SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第3部分)(完结)
一个简单的更新查询
现在应该知道只读取数据的查询生命周期,下一步来认定当你需要更新数据时会发生什么。这个部分通过看一个简单的UPDATE查询,修改刚才例子里读取的数据,来回答。
庆幸的是,直到存取方法(Access Methods)前,更新操作和刚才SELECT语句流程是一模一样的。
这次存取方法(Access Methods)需要修改数据,因此在I/O请求传递前,修改的细节要存放于硬盘。这个就是事务管理器(Transaction Manager)的工作。
事务管理器(Transaction Manager)
事务管理器(Transaction Manger)这里有2个有趣的组件:锁管理器(Lock Manager)和日志管理器(Log Manager)。锁管理器(Lock Manager)为数据提供并发性负责,它通过使用锁传递配置的隔离级别。
备注:
在刚才提到的SELECT查询生命周期里,锁管理器(Lock Manager)也有用到,这里继续谈的话会岔开话题,这里它被提到因为它是事务管理器(Transaction Manager)的一部分。
这里真正有趣的东西是日志管理器(Log Manager),存取方法(Access Methods)代码里想要做出改变的请求被记录,日志管理器(Log Manager)把这些改变写到事务日志(transaction log),这个就是预写式日志(Write-Ahead Logging:WAL)。
写入事务日志(transaction log)是数据修改事务的一部分,它总是需要物理写入硬盘,因为即使在系统崩溃的时候,SQL Server可以靠它来重读那些改变(在接下来的还原章节你会学到这个更多)。
