背景
平台HDFS数据存储规则是按照“数据集/天目录/小时目录/若干文件”进行的,其中数据集是依据产品线或业务划分的。
用户分析数据时,可能需要处理以下五个场景:
(一)分析指定数据集、指定日期、指定小时、指定文件的数据;
(二)分析指定数据集、指定日期、指定小时的数据;
(三)分析指定数据集、指定日期的数据(24个小时目录的数据);
(四)分析多个数据集、多个日期或多个小时的数据;
(五)多种存储格式(textfile、sequencefile、rcfile等)。
目前我们平台提供给用户的分析工具为PySpark(Spark、Spark SQL、Python),本文讨论的就是使用PySpark如果应对上述场景。
示例
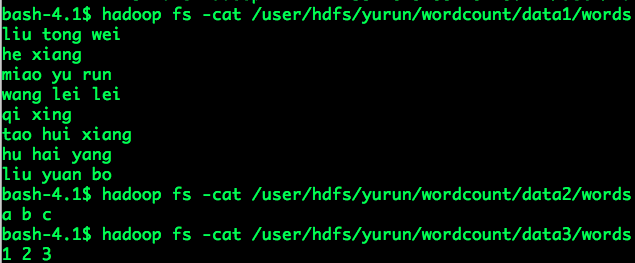
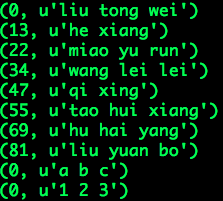
假设HDFS存在一个wordcount目录,包含三个子目录:data1、data2、data3,
这三个子目录下均含有一个文本文件words,各自的内容如下:
解决方案
这里我们暂时只考虑文本文件。
1. 分析指定数据集、指定日期、指定小时、指定文件的数据;
2. 分析指定数据集、指定日期、指定小时的数据;
SparkContext textFile默认情况下可以接收一个文本文件路径或者仅仅包含文本文件的目录,使用该方法可以应对场景(一)、(二)。
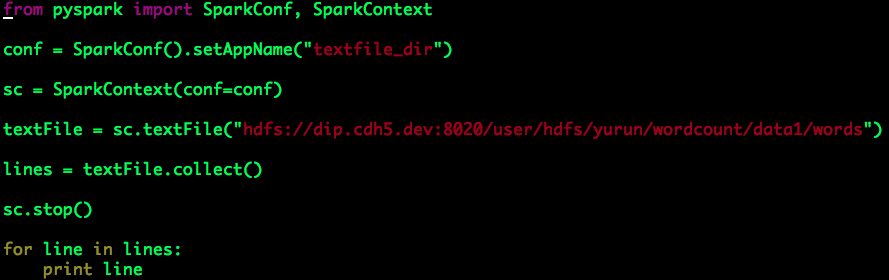
(1)分析指定文本文件的数据,这里我们假设待分析的数据为“/user/hdfs/yurun/wordcount/data1/words”:
可以得到如下输出:
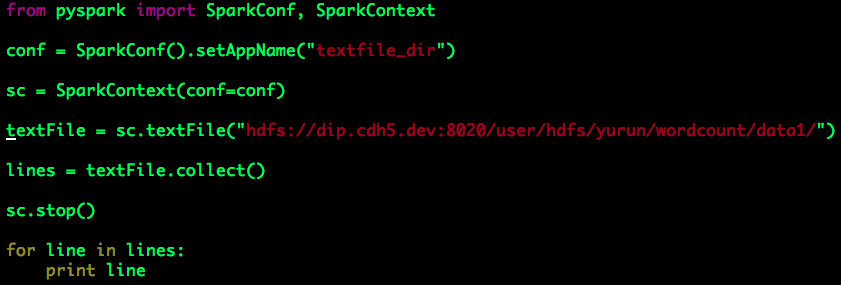
(2)分析指定目录的数据,且该目录仅包含文本文件,这里我们假设待分析的数据为“/user/hdfs/yurun/wordcount/data1/”:
运行上述代码会得到与(1)相同的结果。
3. 分析指定数据集、指定日期的数据(24个小时目录的数据);
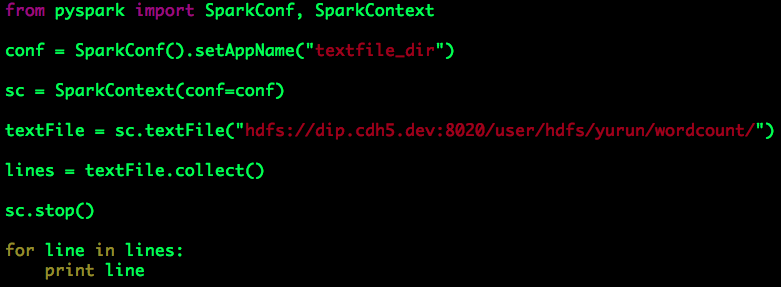
针对我们的示例,也就是需要“递归”分析wordcount目录下三个子目录data1、data2、data3中的数据。我们尝试将上面示例中的输入路径修改为“/user/hdfs/yurun/wordcount/”,
运行上述代码会出现异常:
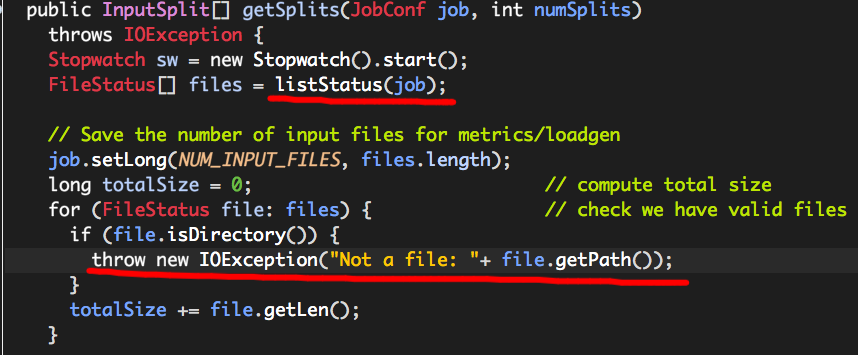
根据1、2、3中的示例,如果我们指定的输入路径是一个目录,而这个目录中存在子目录就会出现上述异常。究其原因,实际上与FileInputFormat(org.apache.hadoop.mapred.FileInputFormat)的“某个”配置属性值有关。
