支持向量机原理(四)SMO算法原理
在SVM的前三篇里,我们优化的目标函数最终都是一个关于$\alpha$向量的函数。而怎么极小化这个函数,求出对应的$\alpha$向量,进而求出分离超平面我们没有讲。本篇就对优化这个关于$\alpha$向量的函数的SMO算法做一个总结。
1. 回顾SVM优化目标函数
我们首先回顾下我们的优化目标函数:$$ \underbrace{ min }_{\alpha} \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jK(x_i,x_j) - \sum\limits_{i=1}^{m}\alpha_i $$ $$ s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0 $$ $$0 \leq \alpha_i \leq C$$
我们的解要满足的KKT条件的对偶互补条件为:$$\alpha_{i}^{*}(y_i(w^{*} \bullet \phi(x_i) + b^{*}) - 1) = 0$$
根据这个KKT条件的对偶互补条件,我们有:$$\alpha_{i}^{*} = 0 \Rightarrow y_i(w^{*} \bullet \phi(x_i) + b) \geq 1 $$ $$ 0 \leq \alpha_{i}^{*} \leq C \Rightarrow y_i(w^{*} \bullet \phi(x_i) + b) = 1 $$ $$\alpha_{i}^{*}= C \Rightarrow y_i(w^{*} \bullet \phi(x_i) + b) \leq 1$$
由于$w^{*} = \sum\limits_{j=1}^{m}\alpha_j^{*}y_j\phi(x_j)$,我们令$g(x) = w^{*} \bullet \phi(x) + b =\sum\limits_{j=1}^{m}\alpha_j^{*}y_jK(x, x_j)+ b^{*}$,则有: $$\alpha_{i}^{*} = 0 \Rightarrow y_ig(x_i) \geq 1 $$ $$ 0 \leq \alpha_{i}^{*} \leq C \Rightarrow y_ig(x_i) = 1 $$ $$\alpha_{i}^{*}= C \Rightarrow y_ig(x_i) \leq 1$$
2. SMO算法的基本思想
上面这个优化式子比较复杂,里面有m个变量组成的向量$\alpha$需要在目标函数极小化的时候求出。直接优化时很难的。SMO算法则采用了一种启发式的方法。它每次只优化两个变量,将其他的变量都视为常数。由于$\sum\limits_{i=1}^{m}\alpha_iy_i = 0$.假如将$\alpha_3, \alpha_4, ..., \alpha_m$ 固定,那么$\alpha_1, \alpha_2$之间的关系也确定了。这样SMO算法将一个复杂的优化算法转化为一个比较简单的两变量优化问题。
为了后面表示方便,我们定义$K_{ij} = \phi(x_i) \bullet \phi(x_j)$
由于$\alpha_3, \alpha_4, ..., \alpha_m$都成了常量,所有的常量我们都从目标函数去除,这样我们上一节的目标优化函数变成下式:$$\;\underbrace{ min }_{\alpha_1, \alpha_1} \frac{1}{2}K_{11}\alpha_1^2 + \frac{1}{2}K_{22}\alpha_2^2 +y_1y_2K_{12}\alpha_1 \alpha_2 -(\alpha_1 + \alpha_2) +y_1\alpha_1\sum\limits_{i=3}^{m}y_i\alpha_iK_{i1} + y_2\alpha_2\sum\limits_{i=3}^{m}y_i\alpha_iK_{i2}$$ $$s.t. \;\;\alpha_1y_1 + \alpha_2y_2 = -\sum\limits_{i=3}^{m}y_i\alpha_i = \varsigma $$ $$0 \leq \alpha_i \leq C \;\; i =1,2$$
3. SMO算法目标函数的优化
为了求解上面含有这两个变量的目标优化问题,我们首先分析约束条件,所有的$\alpha_1, \alpha_2$都要满足约束条件,然后在约束条件下求最小。
