pandas:由列层次化索引延伸的一些思考
1. 删除列层次化索引
用pandas利用df.groupby.agg() 做聚合运算时遇到一个问题:产生了列方向上的两级索引,且需要删除一级索引。具体代码如下:
# 每个uesr每天消费金额统计:和、均值、最大值、最小值、消费次数、消费种类、
action_info = student_action.groupby(['outid','date']).agg({'opfare':['sum','mean','max','min'],
'acccode':['count','unique'],}).reset_index()
action_info 表结果如下:

删除列的层次化索引操作如下:
# 列的层次化索引的删除
levels = action_info.columns.levels
labels = action_info.columns.labels
print(levels,labels)
action_info.columns = levels[1][labels[1]]
2. agg()与apply()的区别
以 student_action表为例:
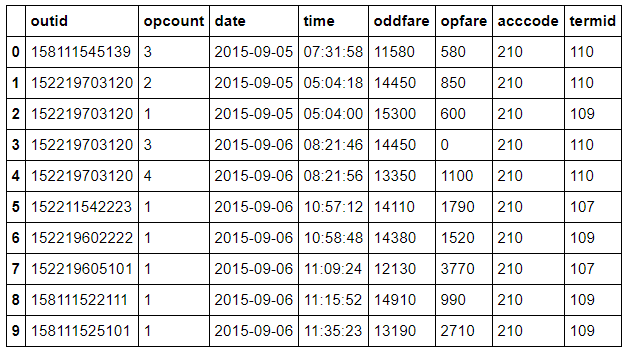
apply()方法:
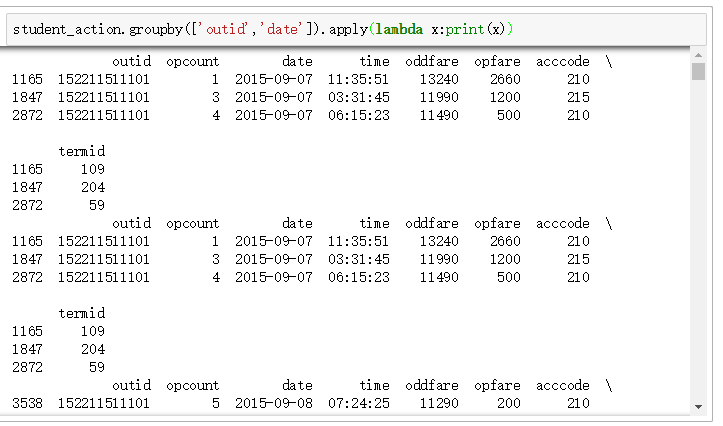
agg()方法:
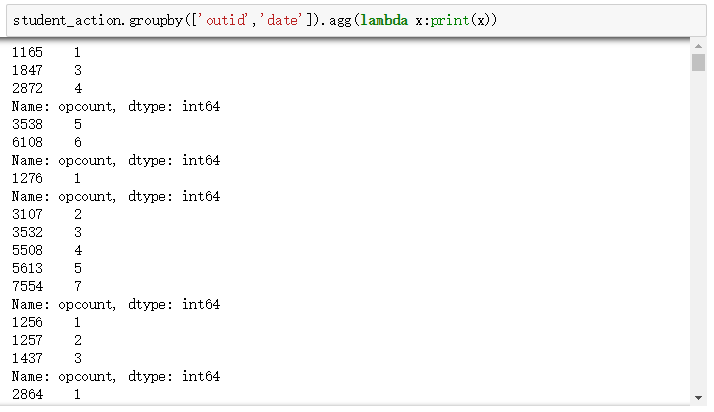
可以看到,apply()可以展示所有维度的数据,而agg()仅可以展示一个维度的数据。
事实上,如果值是一维数组,在利用完特定的函数之后,能做到简化的话,agg就能调用,反之,如果比如自定义的函数是排序,或者是一些些更复杂统计的函数,当然是agg所不能解决的,这时候用apply就可以解决。因为他更一般化,不存在什么简化,什么一维数组,什么标量值。且apply会将当前分组后的数据一起传入,可以返回多维数据。
例子:根据 student_action表,统计每个学生每天最高使用次数的终端、最低使用次数的终端以及最高使用次数终端的使用次数、最低使用次数终端的使用次数。
针对这个例子,有两种方法:
方法一:low到爆 永不使用!!