在事务日志(transaction log)里实际存放的并不是修改语句清单,而是修改语句的结果造成页面变更的细节。这是SQL Server为了可以撤销修改,这也让事务日志(transaction log)内容很难读懂,当然你可以借助第三方工具来帮忙。
回到UPDATE查询生命周期,更新操作已经被写到日志。当事务日志已经确认物理写入后,实际的数据才会修改。这也是为什么事务日志(transaction log)操作重要。
一旦存取方法(Access Methods)收到确认,它把修改请求发给缓冲区管理器(Buffer Manager)来完成。
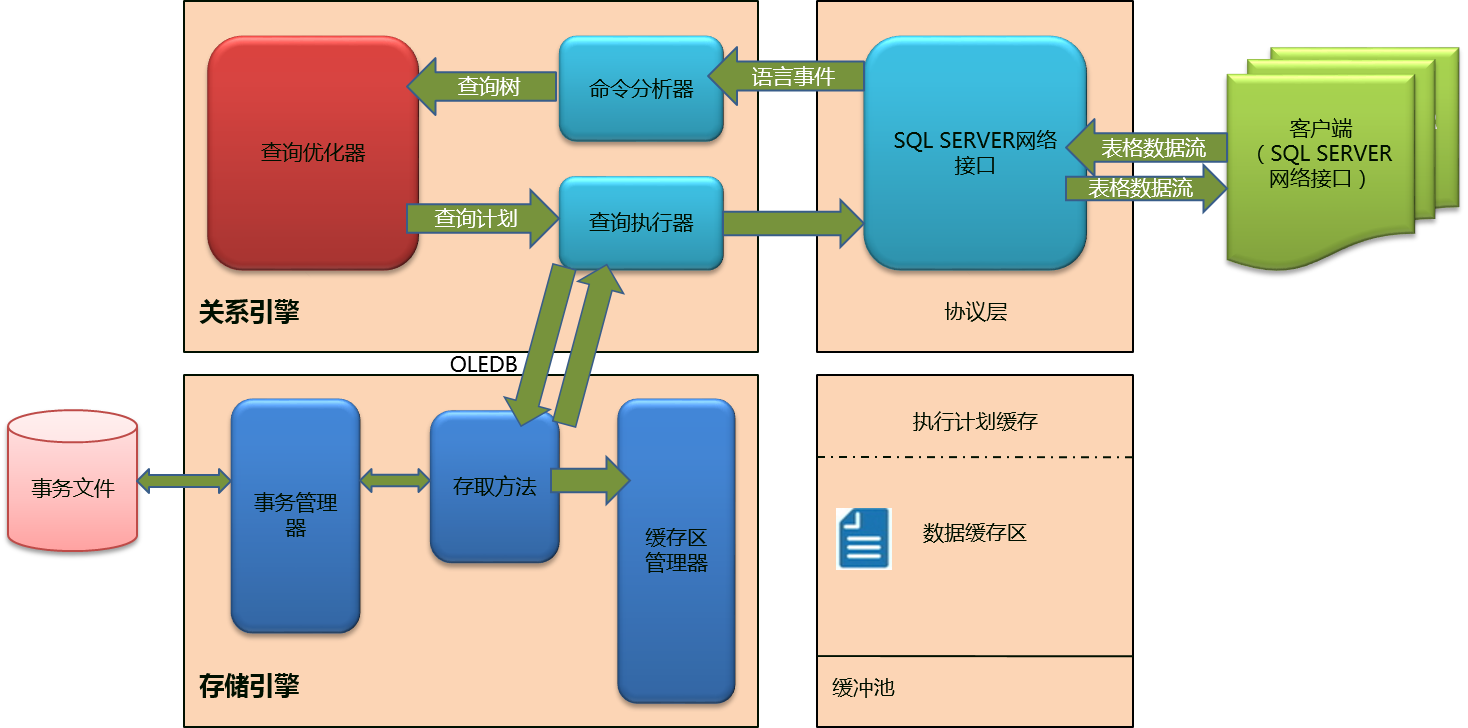
事务管理器(Transaction Manager),存取方法(Access Methods),记录我们更新的事务日志(transaction log),完成数据修改请求的缓冲区管理器(Buffer Manager)。
缓存区管理器(Buffer Manager)
需要修改的页已经在缓存里了,缓存区管理器(Buffer Manager)要做的只是修改需要的页, 这个更新请求由存取方法(Access Methods)发起。在缓存中的页被修改后,确认会发回给存取方法(Access Methods),最后发回给客户端。
这里的关键点(也是最大的)是UPDATE语句只改变数据缓存里的数据,并不是在磁盘上的实际数据库文件。这样做是基于性能的原因,现在这个也被称为所谓的脏页(Dirty Page),因为它和硬盘上对应页是不一样的。
这与ACID属性里定义的修改耐久性(durability of the modification)并不违背,因为你可以使用事务日志重建改变。举例来说,如果你服务器突然断电,物理内存(例如数据缓存区)里就啥都没有了。脏页是如何并在什么时候写回数据库文件在下一章节会介绍。
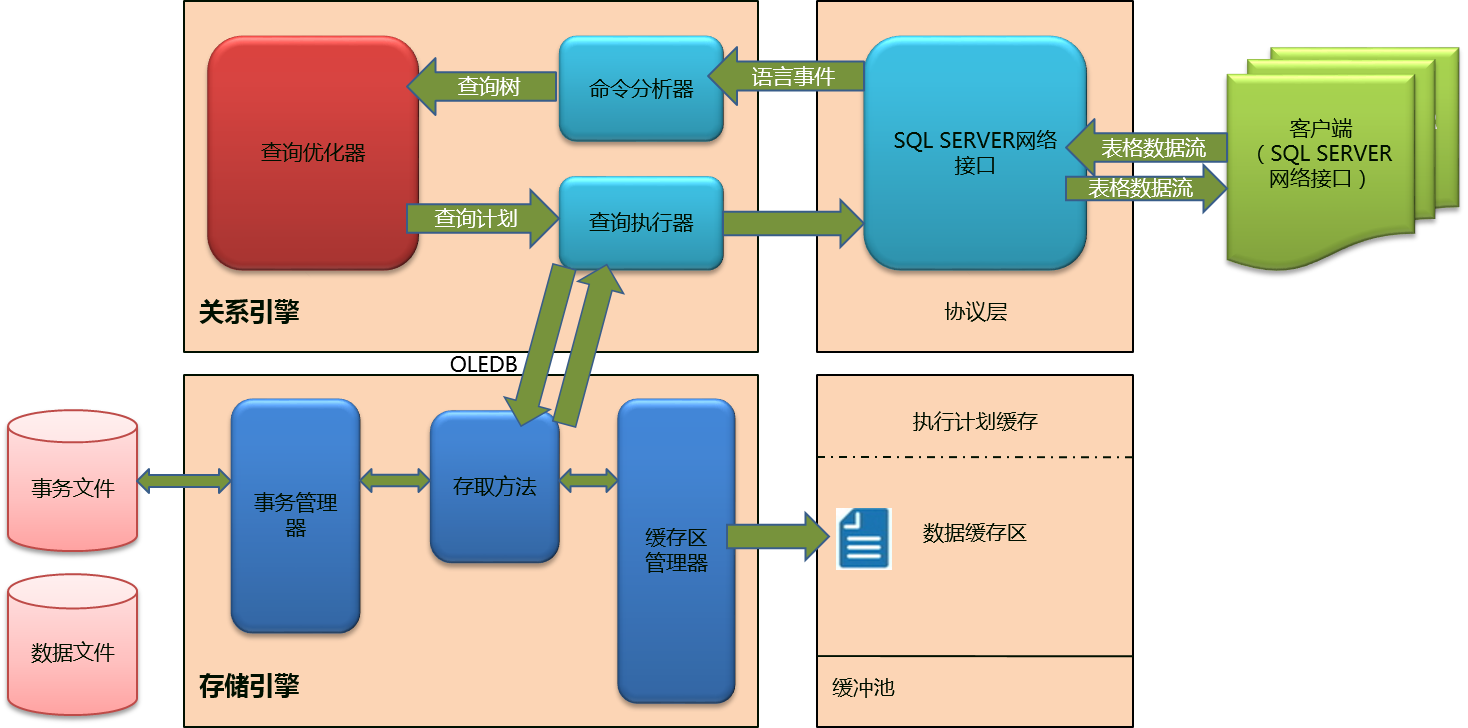
更新操作的生命周期如上图所示。缓冲区管理器(Buffer Manager)改变缓存中页的内容,并发送确认给存取方法(Access Methods)。可以看到,在此期间,数据文件一直没被访问。
