PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集
目标站点分析
今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方法不太一样,对它的抓取需要抓取后台传来的JSON数据,
先来看一下今日头条的源码结构:我们抓取文章的标题,详情页的图片链接试一下:

看到上面的源码了吧,抓取下来没有用,那么我看下它的后台数据:‘
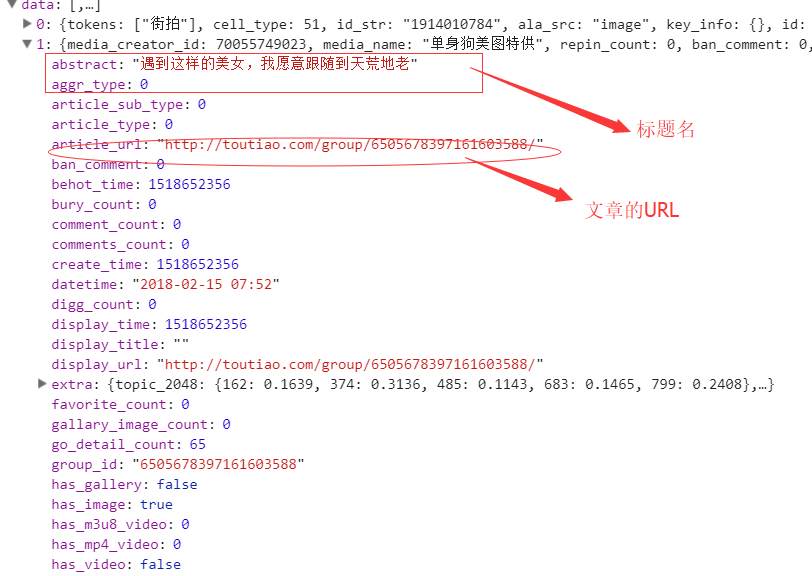
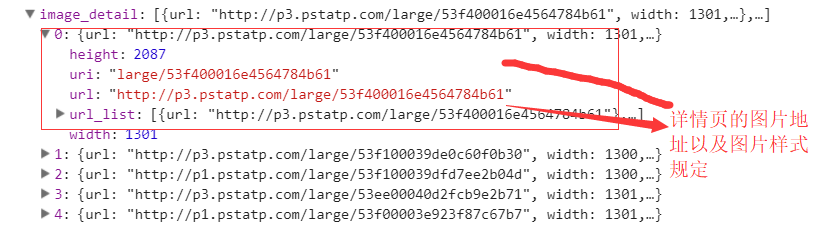
所有的数据都在后台的JSON展示中,所以我们需要通过接口对数据进行抓取


提取网页JSON数据
执行函数结果,如果你想大量抓取记得开启多进程并且存入数据库:

看下结果:

