)
EvalParams // 输出:实际使用的评估参数记录
)
参数详解
一、输入参数
| 参数名 | 类型 | 描述 | 示例值/说明 |
|---|---|---|---|
| DLDataset | 字典 | 必须包含测试集样本(通过split_dl_dataset划分) |
由preprocess_dl_dataset生成 |
| DLModelHandle | 句柄 | 完成训练的模型句柄(建议加载model_best.hdl) |
- |
| SampleSelectMethod | 字符串 | 样本选择方式: • 'split':按数据集划分• 'num_samples':随机抽取N个样本 |
'split' |
| SampleSelectValues | 字符串/数组 | 与选择方法对应的值: • 'split' → 'test'• 'num_samples' → [100] |
'test' |
| GenParam | 字典 | 控制评估过程的详细行为 | 见下方GenParam配置 |
二、输出参数
| 参数名 | 类型 | 描述 |
|---|---|---|
| EvaluationResult | 字典 | 评估指标结果(包含各类别及全局的精度、召回率、mAP等) |
| EvalParams | 字典 | 实际生效的评估参数记录(用于复现评估条件) |
GenParam 配置(关键参数)
| 参数名 | 类型 | 作用 | 示例值 | 默认值 |
|---|---|---|---|---|
| detailed_evaluation | 布尔 | 是否输出各类别详细指标(True时显示每个类别的AP值) | 'true' | 'false' |
| show_progress | 布尔 | 显示评估进度条(需Halcon窗口支持) | 'true' | 'true' |
| batch_size | 整型 | 评估时的批次大小(影响显存占用与速度) | 8 | 与训练相同 |
| confidence_threshold | 浮点型 | 过滤低置信度检测框的阈值(影响召回率) | 0.3 | 0.5 |
使用示例
场景:药品缺陷检测模型评估
* 步骤1:配置评估参数
create_dict (GenParam)
set_dict_tuple (GenParam, 'detailed_evaluation', 'true') // 输出详细类别指标
set_dict_tuple (GenParam, 'show_progress', 'true') // 显示进度条
set_dict_tuple (GenParam, 'confidence_threshold', 0.4) // 降低阈值提高召回率 * 步骤2:执行评估(仅测试集)
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParam, EvaluationResult, EvalParams) * 步骤3:解析结果
get_dict_tuple (EvaluationResult, 'mean_ap', mAP) // 获取全局mAP
get_dict_tuple (EvaluationResult, 'precision', ClassPrecision) // 各类别精确率
输出解析(EvaluationResult 关键字段)
1. 全局指标
| 字段名 | 类型 | 描述 | 示例值 |
|---|---|---|---|
| mean_ap | 浮点型 | 平均精度(mAP,IoU阈值通常为0.5:0.95) | 0.85 |
| precision | 浮点型 | 整体精确率 | 0.92 |
| recall | 浮点型 | 整体召回率 | 0.88 |
2. 类别级指标(当detailed_evaluation=true时)
| 字段名 | 类型 | 描述 | 示例值 |
|---|---|---|---|
| class_ap | 浮点数组 | 每个类别的AP值 | [0.90, 0.80, ...] |
| class_precision | 浮点数组 | 各类别精确率 | [0.95, 0.85, ...] |
| class_recall | 浮点数组 | 各类别召回率 | [0.89, 0.83, ...] |
常见问题与解决方案
1. 评估耗时过长
- 原因:测试集过大或
batch_size过小 - 优化:
* 增大批次大小(需确保不超出GPU显存)