注意:源码中有两个模块中都包含这个类,
这里使用的是模块hadoop-mapreduce-client中的类。
根据抛出的异常信息,我们可以在FileInputFormat的源码中找到如下代码块:
可以看出,如果files中的任何一个FileStatus实例(由file表示)为目录,便会引发“Not a file”的异常,而files来源于方法listStatus,
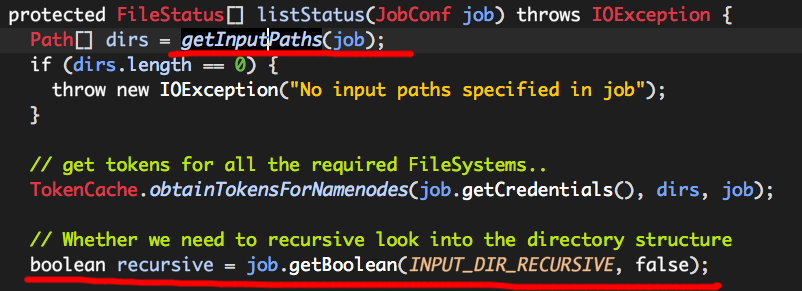
我们需要注意两个很重要的变量:
(1)dirs
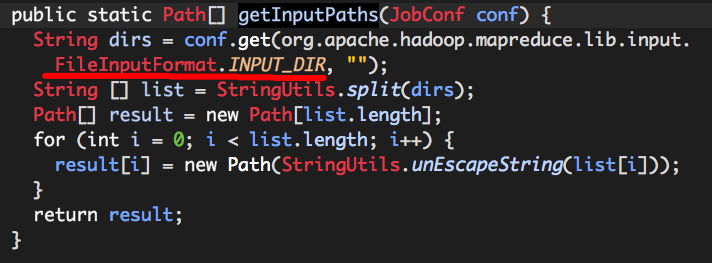
dirs为我们指定的输入文件或目录,它是由getInputPaths计算而来的,
可以看出,我们通过SparkContext textfile指定的输入路径实际是保存在Configuration中的,以属性FileInputFormat.INPUT_DIR(mapreduce.input.fileinputformat.inputdir)表示,从代码逻辑可知,它的值可以为多个以“,”分隔的字符串。
与就是说,理论上我们是可以指定多个输入文件或目录的(SparkContext textfile仅支持单个文件路径或目录路径)。
(2)recursive
如果我们指定的是一个目录路径,recursive表示着是否允许在后续的切片计算过程中“递归”处理该路径中的子目录,它的值由属性INPUT_DIR_RECURSIVE(mapreduce.input.fileinputformat.input.dir.recursive)决定,默认值为false。
也就是说,默认情况下,FileInputFormat是不会以“递归”的形式处理指定目录中的子目录的,这也是引发上述异常的根本原因。
如果我们需要处理“递归”目录的场景,可以采用下述两个方法:
(1)在Hadoop的配置文件mapred-site.xml中添加属性mapreduce.input.fileinputformat.input.dir.recursive,并指定值为true;
仅仅需要在Spark Client(提交Spark Application的机器)相关机器上操作即可,不需要修改Hadoop集群配置。
修改配置文件后,再次提交上述程序,即可正常执行。
(2)使用hadoopRDD;
这种方式不需要修改配置文件,而是在代码中通过Hadoop Configuration(hadoopConf)直接指定相关属性:
mapreduce.input.fileinputformat.inputdir:hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/;
