scrapy——8 scrapyd使用
scrapy——8 scrapyd使用
- 什么是scrapyd
- 怎么安装scrapyd
- 如何使用scrapyd--运行scrapyd
- 如何使用scrapyd--配置scrapy.cfg
- 如何使用scrapyd--添加到爬虫工程
- 如何使用scrapyd--运行爬虫任务
- 如何使用scrapyd--停止爬虫任务
- 如何使用scrapyd--删除爬虫项目
- 如何使用scrapyd--查看存在的爬虫工程
什么是scrapyd?
scrapyd是运行scrapy爬虫的服务程序,它支持以http命令方式发布、删除、启动、停止爬虫程序。而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本。
特点:
- 可以避免爬虫源码被看见。
- 有版本控制。
- 可以远程启动、停止、删除
scrapyd官方文档:https://scrapyd.readthedocs.io/en/stable/overview.html
怎么安装scrapyd
安装scrapyd
主要有两种方法:
pip install scrapyd (安装的版本可能不是最新的)
从 https://github.com/scrapy/scrapyd 中下载源码,
运行python setup.py install 命令进行安装
2. 安装scrapyd-deploy
主要有两种安装方式:
pip install scrapyd-client(安装的版本可能不是最新版本)
从 http://github.com/scrapy/scrapyd-client 中下源码,
运行python setup.py install 命令进行安装。
如何使用scrapyd?
运行scrapyd
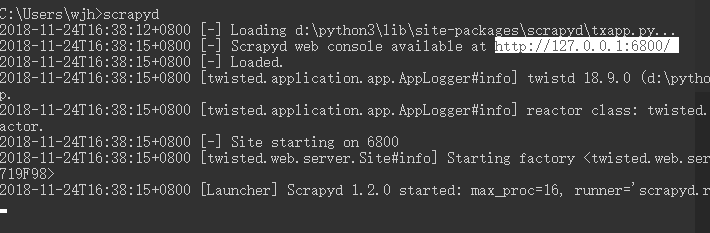
直接在终端输入scrapyd,访问http链接
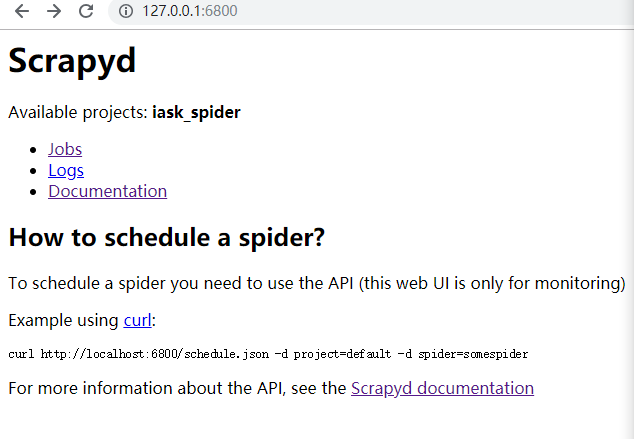
配置scrapy.cfg
这时进入到我们的scrapy项目中,找到新建scrapy项目都会生成的scrapy.cfg文件
打开后是这样的内容
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html [settings]
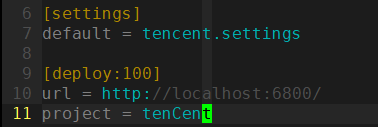
default = tencent.settings [deploy]
#url = http://localhost:6800/
project = tencent
- 首先去掉url前面的注释符号,url是scrapyd服务器的网址
- 然后project=tenCent为项目名称,可以随意起名
- 修改[deploy]为[depoly:100],表示把爬虫发布到名为100的爬虫服务器上,一般在需要同时发布爬虫到多个目标服务器时使用
添加到爬虫工程
命令如下:
Scrapyd-deploy <target> -p <project> --version <version>
参数解释:
- target:deploy后面的名称。
- project:自行定义名称,跟爬虫的工程名字无关。
- version:自行定义版本号,不写的话默认为当前时间戳
现在我们来上传一个新的项目到scrapd中
来到项目的能运行scrapy的路径下,输入:
scrapyd-deploy 100 -p tenCent --version v1