set_dict_tuple (GenParam, 'batch_size', 16)
* 关闭详细输出
set_dict_tuple (GenParam, 'detailed_evaluation', 'false')
2. mAP值异常低
- 排查步骤:
- 检查
confidence_threshold是否过高(漏检真实缺陷):
- 检查
set_dict_tuple (GenParam, 'confidence_threshold', 0.3)
- 验证标注文件(测试集标注错误会导致评估失真)
- 检查模型是否在测试集上过拟合(对比训练集mAP)
3. 类别间性能差异大
- 现象:A类AP=0.95,B类AP=0.50
- 解决:
* 针对弱类别(B类)增强数据
* 调整损失函数权重:
set_dl_model_param (DLModelHandle, 'weight_prior', [1.0, 2.0]) // B类权重加倍
高级应用技巧
多阈值评估
通过修改IoU阈值评估模型在不同严格度下的表现:
set_dict_tuple (GenParam, 'iou_threshold', [0.5, 0.75]) // 同时评估IoU@0.5和IoU@0.75
可视化错误样本
结合dev_display_dl_data显示假阴性(FN)和假阳性(FP)样本:
set_dict_tuple (GenParam, 'save_fp_samples', 'true') // 保存误检样本
set_dict_tuple (GenParam, 'save_fn_samples', 'true') // 保存漏检样本
跨模型对比
对多个模型(如v1.0和v2.0)执行相同评估,生成对比报告:
* 评估模型A
evaluate_dl_model (..., DLModelHandle_A, ..., EvalResult_A)
* 评估模型B
evaluate_dl_model (..., DLModelHandle_B, ..., EvalResult_B)
* 对比mAP
dev_display_comparison (EvalResult_A.mean_ap, EvalResult_B.mean_ap)
5.推理模型结果算子apply_dl_model( : : DLModelHandle, DLSampleBatch, Outputs : DLResultBatch)详解:
功能描述
apply_dl_model 是Halcon中用于执行深度学习模型推理的核心函数,可将训练好的模型应用于新的输入数据(图像或样本批次),生成预测结果(如目标检测框、分类标签等)。该函数广泛应用于工业检测中的实时推理场景。
函数原型
apply_dl_model(
DLModelHandle, // 输入:已加载的模型句柄
DLSampleBatch, // 输入:预处理后的输入数据(单个样本或批次)
Outputs, // 输入:指定输出类型(如目标检测的'bbox_results')
DLResultBatch // 输出:包含预测结果的字典或字典数组
)
参数详解
一、输入参数
| 参数名 | 类型 | 描述 | 示例值/说明 |
|---|---|---|---|
| DLModelHandle | 模型句柄 | 通过read_dl_model加载的已训练模型 |
- |
| DLSampleBatch | 字典/数组 | 输入数据,需包含预处理后的图像和元数据(通过preprocess_dl_samples生成) |
单样本:字典 批次:字典数组 |
| Outputs | 字符串/数组 | 指定输出类型,与模型类型相关: • 目标检测 → 'bbox_results' • 分类 → 'class_ids' |
['bbox_results'] |
二、输出参数
| 参数名 | 类型 | 描述 |
|---|---|---|
| DLResultBatch | 字典/数组 | 预测结果,结构与DLSampleBatch对应:• 单样本输入 → 字典 • 批次输入 → 字典数组 |
输出解析(以目标检测为例)
输出字典包含以下关键字段(具体字段根据模型类型变化):
| 字段名 | 类型 | 描述 |
|---|---|---|
| bbox_result | 字典数组 | 检测框信息(每个检测框为一个字典) |
| class_id | 整型数组 | 检测到的类别ID(与训练时的class_ids对应) |
| confidence | 浮点数组 | 检测置信度(范围0~1,值越高表示预测越可靠) |