mapreduce.input.fileinputformat.input.dir.recursive:true;
此外还需要注意hadoopRDD的几个参数:
inputFormatClass:org.apache.hadoop.mapred.TextInputFormat
keyClass:org.apache.hadoop.io.LongWritable
valueClass:org.apache.hadoop.io.Text
这仅仅是针对textfile设置的参数值,对于其它的数据格式会有所不同,后面会讨论。
使用hadoopRDD的运行结果会有所不同:
这是因为SparkContext textfile省略了TextInputFormat中的“key”,它表示每一行文本在各自文件中的起始偏移量。
4. 分析多个数据集、多个日期或多个小时的数据;
这种场景要求我们能够指定多个目录或文件,其中还可能需要“递归”处理子目录,SparkContext textfile只能接收一个目录或文件,此时我们只能使用hadoopRDD。
前面提到过,“mapreduce.input.fileinputformat.inputdir”可以以“,”分隔的形式接收多个目录或文件路径。假设我们需要分析的数据为“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data1”、“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data2”、“hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/wordcount/data3/words”,代码示例如下:
运行结果同上。
5. 多种存储格式;
1-4的讨论仅仅局限于textfile,textfile易于人的阅读和分析,但存储开销很大,即使采用相应的压缩,效果也并是很理想。在实践中我们发现rcfile采用列式压缩效果显著,因此也需要考虑如何使得PySpark支持rcfile。
为什么这个地方要有专门的“考虑”?
简单来讲,Hadoop是使用Java构建的,Spark是使用Scala构建的,而我们现在使用的开发语言为Python,这就带来一个问题:Java/Scala中的数据类型如何转换为相应的Python数据类型?
如TextInputFormat返回的键值对类型为LongWritable、Text,可以被“自动”转换为Python中的int、str(基本数据类型均可以被“自动”转换),RCFileInputFormat返回的键值对类型为LongWritable、BytesRefArrayWritable,BytesRefArrayWritable不是基本数据类型,它应该如何被转换呢?