根据上面的约束条件$\alpha_1y_1 + \alpha_2y_2 = \varsigma\;\;0 \leq \alpha_i \leq C \;\; i =1,2$,又由于$y_1,y_2$均只能取值1或者-1, 这样$\alpha_1, \alpha_2$在[0,C]和[0,C]形成的盒子里面,并且两者的关系直线的斜率只能为1或者-1,也就是说$\alpha_1, \alpha_2$的关系直线平行于[0,C]和[0,C]形成的盒子的对角线,如下图所示:
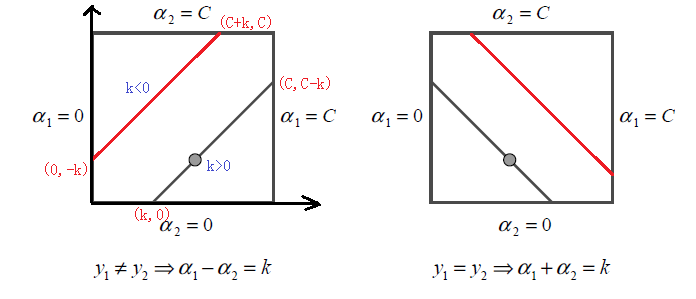
由于$\alpha_1, \alpha_2$的关系被限制在盒子里的一条线段上,所以两变量的优化问题实际上仅仅是一个变量的优化问题。不妨我们假设最终是$\alpha_2$的优化问题。由于我们采用的是启发式的迭代法,假设我们上一轮迭代得到的解是$\alpha_1^{old}, \alpha_2^{old}$,假设沿着约束方向$\alpha_2$未经剪辑的解是$\alpha_2^{new,unc}$.本轮迭代完成后的解为$\alpha_1^{new}, \alpha_2^{new}$
由于$\alpha_2^{new}$必须满足上图中的线段约束。假设L和H分别是上图中$\alpha_2^{new}$所在的线段的边界。那么很显然我们有:$$L \leq \alpha_2^{new} \leq H $$
而对于L和H,我们也有限制条件如果是上面左图中的情况,则$$L = max(0, \alpha_2^{old}-\alpha_1^{old}) \;\;\;H = min(C, C+\alpha_2^{old}-\alpha_1^{old})$$
如果是上面右图中的情况,我们有:$$L = max(0, \alpha_2^{old}+\alpha_1^{old}-C) \;\;\; H = min(C, \alpha_2^{old}+\alpha_1^{old})$$
也就是说,假如我们通过求导得到的$\alpha_2^{new,unc}$,则最终的$\alpha_2^{new}$应该为:
$$\alpha_2^{new}=
\begin{cases}
H& {L \leq \alpha_2^{new,unc} > H}\\
\alpha_2^{new,unc}& {L \leq \alpha_2^{new,unc} \leq H}\\
L& {\alpha_2^{new,unc} < L}
\end{cases}$$
那么如何求出$\alpha_2^{new,unc}$呢?很简单,我们只需要将目标函数对$\alpha_2$求偏导数即可。
首先我们整理下我们的目标函数。
为了简化叙述,我们令$$E_i = g(x_i)-y_i = \sum\limits_{j=1}^{m}\alpha_j^{*}y_jK(x_i, x_j)+ b - y_i$$,
其中$g(x)$就是我们在第一节里面的提到的$$g(x) = w^{*} \bullet \phi(x) + b =\sum\limits_{j=1}^{m}\alpha_j^{*}y_jK(x, x_j)+ b^{*}$$
我们令$$v_i = \sum\limits_{i=3}^{m}y_j\alpha_jK(x_i,x_j) = g(x_i) - \sum\limits_{i=1}^{2}y_j\alpha_jK(x_i,x_j) -b $$
这样我们的优化目标函数进一步简化为:$$W(\alpha_1,\alpha_2) = \frac{1}{2}K_{11}\alpha_1^2 + \frac{1}{2}K_{22}\alpha_2^2 +y_1y_2K_{12}\alpha_1 \alpha_2 -(\alpha_1 + \alpha_2) +y_1\alpha_1v_1 + y_2\alpha_2v_2$$
由于$\alpha_1y_1 + \alpha_2y_2 = \varsigma $,并且$y_i^2 = 1$,可以得到$\alpha_1用 \alpha_2$表达的式子为:$$\alpha_1 = y_1(\varsigma - \alpha_2y_2)$$
将上式带入我们的目标优化函数,就可以消除$\alpha_1$,得到仅仅包含$\alpha_2$的式子。$$W(\alpha_2) = \frac{1}{2}K_{11}(\varsigma - \alpha_2y_2)^2 + \frac{1}{2}K_{22}\alpha_2^2 +y_2K_{12}(\varsigma - \alpha_2y_2) \alpha_2 -(\alpha_1 + \alpha_2) +(\varsigma - \alpha_2y_2)v_1 + y_2\alpha_2v_2$$