1. 构造每个用户每天的终端列表,需要one-hot termid
2. 构造groupby.agg()所使用的方法
2.1 列表模糊查找,找到包含'termid_'的字段名
termid_features = [x for i,x in enumerate(student_termid_onehot.columns.tolist()) if x.find('termid_')!=-1]
2.2 构造指定长度,指定元素的列表
sum_methods= ['sum'for x in range(0, len(termid_features))]
2.3 agg_methods=dict(zip(termid_features,sum_methods))
3. 每个学生每天的终端使用次数明细表
find_termid_df = student_termid_onehot.groupby(['outid','date']).agg(agg_methods).reset_index()
4. 找到student_termid_onehot中包含 'termid_'字段元素的最大值对应的字段名
4.1 构造列表保存
4.2 遍历每行数据,构造dict,并过滤value =0.0 的 k-v
4.3 找到每个dict的value值最大的key
max(filtered_statics_dict, key=filtered_statics_dict.get)
方法二:优雅直观
def transmethod(df):
"""
每个用户每天消费记录最大值、最高使用次数的终端、最低使用次数的终端
以及最高使用次数终端的使用次数、最低使用次数终端的使用次数。 df type:
outid opcount date time oddfare opfare acccode \
3538 152211511101 5 2015-09-08 07:24:25 11290 200 210
6108 152211511101 6 2015-09-08 12:09:01 10440 850 210 termid
3538 13
6108 39 """
# 每日最大消费额
maxop = df['opfare'].max()
statics_dict={}
for i in set(df['acccode'].tolist()):
statics_dict[i] = df['acccode'].tolist().count(i)
highest_termid = max(statics_dict, key=statics_dict.get)
lowhest_termid = min(statics_dict, key=statics_dict.get)
highest_termid_freq = statics_dict[highest_termid]
lowhest_termid_freq = statics_dict[lowhest_termid] return maxop,highest_termid,highest_termid_freq,lowhest_termid,lowhest_termid_freq
groupby.apply() 组合使用:
pd.DataFrame(student_action.groupby(['outid','date']).apply(lambda x:transmethod(x)))
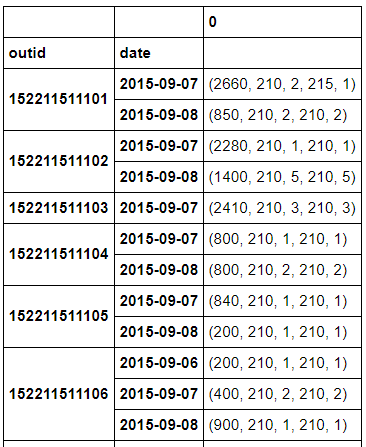
可以发现,apply()方法要比agg()方法灵活的多的多!
3. 总结
- 列层次索引的删除
- 列表的模糊查找方式
- 查找dict的value值最大的key 的方式
- 当做简单的聚合操作(max,min,unique等),可以使用agg(),在做复杂的聚合操作时,一定使用apply()
pandas:由列层次化索引延伸的一些思考的更多相关文章
- Pandas基本功能之层次化索引及层次化汇总
层次化索引 层次化也就是在一个轴上拥有多个索引级别 Series的层次化索引 data=Series(np.random.randn(10),index=[ ['a','a','a','b','b', ...
- pandas(五)处理缺失数据和层次化索引
pandas用浮点值Nan表示浮点和非浮点数组中的缺失数据.它只是一个便于被检测的标记而已. >>> string_data = Series(['aardvark','artich ...
- pandas中层次化索引与切片
Pandas层次化索引 1. 创建多层索引 隐式索引: 常见的方式是给dataframe构造函数的index参数传递两个或是多个数组 Series也可以创建多层索引 Series多层索引 B =Ser ...
- (三)pandas 层次化索引
pandas层次化索引 1. 创建多层行索引 1) 隐式构造 最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组 Series也可以创建多层索引 import numpy ...
- 利用Python进行数据分析(11) pandas基础: 层次化索引
层次化索引 层次化索引指你能在一个数组上拥有多个索引,例如: 有点像Excel里的合并单元格对么? 根据索引选择数据子集 以外层索引的方式选择数据子集: 以内层索引的方式选择数据: 多重索引S ...
- pandas学习(创建多层索引、数据重塑与轴向旋转)
pandas学习(创建多层索引.数据重塑与轴向旋转) 目录 创建多层索引 数据重塑与轴向旋转 创建多层索引 隐式构造 Series 最常见的方法是给DataFrame构造函数的index参数传递两个或 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog) 简介 之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
随机推荐
- 用UITextView加载rtfd文件
用UITextView加载rtfd文件 效果 说明 使用此方法可以实现十分简易的富文本显示效果,包括图文混排等等效果. 源码 // // ViewController.m // Rtfd // // ...
- 铁乐学python_day20_面向对象编程2
面向对象的组合用法 软件重用的重要方式除了继承之外还有另外一种方式,即:组合 组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合. 例:人狗大战,人类绑定上武器来对狗进行攻击: # 定 ...
- terminal 总结
(1) Mac添加命令别名 切换到用户主目录 (2). 编辑或新建.bash_profile文件 (3). 添加别名 alias ll='ls -Alh' (4). 重载该配置文件 source .b ...
- I - Matches Game(异或运算符的使用)
I - Matches Game Description Here is a simple game. In this game, there are several piles of matches ...
- PHP设计模式系列 - 装饰器
什么是装饰器 装饰器模式,对已有对象的部分内容或者功能进行调整,但是不需要修改原始对象结构,可以使用装饰器设 应用场景 设计一个UserInfo类,里面有UserInfo数组,用于存储用户名信息 通过 ...
- using指令都用了这么多年了,其实还真没懂!
在C语言中,我们经常使用#include<stdio.h>指令来导入标准输入输出库,这确实很好理解,相当于把代码复制到当前的程序中. 但在C#语言中,当我们写Console程序时,经常在第 ...
- error info: boost not variable 问题解决
错误信息:error info: boost not variable 解决办法:sudo apt-get install libboost-dev 出现这个问题的原因是我在搭建DOMJudgeOJ平 ...
- Python高级编程和异步IO并发编程
第1章 课程简介介绍如何配置系统的开发环境以及如何加入github私人仓库获取最新源码. 1-1 导学 试看 1-2 开发环境配置 1-3 资源获取方式第2章 python中一切皆对象本章节首先对比静 ...
- P1877 [HAOI2012]音量调节
题目描述 一个吉他手准备参加一场演出.他不喜欢在演出时始终使用同一个音量,所以他决定每一首歌之前他都需要改变一次音量.在演出开始之前,他已经做好一个列表,里面写着每首歌开始之前他想要改变的音量是多少. ...
- HDU 1251 统计难题(字典树入门模板题 很重要)
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)Total Submi ...