机器学习之K-means算法
前言
以下内容是个人学习之后的感悟,转载请注明出处~
简介
在之前发表的线性回归、逻辑回归、神经网络、SVM支持向量机等算法都是监督学习算法,需要样本进行训练,且
样本的类别是知道的。接下来要介绍的是非监督学习算法,其样本的类别是未知的。非监督学习算法中,比较有代表性
的就是聚类算法。而聚类算法中,又有
- 分割方法:K-means
- 分层次方法:ROCK 、 Chemeleon
- 基于密度的方法:DBSCAN
- 基于网格的方法:STING 、 WaveCluster
以上只是部分算法,在这里就不一一列举了,本文讲解的是K-means算法。
K-means原理
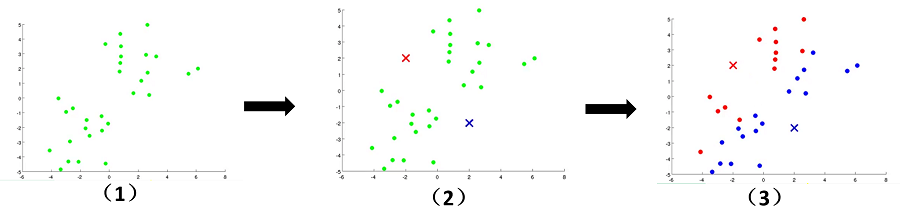
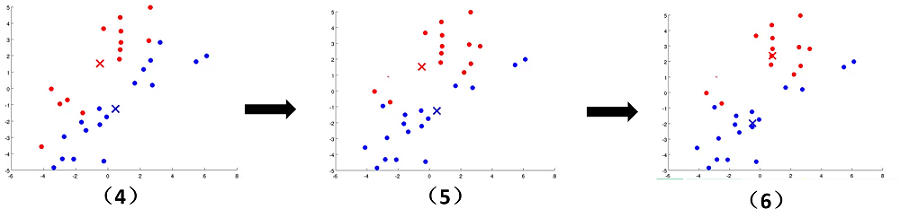
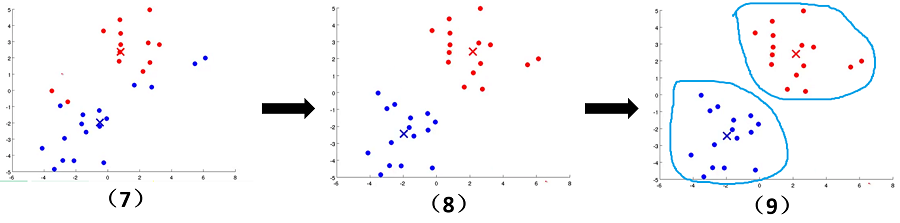
K-means算法原理十分简单,实行起来总共分为以下几个步骤:
- 1、根据要分K类来确定K个初始聚类中心
- 2、将每个样本数据分配给距离最近的聚类中心,形成K个簇
- 3、算出每个簇的均值点作为新的聚类中心
- 4、重复2、3两个步骤,直到聚类中心不再改变
文字往往没有这么直观,接下来看下面的图片,我们可以清晰地看到聚类中心的变化,簇的变化。随着上面步骤的结束,
K-means算法到达了我们想要的效果。
K-means参数优化
1、代价函数
这代价函数很好理解,最小化此代价函数,无非是最小化每个样本到所属类簇中心的距离,此时的分类效果很好。
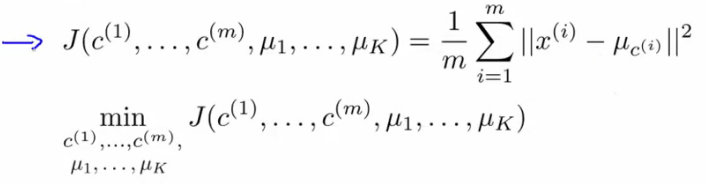
2、选择初始化聚类中心
如果采用随机初始化,很可能导致结果的不理想,下图是两个不同初始化聚类中心的分类效果,明显下面这个分类效果好
多了,所以一次随机初始化,并不能给我们带来理想的效果。
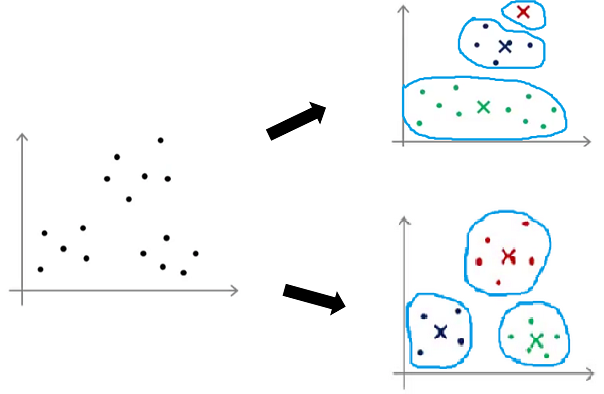
那我们该怎么选择初始聚类中心呢?其实只需多次随机初始化,并运行算法,计算其代价函数,选择代价函数值小的初
始化聚类中心。

3、选择聚类的数目
如何选择聚类的数目?说实话,没有特别标准的答案。一般来说,手动选取比较多,或者采用“肘部法则”(Elbow method),
此法则是计算不同聚类数目下的代价函数,画出曲线,选择这个转折点(像肘部)的K值作为聚类数目,如下面左图所示。但是,现实
中的情况往往是下面右图所示,很难找到“肘部”。
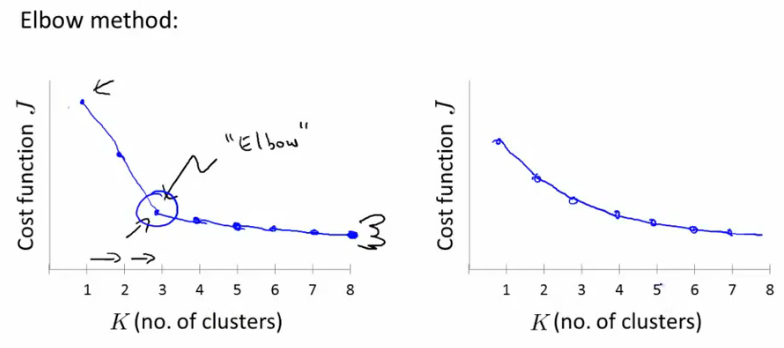
注意:其实很多时候,你要分类的目标会给你相应的信息,需要分几类,此时你完全可以按照目标的要求来。
以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~
机器学习之K-means算法的更多相关文章
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置. 在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解. 而是会出现一下情况: 为了解决这个问题,我们通常的做法是: 我们选取K ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 机器学习实战-k近邻算法