忙了半天,我们终于可以开始求$\alpha_2^{new,unc}$了,现在我们开始通过求偏导数来得到$\alpha_2^{new,unc}$。
$$\frac{\partial W}{\partial \alpha_2} = K_{11}\alpha_2 + K_{22}\alpha_2 -2K_{12}\alpha_2 - K_{11}\varsigma y_2 + K_{12}\varsigma y_2 +y_1y_2 -1 -v_1y_2 +y_2v_2 = 0$$
整理上式有:$$(K_{11} +K_{22}-2K_{12})\alpha_2 = y_2(y_2-y_1 + \varsigma K_{11} - \varsigma K_{12} + v_1 - v_2)$$
$$ = y_2(y_2-y_1 + \varsigma K_{11} - \varsigma K_{12} + (g(x_1) - \sum\limits_{j=1}^{2}y_j\alpha_jK_{1j} -b ) -(g(x_2) - \sum\limits_{j=1}^{2}y_j\alpha_jK_{2j} -b))$$
将$ \varsigma = \alpha_1y_1 + \alpha_2y_2 $带入上式,我们有:
$$(K_{11} +K_{22}-2K_{12})\alpha_2^{new,unc} = y_2((K_{11} +K_{22}-2K_{12})\alpha_2^{old}y_2 +y_2-y_1 +g(x_1) - g(x_2))$$
$$\;\;\;\; = (K_{11} +K_{22}-2K_{12}) \alpha_2^{old} + y2(E_1-E_2)$$
我们终于得到了$\alpha_2^{new,unc}$的表达式:$$\alpha_2^{new,unc} = \alpha_2^{old} + \frac{y2(E_1-E_2)}{K_{11} +K_{22}-2K_{12})}$$
利用上面讲到的$\alpha_2^{new,unc}$和$\alpha_2^{new}$的关系式,我们就可以得到我们新的$\alpha_2^{new}$了。利用$\alpha_2^{new}$和$\alpha_1^{new}$的线性关系,我们也可以得到新的$\alpha_1^{new}$。
4. SMO算法两个变量的选择
SMO算法需要选择合适的两个变量做迭代,其余的变量做常量来进行优化,那么怎么选择这两个变量呢?
4.1 第一个变量的选择
SMO算法称选择第一个变量为外层循环,这个变量需要选择在训练集中违反KKT条件最严重的样本点。对于每个样本点,要满足的KKT条件我们在第一节已经讲到了: $$\alpha_{i}^{*} = 0 \Rightarrow y_ig(x_i) \geq 1 $$ $$ 0 \leq \alpha_{i}^{*} \leq C \Rightarrow y_ig(x_i) =1 $$ $$\alpha_{i}^{*}= C \Rightarrow y_ig(x_i) \leq 1$$
一般来说,我们首先选择违反$0 \leq \alpha_{i}^{*} \leq C \Rightarrow y_ig(x_i) =1 $这个条件的点。如果这些支持向量都满足KKT条件,再选择违反$\alpha_{i}^{*} = 0 \Rightarrow y_ig(x_i) \geq 1 $ 和 $\alpha_{i}^{*}= C \Rightarrow y_ig(x_i) \leq 1$的点。
4.2 第二个变量的选择
SMO算法称选择第二一个变量为内层循环,假设我们在外层循环已经找到了$\alpha_1$, 第二个变量$\alpha_2$的选择标准是让$|E1-E2|$有足够大的变化。由于$\alpha_1$定了的时候,$E_1$也确定了,所以要想$|E1-E2|$最大,只需要在$E_1$为正时,选择最小的$E_i$作为$E_2$, 在$E_1$为负时,选择最大的$E_i$作为$E_2$,可以将所有的$E_i$保存下来加快迭代。
如果内存循环找到的点不能让目标函数有足够的下降, 可以采用遍历支持向量点来做$\alpha_2$,直到目标函数有足够的下降, 如果所有的支持向量做$\alpha_2$都不能让目标函数有足够的下降,可以跳出循环,重新选择$\alpha_1$
