SQLServer之添加聚集索引
聚集索引添加规则
聚集索引按下列方式实现
PRIMARY KEY 和 UNIQUE 约束
在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动对一列或多列创建唯一聚集索引。 主键列不允许空值。
在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束。 如果不存在该表的聚集索引,则可以指定唯一聚集索引。
将索引创建为约束的一部分后,会自动将索引命名为与约束名称相同的名称。 有关详细信息,请参阅 Primary and Foreign Key Constraints 和 Unique Constraints and Check Constraints。
独立于约束的索引
指定非聚集主键约束后,您可以对非主键列的列创建聚集索引。
限制和局限
创建聚集索引结构后,旧(源)结构和新(目标)结构的各自的文件和文件组都需要磁盘空间。 在完成事务提交后,才会释放旧结构。 排序也需要其他临时磁盘空间。 有关详细信息,请参阅 Disk Space Requirements for Index DDL Operations。
如果对具有多个现有非聚集索引的堆创建聚集索引,则必须重新生成所有非聚集索引,以使它们包含聚集键值而非行标识符 (RID)。 同样,如果删除具有多个非聚集索引的表的聚集索引,在 DROP 操作过程中,将重新生成非聚集索引。 对于大型表,这可能需要很长时间。
对大型表创建索引的首选方法是先创建聚集索引,然后创建任何非聚集索引。 在对现有表创建索引时,请考虑将 ONLINE 选项设置为 ON。 如果设置为 ON,则不会持有长期表锁。 这使对基础表的查询或更新可以继续进行。 有关详细信息,请参阅 Perform Index Operations Online。
聚集索引的索引键不能包含在 ROW_OVERFLOW_DATA 分配单元中具有现有数据的
varchar列。 如果对varchar列创建了聚集索引,并且在 IN_ROW_DATA 分配单元中存在现有数据,则对该列执行的将数据推送到行外的后续插入或更新操作将会失败。 若要获得有关可能包含行溢出数据的表的信息,请使用 sys.dm_db_index_physical_stats (Transact-SQL)动态管理函数。
使用SSMS数据库管理工具添加聚集索引
使用表设计器创建聚集索引
1、连接数据库,选择数据库,选择数据表-》右键点击-》选择设计。
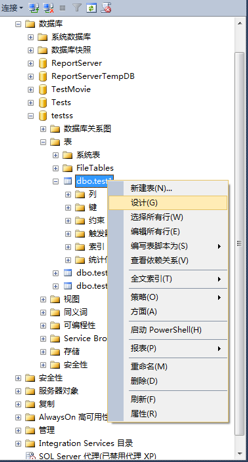
2、在表设计窗口-》选择要添加索引的数据列-》右键点击-》选择索引/键。
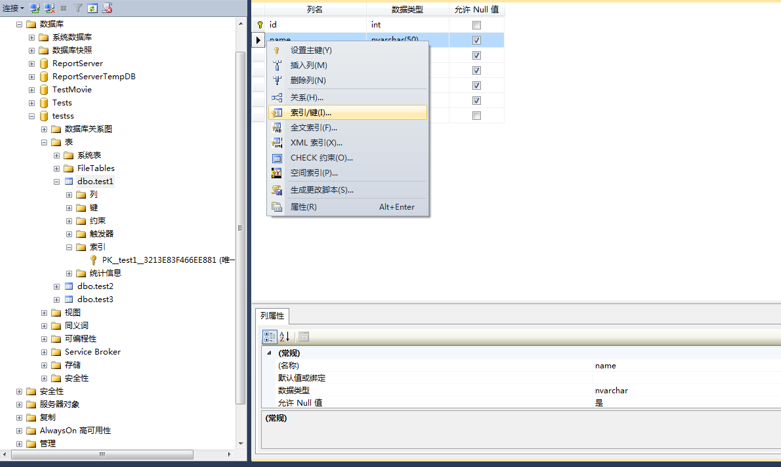
3、在索引/键弹出框中-》点击添加-》在常规窗口中类型选择索引-》点击选择列。
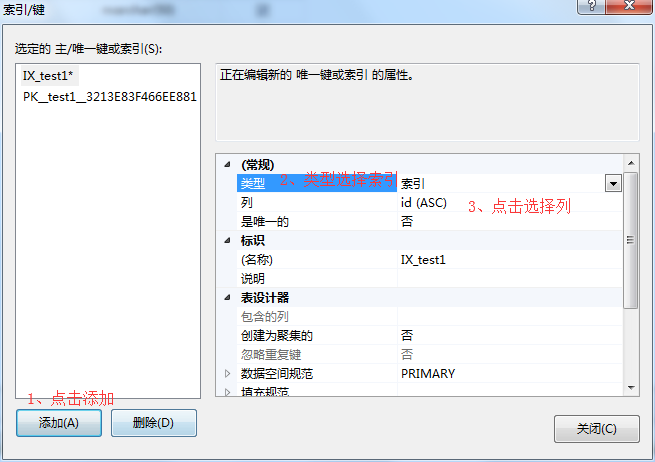
4、在索引列弹出框中-》选择索引列-》选择排序方式-》可以把索引建在一列或者多列上-》点击确定。