| bbox | 浮点数组 | 检测框坐标(格式取决于参数设置,通常为[x1,y1,x2,y2]或[x,y,w,h]) |
使用示例
场景:药品包装缺陷单张图像检测
* 步骤1:加载模型
read_dl_model ('model_best.hdl', DLModelHandle) * 步骤2:读取并预处理图像
read_image (Image, 'defect_pill.jpg')
gen_dl_samples_from_images (Image, DLSample) // 生成输入样本
preprocess_dl_samples (DLSample, DLPreprocessParam) // 预处理(尺寸归一化等) * 步骤3:执行推理
apply_dl_model (DLModelHandle, DLSample, 'bbox_results', DLResult) * 步骤4:解析结果
get_dict_tuple (DLResult, 'bbox_result', BboxResults)
foreach Bbox in BboxResults
get_dict_tuple (Bbox, 'class_id', ClassID) // 获取类别
get_dict_tuple (Bbox, 'confidence', Confidence) // 置信度
get_dict_tuple (Bbox, 'bbox', [X1,Y1,X2,Y2]) // 检测框坐标
* 可视化
dev_display_box (X1, Y1, X2, Y2, 'red')
endforeach
高级用法
1. 批量推理优化
* 读取多张图像并预处理
list_image_files (ImageDir, 'default', [], ImageFiles)
gen_dl_samples_from_images (ImageFiles, DLSamples)
preprocess_dl_samples (DLSamples, DLPreprocessParam) * 批量推理(提升GPU利用率)
apply_dl_model (DLModelHandle, DLSamples, 'bbox_results', DLResults) * 遍历结果
for Index := 0 to |DLResults|-1 by 1
get_dict_tuple (DLResults[Index], 'bbox_result', BboxResults)
* 关联原始文件名
get_dict_tuple (DLSamples[Index], 'image_id', ImageID)
endforeach
2. 多输出模型
若模型支持同时输出检测框和分割掩膜:
apply_dl_model (DLModelHandle, DLSample, ['bbox_results','segmentation'], DLResult)
* 解析分割结果
get_dict_tuple (DLResult, 'segmentation', SegmentationMask)
dev_display_mask (SegmentationMask)
常见问题与解决方案
1. 推理速度慢
- 优化策略:
- 增加
batch_size(需权衡显存占用)set_dl_model_param (DLModelHandle, 'batch_size', 8) // 批次推理
启用TensorRT加速(需转换模型)
- 增加
set_dl_model_param (DLModelHandle, 'runtime', 'tensorrt')
2. 检测框坐标错误
- 原因:预处理/后处理的坐标格式不一致
- 验证步骤:
- 确认预处理是否包含归一化(如除以图像尺寸)
- 检查模型输出格式(
set_dl_model_param (..., 'bbox_format', 'x1y1x2y2'))
3. 内存不足(OOM)
- 现象:大尺寸图像导致显存溢出
- 解决:
- 减小
batch_size - 分割图像为小块处理
- 减小
* 将4096x4096图像分割为512x512网格
partition_rectangle (Image, 512, 512, PartitionedImages)
foreach Tile in PartitionedImages
gen_dl_samples_from_images (Tile, DLSample)
apply_dl_model (...)