还原(Recovery)
在上一章节,你读到了UPDATE查询的生命周期,里面谈到了SQL Server使用预写式日志(Write-Ahead Logging:WAL)方法来保持任何更改的耐久性(durability of any changes)。
变更首先写入事务日志(transaction log),然后只停留在内存里。这样做是基于性能原因并使你需要撤销的话可以从事务日志(transaction log)里还原。在还原章节会介绍更多的相关新概念和流程(new concepts and terminology)。
脏页(Dirty Pages)
从磁盘读回内存的页别标识为干净页(clean page)因为它和它的副本是一样的。同样,一旦在内存里的页被修改会被标识为脏页(Dirty Page)。
使用清空缓存(DBCC DROPCLEANBUFFERS)可以从缓存里清掉干净页(Clean pages)(注:从缓冲池中删除所有缓冲区。),当你对开发和测试环境进行故障排除时非常方便,因为它强制从磁盘后续读取来实现,不是缓存,不接触任何脏页。
脏页(dirty page)就是自硬盘加载到内存有改变且现在和磁盘上不一样。用下面的动态视图可以看每个数据库有多少脏页。
SELECT db_name(database_id) AS 'Database',count(page_id) AS 'Dirty Pages'
FROM sys.dm_os_buffer_descriptors
WHERE is_modified =1
GROUP BY db_name(database_id)
ORDER BY count(page_id) DESC
Database Dirty PagesPeople 2524Tempdb 61Master 1
如上表示在People数据库有20M的脏页(2524 * 8 / 1024).