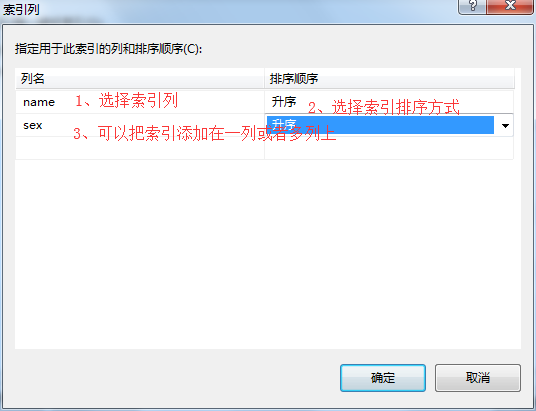
5、在索引/键弹出框中-》输入索引名称-》输入索引描述-》其它设置可以选择系统默认也可以选择自己设置-》点击关闭。

6、点击保存(或者ctrl+s)->关闭表设计器-》刷新表-》查看结果。
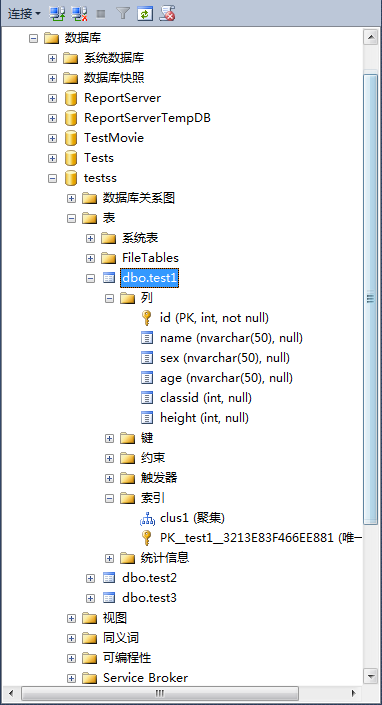
使用对象资源管理器创建聚集索引
1、连接数据库,选择数据库-》展开数据表-》右键单击索引文件夹-》选择新建索引-》选择聚集索引。

2、在新建索引弹出框-》在索性名称中输入索引名称-》选择是否创建唯一聚集索引-》点击添加,添加要添加索引的数据列。
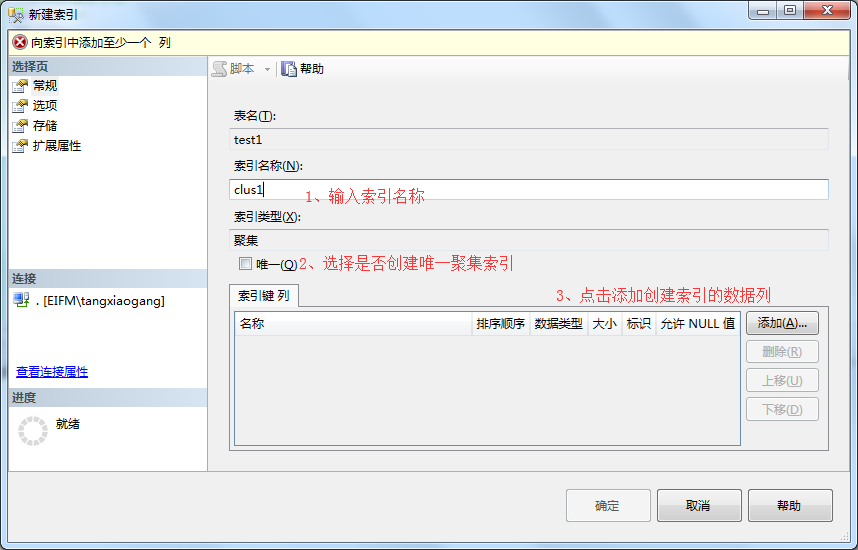
3、在数据表弹出框中-》选择数据列,可以选择多个-》点击确定。
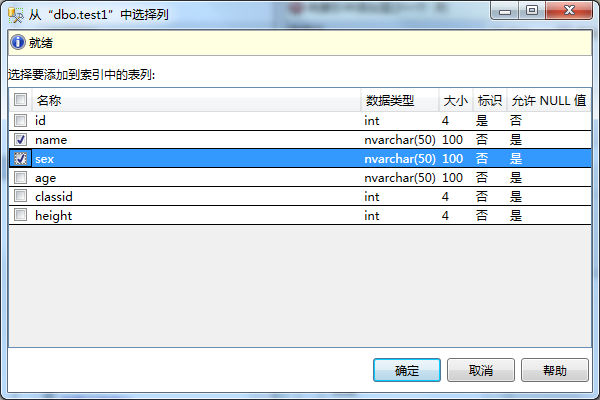
4、在新建索引弹出框中-》点击选项,关于选项配置可以选择系统默认,也可以根据需要自己配置。
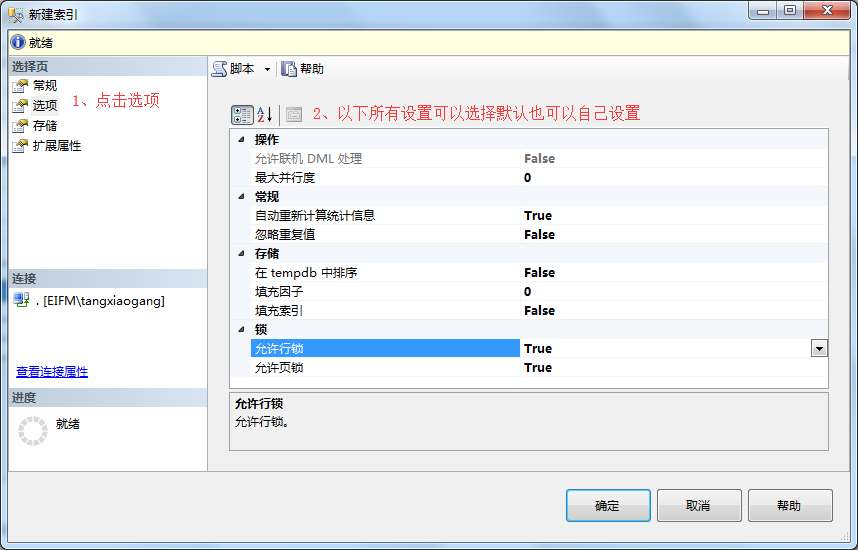
5、在新建索引弹出框中-》点击存储,可以选择默认文件组和分区方案,也可以自行配置。

6、在新建索引弹出框中-》点击扩展属性,点击文件编辑符,输入索引描述-》单击确定。
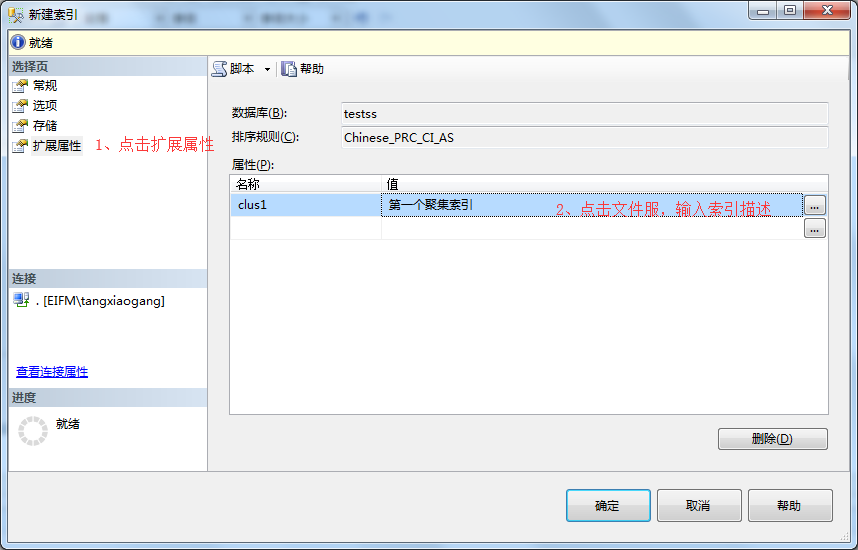

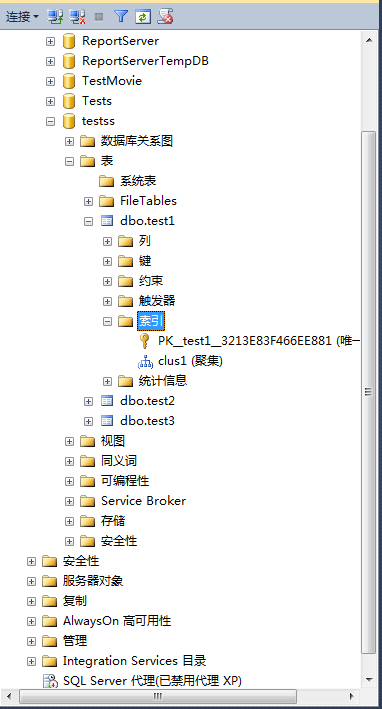
7、在对象资源管理器中即可看到新创建的索引(如果没有出现可以刷新再次查看)。
使用T-SQL脚本添加聚集索引
语法:
--声明数据库引用
use 数据库名;
go
--判断索引是否存在
if exists(select * from sysindexes where name=索引名)
drop index 索引名 on 表名 with (online=off);
go
--添加索引
create
--[unique] --指定聚集索引是否唯一
[clustered | nonclustered] --指定为聚集索引
index 索引名称 --索引名称
on 表名 --索引添加在哪个表
(列名 [asc | desc],列名 [asc | desc]) --索引添加在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index={ on | off },
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute={ on | off },
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb={ on | off },
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key={ on | off },
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing={ on | off },