总结一下:网上好多抓取今日头条的案例都是先抓去指定主页,获取文章的URL再通过详情页,接着在详情页上抓取,但是现在的今日头条的网站是这样的,在主页的接口数据中就带有详情页的数据,通过点击跳转携带数据的方式将数据传给详情页的页面模板,这样开发起来方便节省了不少时间并且减少代码量
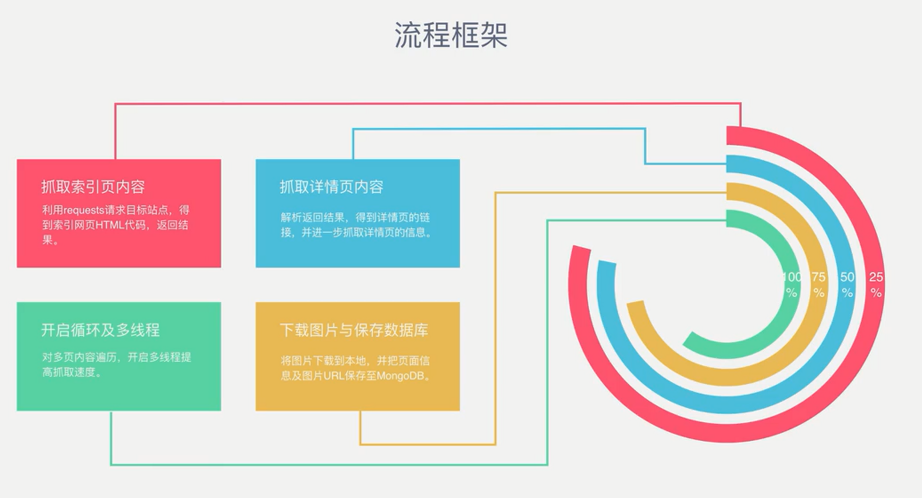
流程框架
爬虫实战
spider详情页
import json
import os
from hashlib import md5
from json import JSONDecodeError import pymongo
import re
from urllib.parse import urlencode
from multiprocessing import Pool import requests
from bs4 import BeautifulSoup
from config import * client = pymongo.MongoClient(MONOGO_URL, connect=False)
db = client[MONOGO_DB] def get_page_index(offset,keyword): #请求首页页面html
data = {
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 3,
'from': 'search_tab'
}
url ='https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except Exception:
print('请求首页出错')
return None def parse_page_index(html): #解析首页获得的html
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url') def get_page_detalil(url): #请求详情页面html
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'} try:
response = requests.get(url,headers = headers)
if response.status_code == 200:
return response.text
return None
except Exception:
print('请求详情页出错',url)
return None def parse_page_detail(html,url): #解析每个详情页内容
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
image_pattern = re.compile('gallery: JSON.parse\("(.*)"\)',re.S)
result = re.search(image_pattern,html)
if result:
try:
data = json.loads(result.group(1).replace('\\',''))
if data and 'sub_images' in data.keys():
sub_images = data.get("sub_images")
images = [item.get('url') for item in sub_images]
for image in images:download_image(image)
return {
'title':title,
'url':url,
'images':images
}
except JSONDecodeError:
pass def save_to_mongo(result): #把信息存储导Mongodb
try:
if db[MONOGO_TABLE].insert(result):
print('存储成功',result)
return False
return True
except TypeError:
pass def download_image(url): #查看图片链接是否正常获取
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
print('正在下载:',url)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
save_image(response.content)
return None
except ConnectionError:
print('请求图片出错', url)
return None def save_image(content): #下载图片到指定位置 #file_path = '{}/{}.{}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
file_path = '{}/{}.{}'.format('/Users/darwin/Desktop/aaa',md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close() def main(offset):
html = get_page_index(offset,KEYWORD)
for url in parse_page_index(html):
html = get_page_detalil(url)
if html:
result = parse_page_detail(html,url)
save_to_mongo(result) if __name__ == '__main__':
groups = [x*20 for x in range(GROUP_START,GROUP_END+1)]
pool = Pool() pool.map(main,groups)config配置页
MONOGO_URL='localhost'
MONOGO_DB = 'toutiao'
MONOGO_TABLE = 'toutiao' GROUP_START=1
GROUP_END=2 KEYWORD='街拍'
PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)的更多相关文章
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
- 【Python爬虫案例学习】分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. from urllib.parse import urlencode from requests.excep ...
- Python爬虫系列-分析Ajax请求并抓取今日头条街拍图片
1.抓取索引页内容 利用requests请求目标站点,得到索引网页HTML代码,返回结果. 2.抓取详情页内容 解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 3.下载图片与保存数据库 将 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
随机推荐
- 为什么要点两下才能删除一个li节点 原来是空白节点作怪
奇怪吧,下面的代码居然要点两次button才能删除一个li节点: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional// ...
- Java内存泄漏及分析
对于内存泄漏,首先想到的是C语言,其实不然,java中也有各种的内存泄漏.对于java程序员,在虚拟即中,不需要为每一个新建对象去delete/free内存,不容易出现内存泄漏.但是,正 是由于这种机 ...
- Android开发第一讲之目录结构和程序的执行流程
1.如何在eclipse当中,修改字体 下面的这种办法,可以更改xml的字体 窗口--首选项--常规--外观--颜色和字体--基本--文本字体--编辑Window --> Preferences ...
- JQuery EasyUI DataGrid动态合并单元格
/** * EasyUI DataGrid根据字段动态合并单元格 * @param fldList 要合并table的id * @param fldList ...
- (二)关于jQuery
jQuery是一个快速.简洁的JavaScript框架,是继Prototype之后又一个优秀的JavaScript代码库(或JavaScript框架).jQuery设计的宗旨是“write Less, ...
- hdu4857 & BestCoder Round #1 逃生(拓扑逆排序+优先队列)
题目链接:http://acm.hdu.edu.cn/showproblem.php? pid=4857 ----------------------------------------------- ...
- 对于一个字符串,请设计一个高效算法,找到第一次重复出现的字符。 给定一个字符串(不一定全为字母)A及它的长度n。请返回第一个重复出现的字符。保证字符串中有重复字符,字符串的长度小于等于500。
// 第一种方法 // ConsoleApplication10.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include < ...
- Appium python Uiautomator2 多进程问题
appium更新uiautomator后可以获取tost了,大家都尝试,课程中也讲解了,但是这些跑的时候都在单机上,当我们多机并发的时候会出现一个端口问题,因为我们appium最后会调用uiautom ...
- scrollview gridview
package com.fangdamai.salewinner.ui.customer; import android.content.Context;import android.content. ...
- 异常: 2 字节的 UTF-8 序列的字节 2 无效。
具体异常: 十二月 08, 2015 7:16:55 下午 org.apache.catalina.core.StandardWrapperValve invoke 严重: Servlet.servi ...