4.3 计算阈值b和差值$E_i$
在每次完成两个变量的优化之后,需要重新计算阈值b。当$0 \leq \alpha_{1}^{new} \leq C$时,我们有 $$y_1 - \sum\limits_{i=1}^{m}\alpha_iy_iK_{i1} -b_1 = 0 $$
于是新的$b_1^{new}$为:$$b_1^{new} = y_1 - \sum\limits_{i=3}^{m}\alpha_iy_iK_{i1} - \alpha_{1}^{new}y_1K_{11} - \alpha_{2}^{new}y_2K_{21} $$
计算出$E_1$为:$$E_1 = g(x_1) - y_1 = \sum\limits_{i=3}^{m}\alpha_iy_iK_{i1} + \alpha_{1}^{old}y_1K_{11} + \alpha_{2}^{old}y_2K_{21} + b^{old} -y_1$$
可以看到上两式都有$y_1 - \sum\limits_{i=3}^{m}\alpha_iy_iK_{i1}$,因此可以将$b_1^{new}$用$E_1$表示为:$$b_1^{new} = -E_1 -y_1K_{11}(\alpha_{1}^{new} - \alpha_{1}^{old}) -y_2K_{21}(\alpha_{2}^{new} - \alpha_{2}^{old}) + b^{old}$$
同样的,如果$0 \leq \alpha_{2}^{new} \leq C$, 那么有:$$b_2^{new} = -E_2 -y_1K_{12}(\alpha_{1}^{new} - \alpha_{1}^{old}) -y_2K_{22}(\alpha_{2}^{new} - \alpha_{2}^{old}) + b^{old}$$
最终的$b^{new}$为:$$b^{new} = \frac{b_1^{new} + b_2^{new}}{2}$$
得到了$b^{new}$我们需要更新$E_i$:$$E_i = \sum\limits_{S}y_j\alpha_jK(x_i,x_j) + b^{new} -y_i $$
其中,S是所有支持向量$x_j$的集合。
好了,SMO算法基本讲完了,我们来归纳下SMO算法。
5. SMO算法总结
输入是m个样本${(x_1,y_1), (x_2,y_2), ..., (x_m,y_m),}$,其中x为n维特征向量。y为二元输出,值为1,或者-1.精度e。
输出是近似解$\alpha$
1)取初值$\alpha^{0} = 0, k =0$
2)按照4.1节的方法选择$\alpha_1^k$,接着按照4.2节的方法选择$\alpha_2^k$,求出新的$\alpha_2^{new,unc}$。$$\alpha_2^{new,unc} = \alpha_2^{k} + \frac{y_2(E_1-E_2)}{K_{11} +K_{22}-2K_{12})}$$
3)按照下式求出$\alpha_2^{k+1}$
$$\alpha_2^{k+1}=
\begin{cases}
H& {L \leq \alpha_2^{new,unc} > H}\\
\alpha_2^{new,unc}& {L \leq \alpha_2^{new,unc} \leq H}\\
L& {\alpha_2^{new,unc} < L}
\end{cases}$$
4)利用$\alpha_2^{k+1}$和$\alpha_1^{k+1}$的关系求出$\alpha_1^{k+1}$
5)按照4.3节的方法计算$b^{k+1}$和$E_i$
6)在精度e范围内检查是否满足如下的终止条件:$$\sum\limits_{i=1}^{m}\alpha_iy_i = 0 $$ $$0 \leq \alpha_i \leq C, i =1,2...m$$ $$\alpha_{i}^{k+1} = 0 \Rightarrow y_ig(x_i) \geq 1 $$ $$ 0 \leq \alpha_{i}^{k+1} \leq C \Rightarrow y_ig(x_i) = 1 $$ $$\alpha_{i}^{k+1}= C \Rightarrow y_ig(x_i) \leq 1$$
7)如果满足则结束,返回$\alpha^{k+1}$,否则转到步骤2)。
SMO算法终于写完了,这块在以前学的时候是非常痛苦的,不过弄明白就豁然开朗了。希望大家也是一样。写完这一篇, SVM系列就只剩下支持向量回归了,胜利在望!