我们查看SparkContext hadoopRDD的文档可知,
keyConverter、valueConverter就是用来负责完成键值类型的转换的。
假设我们有一个RCFile格式的文件:
RCFileInputFormat的键类型为LongWritable,可以自动被转换;
RCFileInputFormat的值类型为BytesRefArrayWritable,无法被自动转换,需要一个Converter,这里我们把每一个BytesRefArrayWritable实例转换为一个Text实例,其中三列数据以空格分隔。
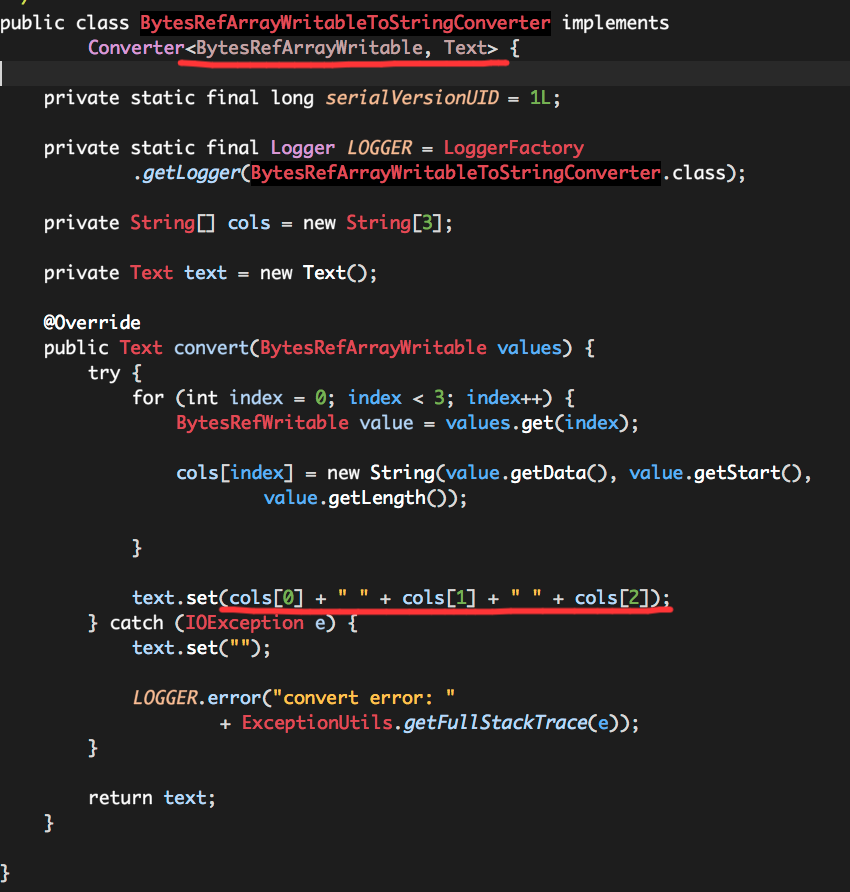
我们将Converter定义为BytesRefArrayWritableToStringConverter(com.sina.dip.spark.converter.BytesRefArrayWritableToStringConverter),代码如下:
其实Converter的逻辑非常简单,就是将BytesRefArrayWritable中的数据提取、转换为基本数据类型Text。
将上述代码编译打包为converter.jar。
PySpark代码如下:
重点注意几个参数值:
mapreduce.input.fileinputformat.inputdir:hdfs://dip.cdh5.dev:8020/user/hdfs/yurun/rcfile/data
inputFormatClass:org.apache.hadoop.hive.ql.io.RCFileInputFormat
keyClass:org.apache.hadoop.io.LongWritable
valueClass:org.apache.hadoop.io.Text
valueConverter:com.sina.dip.spark.converter.BytesRefArrayWritableToStringConverter
执行命令:
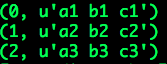
结果输出:
三行数据,每行数据均为字符串输出,且以空格分隔,可见数据得到正常转换。
通过上述方式,我们可以通过SparkContext hadoopRDD支持多种数据格式数据的分析。
总结
本文通过五种常见应用场景的讨论,可以得出使用PySpark可以支持灵活的数据输入路径,还可以根据需求扩展支持多种数据格式。
- 【异常】hbase启动后hdfs文件权限目录不一致,导致Phoenix无法删除表结构
1 异常信息 Received error when attempting to archive files ([class org.apache.hadoop.hbase.backup.HFileA ...
