爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容
所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地。我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程序获取的则是程序源代码。我们通过使用Python中urllib2来获取网页的URL资源,最简单方法就是调用urlopen 方法。
# coding : utf-8
import urllib2
import urllib url = 'http://www.baidu.com'
res = urllib2.urlopen(url)
print res.read()
HTTP是基于请求和应答机制—客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求,通过调用urlopen来传入Request对象,将返回一个相关请求response对象,这个应答对象如同一个文件对象,所以我们可以在Response对象中调用read()方法来读取。
# coding : utf-8
import urllib2
import urllib url = 'http://www.baidu.com'
request = urllib2.Request(url)
res = urllib2.urlopen(request)
print res.read()
在HTTP请求时,我们还可以发送data表单数据。一般的HTML表单,data需要编码成标准形成,然后作为data参数传到Request对象。而相应的编码工作就不能用urllib2来完成了,而是我们urllib组件。
import urllib
import urllib2 url = 'http://www.someserver.com/register.cgi' values = {'name' : 'BaiYiShaoNian',
'localtion' : 'ChongQing',
'language' : 'Python',
} data = urllib.urlencode(values)
req = urllib2.Request(url,data)
response = urllib2.urlopen(req)
the_page = response.read() print the_page
但是我有一个疑问:就是这一份代码并不能运行,我还不知道传入数据表单的作用是什么,或者我们在抓cnblogs页面时,传入登录的信息,是不是我们就可以登录博客园了啊,所以在这里请教一下大牛,先感谢了。
通过正则表达式来获取网页部分信息
正则表达式,又称为正则表示法、常规表示法。正则表达式使用单个字符串来描述、匹配一系列符号某个句法规则的字符串。通俗的说,正则表达式就是在程序中定义了字符串的某种规则,然后我们在网页源代码中找出符合这种规则的所有代码语句,不符合的就淘汰不要。
关于正则表达式的很多具体用法,我后面会边学边为大家讲解的,这里先略过。
我们可以通过Python爬虫来获取以下网页中新闻标题和新闻的ID。
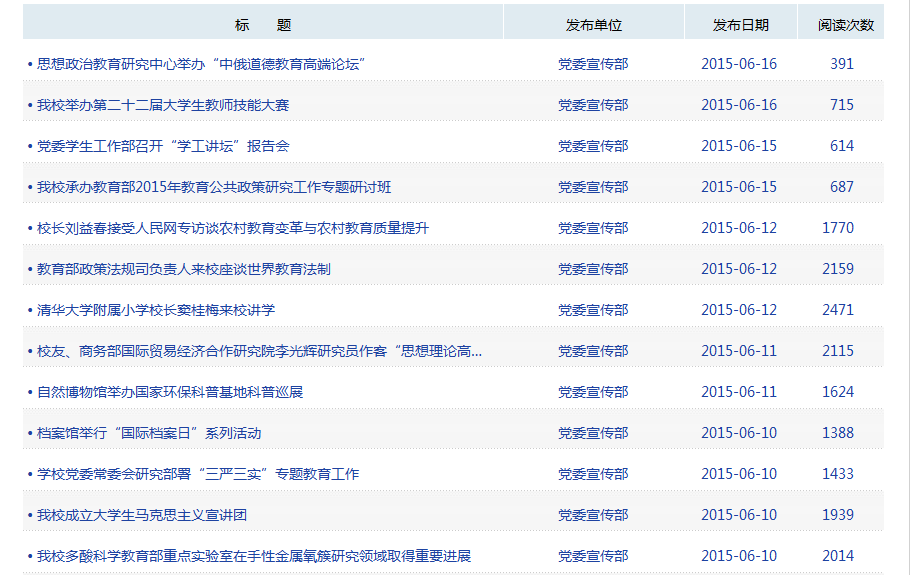
# -*- coding: utf-8 -*-
import urllib2
import re # 1.获取访问页面的HMTL
url = "http://www.nenu.edu.cn/newslist.php?cid=1" response = urllib2.urlopen(url)
html = response.read()
# 2.根据正则表达式抓取特定内容
r = re.compile(r'<a href="intramural/content/news/(?P<ID>.{5}).*" target="_blank">(?P<Title>.+)</a>')
news = r.findall(html)
for i in range(len(news)):
ID = news[i][0]
title = news[i][1]
# data = data.decode('utf-8')
# title = title.decode('utf-8')
print title + " " + ID + " "
我们运行这一份代码看看结果是什么样的,是否已经成功获取。
爬虫学习一系列:urllib2抓取网页内容的更多相关文章
- python爬虫学习:分布式抓取
前面的文章都是基于在单机操作,正常情况下,一台机器无论配置多么高,线程开得再多,也总会有一个上限,或者说成本过于巨大.因此,本文将提及分布式的爬虫,让爬虫的效率提高得更快. 构建分布式爬虫首先需要有多 ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- python爬虫学习(1)__抓取煎蛋图片
#coding=utf-8 #python_demo 爬取煎蛋妹子图在本地文件夹 import requests import threading import time import os from ...
- 通过urllib2抓取网页内容(1)
一.urllib2发送请求 import urllib2 url = 'http://www.baidu.com' req = urllib2.Request(url) response = urll ...
- python爬虫学习(2)__抓取糗百段子,与存入mysql数据库
import pymysql import requests from bs4 import BeautifulSoup#pymysql链接数据库 conn=pymysql.connect(host= ...
- Python爬虫学习笔记之抓取猫眼的排行榜
代码: import json import requests from requests.exceptions import RequestException import re import ti ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
随机推荐
- DB2数据库报 [SQL0805N Package "NULLID.SQLLD003" was not found.]
解决办法: cd /home/db2inst1/sqllib/bnddb2 bind @db2cli.lst blocking all grant public sqlerror continue C ...
- [Math Review] Linear Algebra for Singular Value Decomposition (SVD)
Matrix and Determinant Let C be an M × N matrix with real-valued entries, i.e. C={cij}mxn Determinan ...
- Using Blocks in iOS 4: Designing with Blocks
In the first part of this series, we learned how to declare and call basic Objective-C blocks. The m ...
- java.sql.Timestamp类型
如果想向数据库中插入日期时间的话,可以用java.sql.Timestamp类 一个与 java.util.Date类有关的瘦包装器 (thin wrapper),它允许 JDBC API 将该类标识 ...
- Poj2826 An Easy Problem
呵呵哒.WA了无数次,一开始想的办法最终发现都有缺陷.首先需要知道: 1)线段不相交,一定面积为0 2)有一条线段与X轴平行,面积一定为0 3)线段相交,但是能接水的三角形上面线段把下面的线段完全覆盖 ...
- 分治法寻找第k大的数
利用快速排序的思想·去做 #include<iostream>using namespace std;int FindKthMax(int*list, int left, int righ ...
- 搭建k8s集群的手顺
https://www.cnblogs.com/netsa/category/1137187.html
- Tomcat Manager用户名和密码
在浏览器输入http://localhost:8080/,打开Tomcat自带的默认主页面,右侧有“administration”“documentation”等模块.选择“administratio ...
- linux设备驱动程序之并发和竞态(二)
事实上这blog都是阅读ldd3时的一些总结,巩固自己的学习.也方便后期的使用.大家也能够直接阅读ldd3原文. 锁陷阱 所谓的锁陷阱就是防止死锁. 不明白的规则: ...
- 数据结构基础-Hash Table详解(转)
理解Hash 哈希表(hash table)是从一个集合A到另一个集合B的映射(mapping). 映射是一种对应关系,而且集合A的某个元素只能对应集合B中的一个元素.但反过来,集合B中的一个元素可能 ...