endfor
关键注意事项
- 预处理一致性:确保推理时的预处理操作(尺寸、归一化)与训练完全一致。
- 输出映射:模型输出的
class_id需与训练时的类别标签匹配(通过get_dict_tuple (DLDataset, 'class_ids', ClassIDs)获取)。 - 结果过滤:根据
confidence阈值过滤低置信度检测框,平衡误报和漏检:
* 过滤置信度低于0.5的结果
filter_dl_results (DLResult, 'confidence', 0.5, FilteredResult)
三.实例代码讲解
我将代码分为了五个步骤方便大家的理解: 创建目标检测模型,相关数据和预处理,训练模型,评估模型,验证模型。
1. 创建目标检测模型
* 关闭图形更新提升性能
dev_update_off () * ##############################################################################
* ### 1. 创建目标检测模型 ###
* ############################################################################## *** 模型基础参数配置 ***
*必须的参数
Backbone := 'pretrained_dl_classifier_compact.hdl' // 预训练模型文件路径
NumClasses := 6 // 要检测的物体类别数量 *图像规格参数
ImageWidth := 512 // 模型输入宽度(需与预处理一致)
ImageHeight := 320 // 模型输入高度
ImageNumChannels := 3 // RGB三通道图像 *特征金字塔参数
MinLevel := 2 // 特征金字塔最小层级(用于检测大物体)
MaxLevel := 4 // 特征金字塔最大层级(用于检测小物体) *锚点框参数
NumSubscales := 3 // 每个层级的缩放级别数量
AspectRatios := [1.0,0.5,2.0] // 锚点框宽高比(1:1,1:2,2:1)
Capacity := 'medium' // 模型复杂度(medium平衡速度与精度) *** 创建模型参数字典 ***
create_dict (DLModelDetectionParam) // 创建空字典
set_dict_tuple (DLModelDetectionParam, 'image_width', ImageWidth)
set_dict_tuple (DLModelDetectionParam, 'image_height', ImageHeight)
set_dict_tuple (DLModelDetectionParam, 'image_num_channels', ImageNumChannels)
set_dict_tuple (DLModelDetectionParam, 'min_level', MinLevel)
set_dict_tuple (DLModelDetectionParam, 'max_level', MaxLevel)
set_dict_tuple (DLModelDetectionParam, 'num_subscales', NumSubscales)
set_dict_tuple (DLModelDetectionParam, 'aspect_ratios', AspectRatios)
set_dict_tuple (DLModelDetectionParam, 'capacity', Capacity) *** 实例化检测模型 ***
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle) // 输出模型句柄
2. 数据预处理配置
*** 路径配置 ***
DataDir := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/目标检测/目标检测' // 项目根目录
HalconImageDir:= DataDir + '/testImages/' // 测试图像存储路径
PillBagHdictFile := DataDir + '/images.hdict' // 数据集描述文件(含标注信息)