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online={ on | off },
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks={ on | off },
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks={ on | off },
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=n
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
--maxdop=max_degree_of_parallelism,
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression={ none | row | page | columnstore | columnstore_archive }
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];--数据空间规范
go
--添加注释
execute sp_addextendedproperty N'MS_Description',N'索引说明',N'schema',N'dbo',N'table',N'test1',N'index',N'clus1';
go
示例:
--声明数据库引用
use testss;
go
--判断索引是否存在
if exists(select * from sysindexes where name='clus1')
drop index clus1 on test1 with (online=off);
go
--添加索引
create
--[unique] --指定聚集索引是否唯一
clustered --指定为聚集索引
index clus1 --索引名称
on test1 --索引添加在哪个表
(name asc,sex desc) --索引添加在哪个数据列
with(
--pad_index:指定索引填充
--pad_index=on:FILLFACTOR 指定的可用空间百分比应用于索引的中间级页。
--pad_index=off或未指定 fillfactor:考虑到中间级页上的键集,可以将中间级页几乎填满,但至少要为最大索引行留出足够空间。
pad_index=off,
--statistics_norecompute:指定是否重新计算统计信息。
--statistics_norecompute=on:过时的统计信息不会自动重新计算。
--statistics_norecompute=off:启用自动统计信息更新。
statistics_norecompute=off,
--sort_in_tempdb:指定是否将排序结果存储在 tempdb 中。