每当缓存空闲不足或检查点(checkpoint)发生时,这些脏页(dirty page)会被定期写回到数据库。为了更快的分配页,SQL Server总是在缓存里保持一定数量的可用空页,这些可用空页在可用缓存列表里被跟踪。
当一个工作线程(worker thread)发起一个读请求时,它在缓存拿到64页的列表并检查这个缓存列表是否低于特定的阈值(threshold)。如果是的话,会把列表里的页标记为过期(age-out),这会引起把任何脏页(dirty page)写回硬盘。另外一个称为惰性写入器(Lazy Writer)的线程也是基于空闲缓存列表(free buffer list)不足。
惰性写入器(Lazy Writer)
惰性写入器(Lazy Writer)会定期检查空闲缓存列表(free buffer list)的大小。当值低的时候,它会扫描整个数据缓存把有段时间没用过的页标记为过期(age-out),在内存里标记它们为空闲前会写回硬盘。
惰性写入器(Lazy Writer)也会在服务器上监控可用物理内存,在内存非常不足的情况下会把空闲缓存列表(free buffer list)的内存释放回给系统。当SQL Server 很忙的时候,在还有可用物理内存和没到服务器最大内存配置阈值时,它会增大空闲缓存列表(free buffer list)的大小来满足(缓冲池(Buffer Pool)的)要求。
检查点过程(Checkpoint Process)
检查点(Check Point)是个SQL Server创建的时间点,用来保证任何提交的事务已经将它们的变更写回硬盘。检查点(Check point)成为数据库可以开始的还原点。
检查点过程(Check Point Process)用来保证已提交的事务相关的所有脏页(dirty page)已经写回硬盘。为了有效使用写入器,它也会把未提交的脏页(dirty page)也写回硬盘,不像惰性写入器(Lazy Writer),检查点(Check Point)不会从缓存中移除页;它只把脏页(dirty page)写回硬盘并在缓存页的页头将缓存里页标记为干净。
默认情况下,在一个忙碌的服务器里,SQL Server会在每分钟发起一次检查点(Check Point),这会标记在事务日志里。如果SQL Server实例或数据库重启了,还原过程会读取日志来获知,自上一个检查点后的日志里不需要进行任何操作。
日志序列号(Log Sequence Number:LSN)
日志序列号(Log Sequence Number:LSN)在事务日志里标识记录,它被排序的,因此SQL Server可以知道事件发生的顺序。
像进行前滚或后滚的还原前,最小的LSN号会被拿到。考虑这个不仅是检查点(Check Point)日志序列号(Log Sequence Number:LSN),还有其他更重要的。这就是说还原还需要担心在检查点(Check point)前,是否有脏页(dirty page)还没写回硬盘。这个在有大量数目脏页(dirty page)的大系统里会发生。
因此检查点(Check Point)之间的时间内,代表着大量的工作需要处理来,在上一个检查点(Check Point)发生后,前滚任何提交的事务,或后滚任何没有提交的事务。通过每分钟的检查点(Check Point),SQL Server尝试保证还原时间自一个数据库开始少于1分钟,在此期间它不会自动执行检查点(Check Point),除非有10MB的日志写入。
检查点(Check Point)可以通过CHECK POINT的T-SQL命令人为执行,也可以由SQL Server里的其它事件来触发。例如,你发起一个备份命令时,检查点(Check Point)会首先执行。
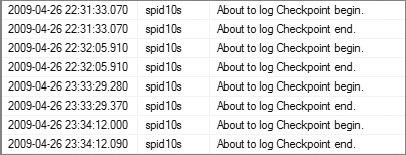
跟踪号(trace flag)3502是检查点(Check Point)开始和结束的错误号。例如,在自启动后添加刚才的跟踪号,在执行一系列的大量写入后,我们在错误日志里可以看到如下的条目,可以看到检查点(Check Point)在30-40秒之间执行一次。
跟踪号(trace flag)提供改变SQL Server行为的一种途径,通常帮助我们进行故障排除或者出于测试目的启用或停用特定的功能。有几百个跟踪号(trace flag)存在但官方只公开部分;点击查看它的公开列表还有如何使用它:
恢复间歇(Recovery Interval)
恢复间歇(Recovery Interval)是个服务器配置选项,可以用来调整检查点(Check Point)间的时间差,因此可以设置自开始多少时间内的数据库可以还原,恢复间歇(Recovery Interval)。