DLModelFileName := DataDir + '/pretrained_dl_model_detection.hdl' // 模型保存路径
DataDirectory := DataDir + '/dataset' // 预处理后的数据存储目录
PreprocessParamFileName := DataDirectory + '/dl_preprocess_param_' + ImageWidth + 'x' + ImageHeight // 预处理参数文件 *** 数据集划分参数 ***
TrainingPercent := 80 // 训练集比例(单位:%)
ValidationPercent := 10 // 验证集比例
SeedRand := 42 // 随机数种子(确保可复现) *** 目录检查与创建 ***
file_exists (DataDir, FileExists) // 检查根目录是否存在
if (not FileExists)
make_dir (DataDir) // 自动创建缺失目录
endif *** 加载原始数据集 ***
read_dict (PillBagHdictFile, [], [], DLDataset) // 读取HDICT格式的数据集描述文件
get_dict_tuple (DLDataset, 'class_ids', ClassIDs) // 获取类别ID列表
set_dict_tuple (DLDataset, 'image_dir', DataDir+'/images/') // 设置实际图像路径
set_dl_model_param (DLModelHandle, 'class_ids', ClassIDs) // 绑定类别ID到模型 *** 保存初始模型 ***
write_dl_model (DLModelHandle, DLModelFileName) // 保存模型到指定路径 *** 数据集划分 ***
set_system ('seed_rand', SeedRand) // 设置随机种子
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, []) // 按比例分割数据集 *** 生成预处理参数 ***
create_dict (GenParam)
set_dict_tuple (GenParam, 'overwrite_files', true) // 允许覆盖已有文件
create_dl_preprocess_param_from_model (DLModelHandle, 'false', 'full_domain', [], [], [], DLPreprocessParam) // 从模型生成预处理参数 *** 执行数据预处理 ***
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename) // 输出预处理后的数据集
这里唯一要注意的就是(填你们自己的路径噢):
DataDir := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/目标检测/目标检测' // 项目根目录
3. 模型训练流程
*** 训练参数配置 ***
set_dl_model_param (DLModelHandle, 'batch_size', 1) // 批大小(根据显存调整)
set_dl_model_param (DLModelHandle, 'learning_rate', 0.001) // 初始学习率
set_dl_model_param (DLModelHandle, 'runtime_init', 'immediately') // 立即初始化运行时 *** 创建训练配置 ***
create_dl_train_param (DLModelHandle, 20, 1, 'true', 42, [], [], TrainParam) // 参数说明:
* 20: 训练轮次
* 1: 每1个epoch验证一次
* 'true': 显示进度条
* 42: 固定随机种子 *** 启动训练过程 ***
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos) // 输出训练指标 *** 加载最佳模型 ***