--sort_in_tempdb=on:在tempdb中存储用于生成索引的中间排序结果。如果tempdb与用户数据库不在同一组磁盘上,就可缩短创建索引所需的时间。但是,这会增加索引生成期间所使用的磁盘空间量。
--sort_in_tempdb=off:中间排序结果与索引存储在同一数据库中。
sort_in_tempdb=off,
--ignore_dup_key:指定在插入操作尝试向唯一索引插入重复键值时的响应类型。 IGNORE_DUP_KEY 选项仅适用于创建或重新生成索引后发生的插入操作。 当执行 CREATE INDEX、ALTER INDEX 或 UPDATE 时,该选项无效。 默认为 OFF。
--ignore_dup_key=on:打开,将重复键值插入唯一索引时会出现警告消息。只有违反唯一性的行为才会失败。
--ignore_dup_key=off:关闭,将重复键值插入唯一索引时会出现错误消息。回滚整个INSERT操作。对于对视图创建的索引、非唯一索引、XML 索引、空间索引以及筛选的索引,IGNORE_DUP_KEY 不能设置为 ON
ignore_dup_key=off,
--drop_existing:表示如果这个索引还在表上就 drop 掉然后在 create 一个新的。 默认为 OFF。
--drop_existing=on:指定要删除并重新生成现有索引,其必须具有相同名称作为参数 index_name。
--drop_existing=off:指定不删除和重新生成现有的索引。 如果指定的索引名称已经存在,SQL Server 将显示一个错误。
drop_existing=off,
--online:指定在索引操作期间基础表和关联的索引是否可用于查询和数据修改操作。 默认为 OFF。 REBUILD 可作为 ONLINE 操作执行。
--online=on:在索引操作期间不持有长期表锁。 在索引操作的主要阶段,源表上只使用意向共享 (IS) 锁。
--这使得能够继续对基础表和索引进行查询或更新。
--操作开始时,在很短的时间内对源对象持有共享 (S) 锁。
--操作结束时,如果创建非聚集索引,将在短期内获取对源的 S(共享)锁;
--当联机创建或删除聚集索引时,以及重新生成聚集或非聚集索引时,将在短期内获取 SCH-M(架构修改)锁。 但联机索引锁是短的元数据锁,特别是 Sch-M 锁必须等待此表上的所有阻塞事务完成。
--在等待期间,Sch-M 锁在访问同一表时阻止在此锁后等待的所有其他事务。 对本地临时表创建索引时,ONLINE 不能设置为 ON。
--online=off:在索引操作期间应用表锁。这样可以防止所有用户在操作期间访问基础表。
--创建、重新生成或删除聚集索引或者重新生成或删除非聚集索引的脱机索引操作将对表获取架构修改 (Sch-M) 锁。
--这样可以防止所有用户在操作期间访问基础表。 创建非聚集索引的脱机索引操作将对表获取共享 (S) 锁。 这样可以防止更新基础表,但允许读操作(如 SELECT 语句)。
online=off,
--aloow_row_locks:指定是否允许行锁。
--allow_row_locks=on:访问索引时允许行锁。数据库引擎确定何时使用行锁。
--allow_row_locks=off:不使用行锁。