写在开头,打算耐心啃完机器学习实战这本书,所用版本为2013年6月第1版 在P19页的实施kNN算法时,有很多地方不懂,遂仔细研究,记录如下: 字典按值进行排序 首先仔细读完kNN算法之后,了解其是用 ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
随机推荐
- C++学习总结1
一.内存管理 一般new 与 delete 同时出现.假如释放一个对象用 delete p即可.多个对象用delet [ ]p 即:new与delete需要搭配好. C++继承了C的许多函数,mal ...
- 封装PDO操作数据库
<?php class DatabaseHandler { /** * sql语句查询 */ public static function query_data ($dataName,$sql, ...
- MySQL 启动报错:File ./mysql-bin.index not found (Errcode: 13)
Linux下安装初始化完MySQL数据库之后,使用mysqld_safe启动mysql数据库,如下发现,启动失败 [root@SVNServer bin]# ./mysqld_safe –user=m ...
- C++输入一行字符串的一点小结
C++输入一行字符串的一点小结 原文链接: http://www.wutianqi.com/?p=1181 大家在学习C++编程时.一般在输入方面都是使用的cin. 而cin是使用空白(空格,制表符和 ...
- 循序渐进学Python2变量与输入
新建一个test.py文件,右键选择“Edit with IDLE”,编辑完成后,Ctrl+S保存,然后按下F5就可以执行代码了. 注:IDLE是Python官方提供的一个IDE工具. 目录 [隐藏] ...
- new和delete的基本用法
前言 new和delete是C++中用来动态管理内存分配的运算符,其用法较为灵活.如果你对它们的几种不同用法感到困惑,混淆,那么接着看下去吧. 功能一:动态管理单变量/对象空间 下面例子使用new为单 ...
- LeetCode(82)题解: Remove Duplicates from Sorted List II
https://leetcode.com/problems/remove-duplicates-from-sorted-list-ii/ 题目: Given a sorted linked list, ...
- 在html中显示Flash的代码
<object classid="clsid:D27CDB6E-AE6D-11cf-96B8-444553540000" codebase="http://down ...
- LeastRecentlyUsed
LeastRecentlyUsed Operating Systems http://www.cs.jhu.edu/~yairamir/cs418/os6/sld001.htm Cache repla ...
- bc - An arbitrary precision calculator language
bc(1) General Commands Manual bc(1) NAME bc - An arbitrary precision calculator language SYNTAX bc [ ...