- HDFS文件操作
hadoop装好后,文件系统中没有任何目录与文件 1. 创建文件夹 hadoop fs -mkdir -p /hkx/learn 参数-p表示递归创建文件夹 2. 浏览文件 hadoop fs -ls ...
- hive1.1.0建立外部表关联HDFS文件
0. 说明 已经安装好Hadoop和hive环境,hive把元数据存储在mysql数据库.这里仅讨论外部表和HDFS的关联,并且删掉外部表之后,对HDFS上的文件没有影响. 1. 在HDFS创建分区, ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- HDFS文件的基本操作
HDFS文件的基本操作: package wjn; import java.io.BufferedInputStream; import java.io.BufferedReader; import ...
- HDFS文件和HIVE表的一些操作
1. hadoop fs -ls 可以查看HDFS文件 后面不加目录参数的话,默认当前用户的目录./user/当前用户 $ hadoop fs -ls 16/05/19 10:40:10 WARN ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- java基础八 [序列化和文件的输入/输出](阅读Head First Java记录)
对象具有状态和行为两种属性.行为存在类中的方法中,想要保存状态有多种方法,这里介绍两种: 一是保存整个当前对象本身(通过序列化):一是将对象中各个状态值保存到文件中(这种方式可以给其他非JAVA程序用 ...
随机推荐
- 常用JS验证和函数
下面是我常用一些JS验证和函数,有一些验证我直接写到了对象的属性里面了,可以直接通过对象.方法来调用 //浮点数除法运算 function fdiv(a, b, n) { if (n == undef ...
- 基于SSM框架的简易的分页功能——包含maven项目的搭建
新人第一次发帖,有什么不对的地方请多多指教~~ 分页这个功能经常会被使用到,我之前学习的时候找了很多资源,可都看不懂(笨死算了),最后还是在朋友帮助下做出了这个分页.我现在把我所能想到的知识 做了一个 ...
- HDU 4089 Activation(概率DP)(转)
11年北京现场赛的题目.概率DP. 公式化简起来比较困难....而且就算结果做出来了,没有考虑特殊情况照样会WA到死的.... 去参加区域赛一定要考虑到各种情况. 像概率dp,公式推出来就很容易写 ...
- 九度OJ 1205 N阶楼梯上楼问题 -- 动态规划(递推求解)
题目地址:http://ac.jobdu.com/problem.php?pid=1205 题目描述: N阶楼梯上楼问题:一次可以走两阶或一阶,问有多少种上楼方式.(要求采用非递归) 输入: 输入包括 ...
- Mantle 简单教程
Mantle可以很方便的去书写一个模型层的代码. 使用它可以很方便的去反序列化JSON或者序列化为JSON(需要在MTLModel子类中实现<MTLJSONSerializing>协议) ...
- varnish 4.0编译安装小记
varnish 4.0 编译问题 centos-6.5 x86环境 装varnish遇到几个错误要先安装python-docutils然后提示error1,于是安装:libedit-devel然后提示 ...
- js实现小数点后保留N位并可以四舍五入——js对float数据的处理
曾经遇到的两次的问题,关于前台接受后台传过来的float数据,一显示就是老长的小数点后缀,很烦人,后来想着用js把其进行四舍五入处理下,经网上查找,一哥们的代码如下:(很好用,感谢下!) functi ...
- (转载)delphi中获取汉字的拼音首字母
delphi中获取汉字的拼音首字母1.py: array[216..247] of string = ({216}'CJWGNSPGCGNESYPB' + 'TYYZDXYKYGTDJNMJ' + ' ...
- 10g和11g,优化器对外连接的处理对比
我反省,今天面试有个问题没有说清楚.我给出的结论(而且这个结论我验证过)是:不要使用不必要的外连接,举了下面这个例子却没有说清楚.虽然最近感冒,状态不是很好,但最擅长的东西都没有表达清楚,泪流满面啊: ...
- sublime 编译程序出错控制台打印PATH的解决办法
找到sublime的安装目录 搜索 exec.py 打开找到这几句话193行左右或者搜索关键词path if "PATH" in merged_env: self.debug_te ...