read_dl_model ('model_best.hdl', DLModelHandle) // 加载验证集最优模型
dev_disp_text ('Press F5 to continue', 'window', 'bottom', 'left', 'black', [], []) // 暂停提示
stop ()
dev_close_window () // 清理训练过程窗口
dev_close_window ()
训练过程中可以看到我们的实时参数的变化情况,我们最好的平均AP是在第19次达到了0.74左右,如果我们的数据量足够多这个值还可以继续提升。
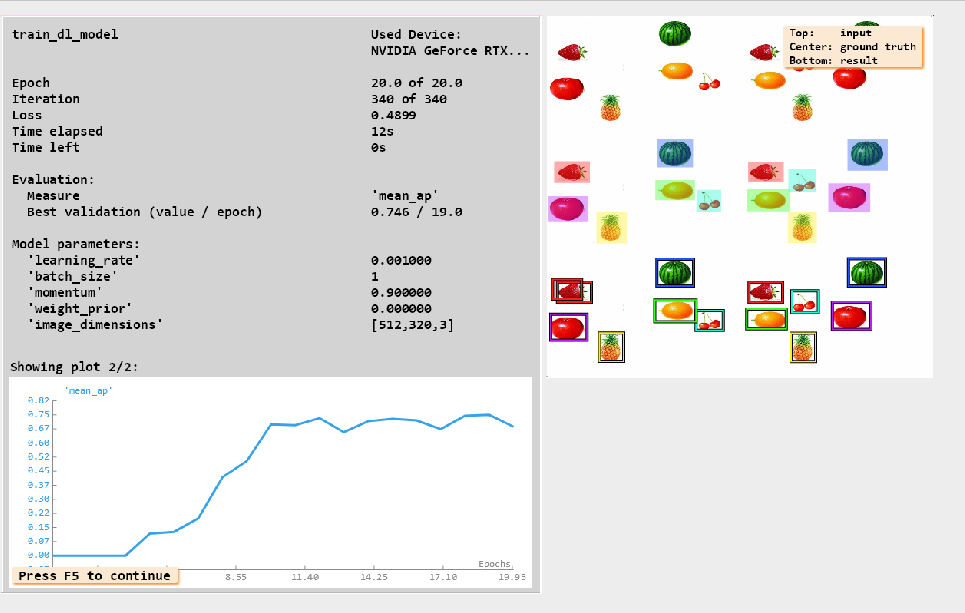
4. 模型性能评估
*** 评估参数配置 ***
create_dict (WindowDict) // 创建窗口句柄字典
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'detailed_evaluation', true) // 启用详细评估模式
set_dict_tuple (GenParamEval, 'show_progress', true) // 显示进度条 *** 执行测试集评估 ***
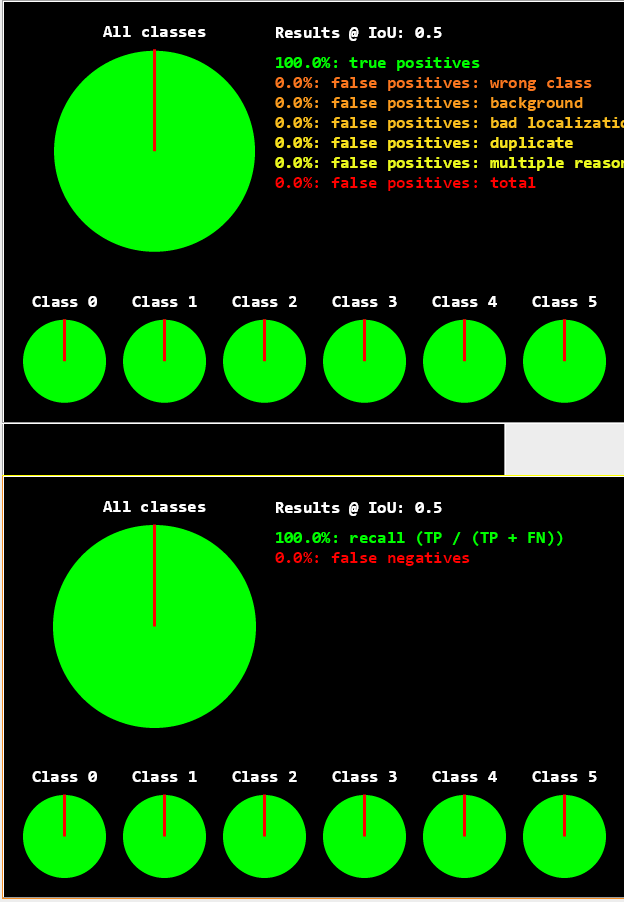
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams) // 在测试集上评估 *** 可视化评估结果 ***
create_dict (DisplayMode)
set_dict_tuple (DisplayMode, 'display_mode', ['pie_charts_precision','pie_charts_recall']) // 显示精确度/召回率饼图
dev_display_detection_detailed_evaluation (EvaluationResult, EvalParams, DisplayMode, WindowDict) // 绘制可视化图表
stop () // 暂停查看结果
dev_display_dl_data_close_windows (WindowDict) // 关闭评估窗口
可以看到我们在测试集上的效果还是不错的,精确率和召回率都还挺高(当然这里是因为数据量太少导致的,数据量足够大,我们才可以得到更合适的模型)
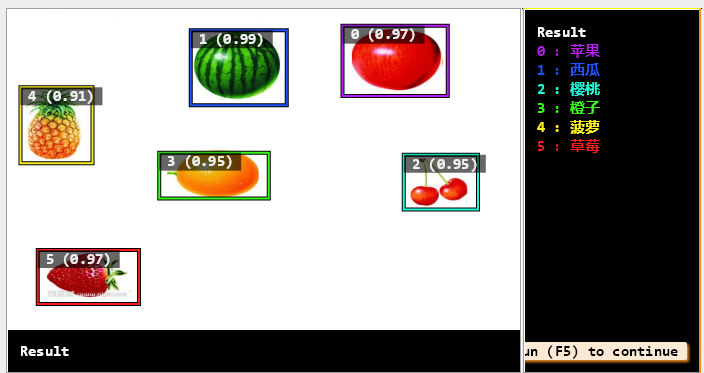
5. 模型推理测试
*** 准备测试数据 ***
list_image_files (HalconImageDir, 'default', 'recursive', ImageFiles) // 递归获取所有测试图片
tuple_shuffle (ImageFiles, ImageFilesShuffled) // 打乱图片顺序 *** 配置推理参数 ***
set_dl_model_param (DLModelHandle, 'batch_size', 1) // 设置单张推理模式 *** 遍历测试图片 ***
for i := 0 to |ImageFiles|-1 by 1
read_image (Image, ImageFilesShuffled[i]) // 读取单张图像
gen_dl_samples_from_images (Image, DLSampleInference) // 生成推理样本
preprocess_dl_samples (DLSampleInference, DLPreprocessParam) // 执行预处理 *执行推理与可视化
apply_dl_model (DLModelHandle, DLSampleInference, [], DLResult) // 模型推理
dev_display_dl_data (DLSampleInference, DLResult, DLDataset, 'bbox_result', [], WindowDict) // 显示带框结果
dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) // 操作提示
stop () // 逐张查看结果
endfor *** 清理资源 ***
dev_display_dl_data_close_windows (WindowDict) // 关闭所有推理窗口