allow_row_locks=on,
--allow_page_locks:指定是否允许使用页锁。
--allow_page_locks=on:访问索引时允许页锁。数据库引擎确定何时使用页锁。
-- allow_page_locks=off:不使用页锁。
allow_page_locks=on,
--fillfactor=n:指定一个百分比,指示在数据库引擎创建或修改索引的过程中,应将每个索引页面的叶级填充到什么程度。 指定的值必须是 1 到 100 之间的整数。 默认值为 0。
fillfactor=1
--maxdop=max_degree_of_parallelism:在索引操作期间替代 max degree of parallelism 配置选项。 有关详细信息,请参阅 配置 max degree of parallelism 服务器配置选项。 使用 MAXDOP 可以限制在执行并行计划的过程中使用的处理器数量。 最大数量为 64 个处理器。
--max_degree_of_parallelism 可以是:
--1 - 取消生成并行计划。
-->1 - 将并行索引操作中使用的最大处理器数量限制为指定数量。
--0(默认值)- 根据当前系统工作负荷使用实际数量的处理器或更少数量的处理器。
--有关详细信息,请参阅 配置并行索引操作。
--maxdop=1,
--data_compression=row:为指定的表、分区号或分区范围指定数据压缩选项。 选项如下所示:
--none
--不压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--row
--使用行压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--page
--使用页压缩来压缩表或指定的分区。 仅适用于行存储表;不适用于列存储表。
--columnstore
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表。 COLUMNSTORE 指定对使用 COLUMNSTORE_ARCHIVE 选项压缩的分区进行解压缩。 还原数据时,将继续通过用于所有列存储表的列存储压缩对 COLUMNSTORE 索引进行压缩。
--columnstore_archive
--适用范围: SQL Server 2014 (12.x) 到 SQL Server 2017。
--仅适用于列存储表,这是使用聚集列存储索引存储的表。 COLUMNSTORE_ARCHIVE 会进一步将指定分区压缩到更小。 这可用于存档,或者用于要求更少存储并且可以付出更多时间来进行存储和检索的其他情形
--data_compression=row
--on partitions ( { <partition_number_expression> | <range> } [ ,...n ] ) 适用范围: SQL Server 2008 到 SQL Server 2017。