默认情况下,恢复间歇(Recovery Interval)设置为0;这会启用SQL Server选择一个合适的间歇(Interval),通常是接近于1分钟自动执行一次检查点(Check Point)。
改变这个值为大于0时,代表你希望在检查点(Check Point)的之间的间歇时间大小。大多数情况下不没必要修改,与还原时间比,你更在乎检查点(Check Point)过程,你来决定是否设置。
恢复间歇(Recovery Interval)只在测试和实验环境下才配置,为了有效的停止自动检查点(Check Point),出于监控东西的目的或获取更好的性能,可以配置出奇很高值。除非你为了SQL Server赶上世界记录速度,你不应该在真实生产环境里修改这个值。
为了停止对磁盘子系统的太多影响,SQL Server甚至会抑制检查点的I/O,因此它很会进行自我管理。如果你在服务器上曾看到SLEEP_BPOOL_FLUSH的等待类型,这是因为SQL Server为了保持全局系统的性能进行了检查点的I/O抑制。
还原方式(Recovery Models)
SQL Server有3种数据库还原方式(Recovery Models):完整(Full),批日志(Bulk-Logged)和简单(Simple)。你选择的方式会影响到你事务日志的使用方式,它增长到多大,你的备份策略,还有你的还原选项。
完整(Full)
使用完整(Full)还原方式,会要求所有操作已经在事务日志里完整写入,在备份策略里要求包含完整(Full)备份和事务日志(transaction log)备份。
自SQL Server 2005开始,完整(Full)备份不清空(truncate)事务日志(transaction log)。这样做的话事务日志备份的序列不会被损坏,在你完整备份损坏的情况提供一个额外的还原选项。
SQL Server数据库如果需要更高级别的还原性,你应该使用完整(Full)还原方式。
批日志(Bulk-Logged)
这是个很特殊的还原方式,想这样做的话,是通过最小量的日志写入,来提高特定批量操作的性能。其他操作会和完整(FULL)还原方式一样完全写入日志。因为只有回滚事务需要的信息被写入日志,这个方式可以提高性能。重做信息没有写入日志,这也表示你失去了基于时间点的还原(point-in-time-recovery)。
这些批日志包括:
- 批量插入(BULK INSERT)
- 使用可执行的BCP(Using the bcp executable)
- SELECT INTO
- 创建索引(CREATE INDEX)
- 修改索引重建(ALTER INDEX REBUILD)
- 删除索引(DROP INDEX)
批日志(Bulk-Logged)和事务日志(Transaction Log)备份
使用批日志(Bulk-Logged)模式是想让你的批日志(Bulk-Logged)操作更快完成。它不会为你的事务日志(transaction log)备份减少磁盘空间需求。
简单(Simple)
如果在数据库上设置了简单(Simple)还原,,每次检查点(Check Point)里发生的事务日志里,所有提交的事务都会被清空(truncate)。这是为了保证日志大小保持在最小,并且不需要事务日志(transaction log)备份(如果没有的话),是好是坏看你对一个数据库的还原级别要求。
如果自上次的完整(FULL)或差异(differential)备份起潜在丢失的所有变更,仍满足你的业务需要的话,你可以选择简单(Simple)还原。
参考文章:
SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第3部分)(完结)的更多相关文章
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第2部分)
计划缓存(Plan Cache) 如果SQL Server已经找到一个好的方式去执行一段代码时,应该把它作为随后的请求重用,因为生成执行计划是耗费时间且资源密集的,这样做是有有意义的. 如果没找到被缓 ...
- SQL Server 2012:SQL Server体系结构——一个查询的生命周期(第1部分)
为了缩小读取操作所涉及范围,本文首先着眼于简单的SELECT查询,然后引入执行更新操作有关的附加过程.最后你会读到,优化性能时SQLServer使用还原工具的相关术语和流程. 关系和存储引擎 如图所示 ...
