pandas中层次化索引与切片
Pandas层次化索引
1. 创建多层索引
隐式索引:
常见的方式是给dataframe构造函数的index参数传递两个或是多个数组
Series也可以创建多层索引
Series多层索引
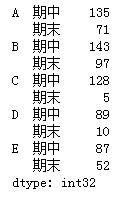
B =Series(np.random.randint(0,150,size=10),index=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"]]))
B
Dataframe多层索引的创建(推荐使用)
多层行索引
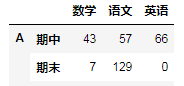
A = DataFrame(np.random.randint(0,150,size=(10,3)),columns=["数学","语文","英语"],
index=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"]]))
A
对象方式多行列索引
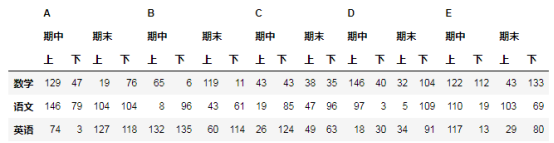
B= DataFrame(np.random.randint(0,150,size=(3,20)),index=["数学","语文","英语"],columns=pd.MultiIndex.from_product([list("ABCDE"),["期中","期末"],["上","下"]]))
B
元祖方式创建多层索引
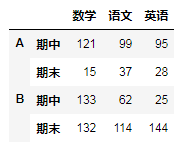
A = DataFrame(np.random.randint(0,150,size=(4,3)),columns=["数学","语文","英语"],
index=pd.MultiIndex.from_tuples([("A","期中"),("A","期末"),("B","期中"),("B","期末")]))
A
数组方式创建多层索引
多层索引的对象的索引和切片
Datafrane多层索引
行索引:
A.loc["A","期中"]
B.loc["A","期中","上"]
列索引:
B["A","期中","上"]
Series多层索引’
行切片以下两种都适用
D["A","期中"]
D.loc["A","期中"]
多层索引的切片
注:对于多层索引的切片必须排好顺序,才能进行切片,使用sort_index()函数对索引进行排序(单层索引可以切片可以不考虑索引的顺序)。
对行进行切片
A.loc["A":"C"]
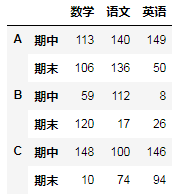
A.iloc[1:3]
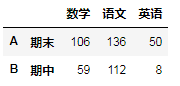
对列进行切片同行切片一样,使用显性索引和隐形索引对数据第二维进行切片
对数据进行排序是,使用sort_values()对数据进行排序
如:A.sort_values(by=["数学"]) #对按数学成绩进行排序
pandas中层次化索引与切片的更多相关文章
- 利用Python进行数据分析(11) pandas基础: 层次化索引
层次化索引 层次化索引指你能在一个数组上拥有多个索引,例如: 有点像Excel里的合并单元格对么? 根据索引选择数据子集 以外层索引的方式选择数据子集: 以内层索引的方式选择数据: 多重索引S ...
- Pandas基本功能之层次化索引及层次化汇总
层次化索引 层次化也就是在一个轴上拥有多个索引级别 Series的层次化索引 data=Series(np.random.randn(10),index=[ ['a','a','a','b','b', ...
- pandas:由列层次化索引延伸的一些思考
1. 删除列层次化索引 用pandas利用df.groupby.agg() 做聚合运算时遇到一个问题:产生了列方向上的两级索引,且需要删除一级索引.具体代码如下: # 每个uesr每天消费金额统计:和 ...
- Pandas中Series和DataFrame的索引
在对Series对象和DataFrame对象进行索引的时候要明确这么一个概念:是使用下标进行索引,还是使用关键字进行索引.比如list进行索引的时候使用的是下标,而dict索引的时候使用的是关键字. ...
- pandas(五)处理缺失数据和层次化索引
pandas用浮点值Nan表示浮点和非浮点数组中的缺失数据.它只是一个便于被检测的标记而已. >>> string_data = Series(['aardvark','artich ...
- Pandas中loc,iloc与直接切片的区别
最近使用pandas,一直搞不清楚其中几种切片方法的区别,今天专门看了一下. 0. 把Series的行index或Dataframe的列名直接当做属性来索引. 如: s.index_name df.c ...
- numpy和pandas的基础索引切片
Numpy的索引切片 索引 In [72]: arr = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]]]) In [73]: arr Out[73]: a ...
- (三)pandas 层次化索引
pandas层次化索引 1. 创建多层行索引 1) 隐式构造 最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组 Series也可以创建多层索引 import numpy ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
随机推荐
- MFS安装
mfs github地址:https://github.com/moosefs/moosefs 一. 准备 1. 名字解释 Mfsmaster 元数据 Metalogger 元数据备份,用于恢复数据( ...
- LuoguP2323 [HNOI2006]公路修建问题 【最小生成树+二分】By cellur925
题目大意:给你\(n\)个点,\(m\)条边,每条边上有两个权值:一级和二级的.选\(n-1\)条边使这个图连通,并至少有\(k\)个一级边,求花费最多的一条边最小值及方案. 最大值最小,肯定会先想到 ...
- plsql developer 执行sql 文件
用 Command Window,执行 @'sql file path' 注意,上面sql文件路径要加单引号
- Django之用户认证—auth模块
用户认知———auth模块 目录: auth模块 User对象 实例 扩展默认的auth_user表 - 创建超级用户 - python3 manager.py createsuperuser - 认 ...
- Net Core 2.0 Redis
Net Core 2.0 Redis配置.封装帮助类RedisHelper及使用实例 https://www.cnblogs.com/oorz/p/9052498.html 本文目录 摘要 Redis ...
- Ubuntu同时忘记用户密码和root密码
在设置密码的时候,用到了小键盘,重启后再次用小键盘输入密码时,发现输入的并不是数字,而是其他符号.所以在设置关键信息的时候,小键盘还是得慎用啊. 解决方案: 在引导界面也就是开机倒计时的时候,按下 e ...
- python 遇到的一些问题和解决方法
安装crypto python3里面这个改成了pycryptodome 1. pip3 install pycryptodome 或者 pip3 install -i https://pypi.do ...
- Hadoop数据管理
本节主要从三方面介绍Hadoop数据管理:分布式文件系统HDFS.分部式数据库HBase和数据仓库工具Hive. 1. HDFS的数据管理 HDFS是分布式计算的存储基石,Hadoop分布式文件系统和 ...
- 洛谷P1081 开车旅行70分
https://www.luogu.org/problem/show?pid=1081 太遗憾了明明写出来了,却把最小值初始值弄小了,从第二个点开始就不可能对了.70分! #include<io ...
- c#的Lambda 表达式
首先看官方的说法: Lambda 表达式是一种可用于创建委托或表达式目录树类型的匿名函数. 通过使用 lambda 表达式,可以写入可作为参数传递或作为函数调用值返回的本地函数. Lambda 表达式 ...