这里就是把图片一个个传入进去,然后得到每个分类的结果了

整体上就是这样了,注释我都打的比较清楚,项目demo的百度云代码也给了,重要的算子也是解析很全了,应该理解起来不难吧,如果还有一些名词不懂可以在百度一下。halcon的深度学习的模型还是比较一般的,后面我可能会写目前公认比较优秀的yolo目标检测的深度学习,有兴趣可以关注一下。
其实我的想法就是不要把深度学习想的太难,因为你又不是博士或者硕士里的顶尖大牛,归根结底我们只能做应用而已,只要会使用这些模型就可以了,设计神经网络什么的都是年薪几百几千万的大牛们去做的事情。
最后的最后,望与诸君共勉。
halcon 深度学习教程(三) 目标检测之水果分类的更多相关文章
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- 深度学习与CV教程(12) | 目标检测 (两阶段,R-CNN系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 深度学习与CV教程(13) | 目标检测 (SSD,YOLO系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
- Deep Learning 7_深度学习UFLDL教程:Self-Taught Learning_Exercise(斯坦福大学深度学习教程)
前言 理论知识:自我学习 练习环境:win7, matlab2015b,16G内存,2T硬盘 练习内容及步骤:Exercise:Self-Taught Learning.具体如下: 一是用29404个 ...
随机推荐
- 记一次 contentInsetAdjustmentBehavior 引发的bug
注:本文同步发布于微信公众号:stringwu的互联网杂谈记一次 contentInsetAdjustmentBehavior 引发的bug 1 背景 项目中使用到了UILable来展示相关的文本内容 ...
- 2024-12-28 AI智能体日报
- runoob-TypeScript 教程
https://www.runoob.com/typescript/ts-tutorial.html TypeScript 是 JavaScript 的一个超集,支持 ECMAScript 6 标准( ...
- 转载:大模型所需 GPU 内存笔记
转载文章:大模型所需 GPU 内存笔记 引言 在运行大型模型时,不仅需要考虑计算能力,还需要关注所用内存和 GPU 的适配情况.这不仅影响 GPU 推理大型模型的能力,还决定了在训练集群中总可用的 G ...
- 镜像分层复用与Dockerfile
- HTB Builder walkthrough
nmap nmap -sS -A -T4 10.10.11.10 Starting Nmap 7.95 ( https://nmap.org ) at 2025-01-20 01:31 UTC Nma ...
- 从找零钱问题到三数之和:一道经典面试算法题的全面剖析|LeetCode 15 三数之和
LeetCode 15 三数之和 点此看全部题解 LeetCode必刷100题:一份来自面试官的算法地图(题解持续更新中) 生活中的算法 想象你是一个收银员,顾客给了你一张100元钱,商品只要85元. ...
- 解决“yarn : 无法加载文件 C:\Users\quber\AppData\Roaming\npm\yarn.ps1,因为在此系统上禁止运行脚本”问题
1.问题描述 我们在使用yarn命令的时候,可能会出现如下图所示的错误: 2.解决办法 出现此错误的原因是本地计算机上运行你编写的未签名脚本和来自其他用户的签名脚本,可以使用如下命令将计算机上的执行策 ...
- 使用-数据湖Iceberg和现有hive数仓打通并使用
一.集群配置 1.版本使用 技术 版本 iceberg 1.3.1 flink 1.16.1 spark 3.2.1 hive 2.3.7 dlc-presto 待定 2.集群配置调整 (1)使用hi ...
- ctfshow web入门 文件包含全部wp
Web78 <?php if(isset($_GET['file'])){ $file = $_GET['file']; include($file); }else{ highlight_fil ...