--指定对其应用 DATA_COMPRESSION 设置的分区。 如果表未分区,ON PARTITIONS 参数将生成错误。 如果不提供 ON PARTITIONS 子句,DATA_COMPRESSION 选项将应用于已分区表的所有分区。
--可以按以下方式指定 <partition_number_expression>:
--提供一个分区号,例如:ON PARTITIONS (2)。
--提供若干单独分区的分区号并用逗号将它们隔开,例如:ON PARTITIONS (1, 5)。
--同时提供范围和单个分区,例如:ON PARTITIONS (2, 4, 6 TO 8)。
--<range> 可以指定为以单词 TO 隔开的分区号,例如:ON PARTITIONS (6 TO 8)。
--,请多次指定 DATA_COMPRESSION 选项
--on partitions(1-2)
)
on [primary];--数据空间规范
go
--添加注释
execute sp_addextendedproperty N'MS_Description',N'第一个聚集索引',N'schema',N'dbo',N'table',N'test1',N'index',N'clus1';
go

聚集索引优缺点
优点:
1、表记录的排列顺序与索引的排列顺序一致,查询速度快。
2、对于那些经常要搜索范围值的列添加聚集索引执行效率更高。
3、对从表中检索的数据进行排序时经常要用到某一列,可在该表的该列上创建聚集(物理排序)索引,避免每次查询该列时都进行排序,节省成本。
缺点:
1、对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。
2、索引需要占物理空间。
3、创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
SQLServer之添加聚集索引的更多相关文章
- SQLServer中重建聚集索引之后会影响到非聚集索引的索引碎片吗
本文出处:http://www.cnblogs.com/wy123/p/7650215.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- 对SQLServer错误使用聚集索引的优化案例(千万级数据量)
前言: 半个月前发了文章 SQLServer聚集索引导致的插入性能低 终于等到生产环境休整半天,这篇文章是对前文的实际操作. 以下正文开始: 异常:近期发现偶尔有新数据插入超时. 分析:插入条码有多种 ...
- 在SQLSERVER中创建聚集索引
CREATE CLUSTERED INDEX CLUSTER_id ON TABLE_name(ID)------批量
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- 【SqlServer】聚集索引与主键、非聚集索引
目录结构: contents structure [-] 聚集索引和非聚集索引的区别 聚集索引和主键的区别 主键和(非)聚集索引的常规操作 聚集索引.非聚集索引在SqlServer.MySQL.Ora ...