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
支持向量机原理(四)SMO算法原理的更多相关文章
- EM算法原理总结
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断等等.本文就对 ...
- 支持向量机SMO算法实现(注释详细)
一:SVM算法 (一)见西瓜书及笔记 (二)统计学习方法及笔记 (三)推文https://zhuanlan.zhihu.com/p/34924821 (四)推文 支持向量机原理(一) 线性支持向量机 ...
- 机器学习之支持向量机(二):SMO算法
注:关于支持向量机系列文章是借鉴大神的神作,加以自己的理解写成的:若对原作者有损请告知,我会及时处理.转载请标明来源. 序: 我在支持向量机系列中主要讲支持向量机的公式推导,第一部分讲到推出拉格朗日对 ...
- Svm算法原理及实现
Svm(support Vector Mac)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性核非线性两大类.其主要思想为找到空间中的一个 ...
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- 机器学习--支持向量机 (SVM)算法的原理及优缺点
一.支持向量机 (SVM)算法的原理 支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析.它是将向量映射到一个更高维的 ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- 支持向量机(四)----序列最小最优化算法SMO
在支持向量机(二)和(三)中,我们均遗留了一个问题未解决,即如何求解原问题的对偶问题: 在支持向量机(二)中对偶问题为: 在支持向量机(三)中的对偶问题为: 对于上述两个对偶问题,我们在支持向量机(三 ...
随机推荐
- ubuntu14.04 安装 hadoop2.4.0
转载:ubuntu搭建hadoop-Ver2.6.0完全分布式环境笔记 自己在搭建hadoop平台时,碰到一些困难,按照该博文解决了问题,转载一下,作为记录. 2 先决条件 确保在你集群中的每个节点上 ...
- iOS 让按钮上的标题换行显示
项目中遇到了要让按钮上的文字换行显示的需求,就写了这个博客. 1.如果按钮上的文字固定,形式是写死的,可以考虑给标题文字加\n换行符来达到效果,但是,记得一定要设置这个属性,不然是不会换行的, but ...
- 如何在select下拉列表中添加复选框?
近来在给一个公司做考试系统的项目,遇到的问题不少,但其中的几个让我对表单的使用颇为感兴趣,前端程序员都知道,下拉列表有select标签,复选框有checkbox,但是两者合在一起却少有人去研究,当时接 ...
- VS2010 中,windows服务不能添加 System.Web 引用
今天在写windows服务的时候,右键添加引用->.NET中没有找到System.Web,在->Recent中找到System.Web,但添加完后却显示黄色叹号,最后百度一下解决了这个问题 ...
- C++指针类型识别正确姿势
指针是C和C++中编程最复杂也是最有技巧的部分,但对于新手来说,指针无疑是最致命的,让很多人望而退步.不过很多事情都是从陌生开始,然后渐渐熟悉起来的,就像交朋友一样,得花点时间去培养感情才行.不过指针 ...
- Linux 安装PHP PECL 百分百成功
1. 下载 需要安装的组件 http://pecl.php.net/packages.php 2. 解压 tar zxf 你的扩展包路径 3. 进入你解压的扩展包路径后 访问 /usr/bin ...
- 《Linux内核设计与实现》读书笔记 第四章 进程调度
第四章进程调度 进程调度程序可看做在可运行太进程之间分配有限的处理器时间资源的内核子系统.调度程序是多任务操作系统的基础.通过调度程序的合理调度,系统资源才能最大限度地发挥作用,多进程才会有并发执行的 ...
- Linux 服务器监控
200 ? "200px" : this.width)!important;} --> 标签:iostat/free/top/dstat 概述 文字主要讲述使用linux自带 ...
- C#设计模式之观察者
Iron之观察者 引言 上一篇说的职责链模式,很有意思的一个模式,今天这个模式也是很有意思的一个模式,还是不啰嗦了直接进入主题吧. 场景介绍:在上一遍中说到用到部件检测,很巧妙的让调用者和处理者解耦了 ...
- 60分钟Python快速学习(给发哥一个交代)
60分钟Python快速学习 之前和同事谈到Python,每次下班后跑步都是在听他说,例如Python属于“胶水语言啦”,属于“解释型语言啦!”,是“面向对象的语言啦!”,另外没有数据类型,逻辑全靠空 ...