- SQLSERVER 免费对比数据库结构和数据的工具支持:SQL Server 2012, SQL Server 2008 and SQL Server 2005
New xSQL Schema Compare - version 5 Compare the schemas of two SQL Server databases, review differen ...
- [oldboy-django][2深入django]django一个请求的生命周期 + WSGI + 中间件
1 WSGI # WSGI(是一套协议,很多东西比如wsgiref, uwsgiref遵循这一套协议) - django系统本质 别人的socket(wsgiref或者uwsgiref) + djan ...
- (四)一个bug的生命周期
Bug的属性 Bug重现环境 这个应该是我们重现BUG的一个前提,如果没有这个前提,我们可能会无法重现问题,或者根本就无从下手. • 操作系统 这个是一般软件运行的一大前提,基本上所有的软件都依赖于操 ...
- SQL Server 2012 - SQL查询
执行计划显示SQL执行的开销 工具→ SQL Server Profiler : SQL Server 分析器,监视系统调用的SQL Server查询 Top查询 -- Top Percent 选择百 ...
- windows server 2012 + sql server 2008 r2安装
windows server 2012 r2 里面安装 sql server 2008 r2 问题总结 前提是 windows server 2012 r2 已经安装完成 ,(仅仅是安装完成 啥服 ...
- JVM学习笔记:JVM的体系结构与JVM的生命周期
1 JVM在java平台中的位置 1.1 Java平台组成 Java平台主要由Java虚拟机和Java API这两部分组成.参考Oracle官网. 1.2 java平台结构图 JDK1.2开始,迫于J ...
- JAVA虚拟机体系结构JAVA虚拟机的生命周期
一个运行时的Java虚拟机实例的天职是:负责运行一个java程序.当启动一个Java程序时,一个虚拟机实例也就诞生了.当该程序关闭退出,这个虚拟机实例也就随之消亡.如果同一台计算机上同时运行三个Jav ...
随机推荐
- Oracle 12c 安装手册
Oracle 12C 首次安装 期待已久的Oracle 12C 终于发布了,我迫不及待的下载了介质,一睹风采. 下载地址:http://www.oracle.com/technetwork/datab ...
- 《STL系列》之map原理及实现
上一篇文章<STL系列>之vector原理及实现,介绍了vector的原理及实现,这篇文章介绍map的原理及实现.STL实现源码下载.STL中map的实现是基于RBTree的,我在实现的时 ...
- 成功在神舟K650c-i7 d2(i7-4700MQ、HM87)上装好了Windows XP
成功在神舟K650c-i7 d2(i7-4700MQ.HM87)上装好了Windows XP 本来已经在K650c上装好了Windows7.Windows8双系统,奈何某些旧软件只能在Windows ...
- mediawiki的安装与配置
apache的配置: 1. 开启php module 查看mods-enabled/php5.load 是否存在,不存在的话, 就从mods-avaliable中复制一个到mods-enabled中. ...
- java生成解析xml的另外两种方法JAXB
JAXB(Java Architecture for XML Binding) 是一个业界的标准,是一项可以根据XML Schema产生Java类的技术.该过程中,JAXB也提供了将XML实例文档反 ...
- Python 中Editplus 特别实用的设置方法
editplus 中输入tab自动变成4个空格打开tools->preference打开面板,files的子栏目->settings & syntax面板中的 tab/indent ...
- floor相关
select floor(@f*0.22) -- 直接可显示结果 create table demo( id ,), id1 int ) select * from demo insert into ...
- Eclipse中集成Tomcat
问题: 很多时候在Eclipse中启动Tmocat后,不能访问本机的localhost:8080主页,并且其他项目也不能访问. 原因: 打开Tomcat下的webapp后也找补到项目目录,这是因为Ec ...
- HP原装硒鼓
- 最近一直在搞CAE,发现Eplan p8真的好强大。
最近一直在搞CAE,发现Eplan p8真的好强大. 标准化的意义在与提高工作效率,减少重复. 标准化后,不容易出错,项目更改容易.事件都能及时跟踪.