pandas中层次化索引与切片
Pandas层次化索引
1. 创建多层索引
隐式索引:
常见的方式是给dataframe构造函数的index参数传递两个或是多个数组
Series也可以创建多层索引
Series多层索引
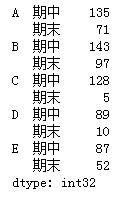
B =Series(np.random.randint(0,150,size=10),index=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"]]))
B
Dataframe多层索引的创建(推荐使用)
多层行索引
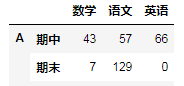
A = DataFrame(np.random.randint(0,150,size=(10,3)),columns=["数学","语文","英语"],
index=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"]]))
A
对象方式多行列索引
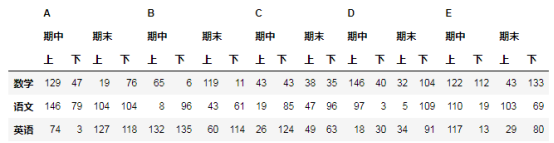
B= DataFrame(np.random.randint(0,150,size=(3,20)),index=["数学","语文","英语"],columns=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"],["上","下"]]))
B
元祖方式创建多层索引
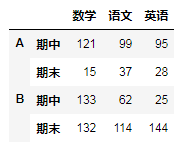
A = DataFrame(np.random.randint(0,150,size=(4,3)),columns=["数学","语文","英语"],
index=pd.MultiIndex.from_tuples([("A","期中"),("A","期末"),("B","期中"),("B","期末")]))
A
数组方式创建多层索引
多层索引的对象的索引和切片
Datafrane多层索引
行索引:
A.loc["A","期中"]
B.loc["A","期中","上"]
列索引:
B["A","期中","上"]
Series多层索引’
行切片以下两种都适用
D["A","期中"]
D.loc["A","期中"]
多层索引的切片
注:对于多层索引的切片必须排好顺序,才能进行切片,使用sort_index()函数对索引进行排序(单层索引可以切片可以不考虑索引的顺序)。
对行进行切片
A.loc["A":"C"]
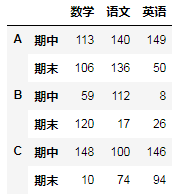
A.iloc[1:3]
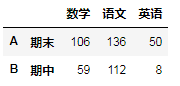
对列进行切片同行切片一样,使用显性索引和隐形索引对数据第二维进行切片
对数据进行排序是,使用sort_values()对数据进行排序
如:A.sort_values(by=["数学"]) #对按数学成绩进行排序
pandas中层次化索引与切片的更多相关文章
- 利用Python进行数据分析(11) pandas基础: 层次化索引
层次化索引 层次化索引指你能在一个数组上拥有多个索引,例如: 有点像Excel里的合并单元格对么? 根据索引选择数据子集 以外层索引的方式选择数据子集: 以内层索引的方式选择数据: 多重索引S ...
- Pandas基本功能之层次化索引及层次化汇总
层次化索引 层次化也就是在一个轴上拥有多个索引级别 Series的层次化索引 data=Series(np.random.randn(10),index=[ ['a','a','a','b','b', ...
- pandas:由列层次化索引延伸的一些思考
1. 删除列层次化索引 用pandas利用df.groupby.agg() 做聚合运算时遇到一个问题:产生了列方向上的两级索引,且需要删除一级索引.具体代码如下: # 每个uesr每天消费金额统计:和 ...
- Pandas中Series和DataFrame的索引
在对Series对象和DataFrame对象进行索引的时候要明确这么一个概念:是使用下标进行索引,还是使用关键字进行索引.比如list进行索引的时候使用的是下标,而dict索引的时候使用的是关键字. ...
- pandas(五)处理缺失数据和层次化索引
pandas用浮点值Nan表示浮点和非浮点数组中的缺失数据.它只是一个便于被检测的标记而已. >>> string_data = Series(['aardvark','artich ...
- Pandas中loc,iloc与直接切片的区别
最近使用pandas,一直搞不清楚其中几种切片方法的区别,今天专门看了一下. 0. 把Series的行index或Dataframe的列名直接当做属性来索引. 如: s.index_name df.c ...
- numpy和pandas的基础索引切片
Numpy的索引切片 索引 In [72]: arr = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]]]) In [73]: arr Out[73]: a ...
- (三)pandas 层次化索引
pandas层次化索引 1. 创建多层行索引 1) 隐式构造 最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组 Series也可以创建多层索引 import numpy ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
随机推荐
- jar包冲突问题
这两天在启动一个新项目的时候,项目一直启动不了,报StackOverFlow; java.util.concurrent.ExecutionException: java.lang.StackOver ...
- JavaWeb案例: 文件下载 基于tomcat8 默认编码为UTF-8
package cn.itcast.download; import javax.servlet.ServletException; import javax.servlet.ServletOutpu ...
- PostgreSQL - invalid input syntax for type timestamp with time zone
问题 在执行以下sql时报错: select COALESCE(null,null,now(),''); 报错如下: SQL Error [22007]: ERROR: invalid input s ...
- linux-ubuntu下调出中文输入法
linux-ubuntu下调出中文输入法 注:此方法我并没有亲身实践过,只是觉得可能会用到,所以保存一下
- 教你如何在 IDEA 远程 Debug ElasticSearch
前提 之前在源码阅读环境搭建文章中写过我遇到的一个问题迟迟没有解决,也一直困扰着我.问题如下,在启动的时候解决掉其他异常和报错后,最后剩下这个错误一直解决不了: [2018-08-01T09:44:2 ...
- 使用 swift3.0高仿新浪微博
项目地址:https://github.com/SummerHH/swift3.0WeBo 使用 swift3.0 高仿微博,目前以实现的功能有,添加访客视图,用户信息授权,首页数据展示(支持正文中连 ...
- fastjson格式化输出内容
引入fastjson <!--fastjson--><dependency> <groupId>com.alibaba</groupId> <ar ...
- 洛谷 P1137 旅行计划
旅行计划 待证明这样dp的正确性. #include <iostream> #include <cstdio> #include <cstring> #includ ...
- Python+selenium整合自动发邮件功能
主要实现的目的是:自动将测试报告以邮件的形式通知相关人员 from HTMLTestRunner import HTMLTestRunner import HTMLTestReport from em ...
- 打印机 Microsoft Print to PDF 所需的驱动程序 Microsoft Print To PDF 未知。登录之前,请与管理员联系,安装驱动程序。
这个问题发生后,我觉得很疑惑,因为服务器上确定没有安装打印机.那么打印机是从哪里来的呢? 通过百度搜索,发现网上的一个帖子解答了我的疑惑.原帖地址:http://blog.chinaunix.net/ ...