- 优化SQLServer——表和分区索引(二)
简介 之前一篇简单的介绍了语法和一些基本的概念,隔了一段时间,觉得有必要细致的通过实例来总结一下这部分内容.如之前所说,分区就是讲大型的对象(表)分成更小的块来管理,基本单位是行.这也就产生了 ...
- SQL SERVER 索引中聚集索引分析和Transact-SQL语句优化
一. 聚集索引B树分析1.聚集索引按B树结构进行组织的,索引B树种的每一页称为一个索引节点.B树的顶端节点称为根节点. 索引中的低层节点称为叶节点.根节点与叶节点之间的任何索引级别统称为中间级.在聚 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- sqlserver 聚集索引 非聚集索引
聚集索引是一种对磁盘上实际数据重新组织以按指定的一列或者多列值排序.像我们用到的汉语字典,就是一个聚集索引.换句话说就是聚集索引会改变数据库表中数据的存放顺序.非聚集索引不会重新组织表中的数据,而是对 ...
随机推荐
- Python爬虫入门教程 8-100 蜂鸟网图片爬取之三
蜂鸟网图片--啰嗦两句 前几天的教程内容量都比较大,今天写一个相对简单的,爬取的还是蜂鸟,依旧采用aiohttp 希望你喜欢 爬取页面https://tu.fengniao.com/15/ 本篇教程还 ...
- EF架构~mysql数据库无法创建数据模型
回到目录 主要是通过vs2017+mysql.Data+Mysql.data.Entity+ef 来进行开始,当我们选择数据模型生成实体时,可以会出现以下问题: http:// 解决办法: 1.安装 ...
- Spring系列之手写一个SpringMVC
目录 Spring系列之IOC的原理及手动实现 Spring系列之DI的原理及手动实现 Spring系列之AOP的原理及手动实现 Spring系列之手写注解与配置文件的解析 引言 在前面的几个章节中我 ...
- Hadoop大数据挖掘从入门到进阶实战
1.概述 大数据时代,数据的存储与挖掘至关重要.企业在追求高可用性.高扩展性及高容错性的大数据处理平台的同时还希望能够降低成本,而Hadoop为实现这些需求提供了解决方案.面对Hadoop的普及和学习 ...
- Spring Boot 2.x(四):整合Mybatis的四种方式
前言 目前的大环境下,使用Mybatis作为持久层框架还是占了绝大多数的,下面我们来说一下使用Mybatis的几种姿势. 姿势一:零配置注解开发 第一步:引入依赖 首先,我们需要在pom文件中添加依赖 ...
- MySQL/MariaDB系列文章目录
以下是本系列文章的大纲,此页博文完全原创,花费了作者本人的极大心血,如转载,请务必标明原文链接. 如果觉得文章不错,还请帮忙点下"推荐",各位的支持,能激发和鼓励我更大的写作热情. ...
- 从零开始学安全(三十八)●cobaltstrike生成木马抓肉鸡
链接:https://pan.baidu.com/s/1qstCSM9nO95tFGBsnYFYZw 提取码:w6ih 上面是工具 需要java jdk 在1.8.5 以上 实验环境windows ...
- 【转】Android 开发规范(完结版)
摘要 1 前言 2 AS 规范 3 命名规范 4 代码样式规范 5 资源文件规范 6 版本统一规范 7 第三方库规范 8 注释规范 9 测试规范 10 其他的一些规范 1 前言 为了有利于项目维护.增 ...
- mysql删除重复记录,只保留最大ID的记录(非重复也保留)
目前网上搜索的删除重复记录,大部分都是where子查询,本人感觉看上去不美观,故亲自手写了一个,如下: delete from mst_sku using mst_sku,( select dist ...
- 拯救老旧工程,记桥接SpringMVC与Stripes框架
背景: 公司基础设施部门推出了自己的微服务框架(以下简称M),要求所有业务应用都要接入进去,但坑爹的是M只提供了SpringMVC工程的support,对于采用Stripes作为MVC框架的应用并不支 ...