这是刷新6800端口网页,会发现已经有项目被添加进来了
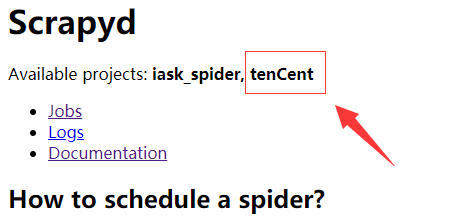
此时的job还是没有数据的
运行爬虫任务
运行爬虫项目的命令如下:
curl http://localhost:6800/schedule.json -d project=project_name -d spider=spider_name
- project:scrapy.cfg中设置的project
- spider_name:运行scrapy的项目名称===》scrapy list

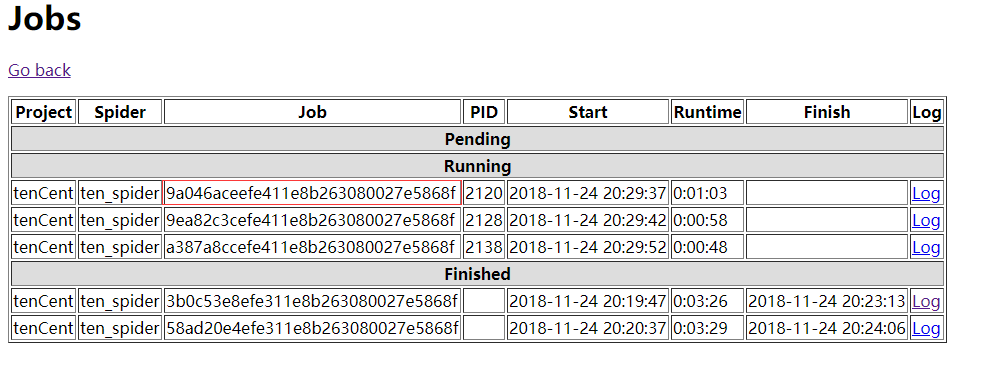
运行代码以后:


停止爬虫任务
curl http://localhost:6800/cancel.json -d project=project_name -d job=job_id
job_id:如图所致

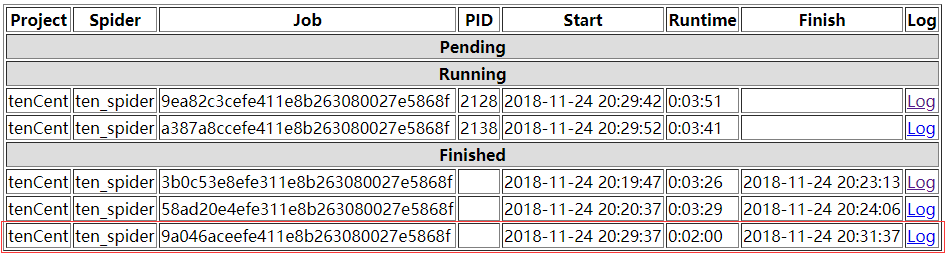
可以看出,爬虫在2:00时就停止了
log可以查看运行结果
删除爬虫
curl http://localhost:6800/delproject.json -d project=project_name


查看scrapyd中存在的项目
curl http://localhost:6800/listprojects.json

还有其他更多的命令,请参考官网:https://scrapyd.readthedocs.io/en/latest/api.html
scrapy——8 scrapyd使用的更多相关文章
- scrapy的scrapyd使用方法
一直以来,很多人疑惑scrapy提供的scrapyd该怎么用,于我也是.自己在实际项目中只是使用scrapy crawl spider,用python来写一个多进程启动,还用一个shell脚本来监控进 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- scrapy与scrapyd安装
Scrapy是用python编写的爬虫程序. Scrapyd是一个部署与运行scrapy爬虫的应用,提供JSON API的调用方式来部署与控制爬虫 . 本文验证在fedora与centos是安装成功. ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- 如何部署Scrapy 到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- Python爬虫从入门到放弃(二十一)之 Scrapy分布式部署
按照上一篇文章中我们将代码放到远程主机是通过拷贝或者git的方式,但是如果考虑到我们又多台远程主机的情况,这种方式就比较麻烦,那有没有好用的方法呢?这里其实可以通过scrapyd,下面是这个scrap ...
- 基于scrapyd爬虫发布总结
一.版本情况 python以丰富的三方类库取得了众多程序员的认可,但也因此带来了众多的类库版本问题,本文总结的内容是基于最新的类库版本. 1.scrapy版本:1.1.0 D:\python\Spid ...
随机推荐
- P5180 【模板】支配树
这个题乱七八糟的,和之前的灭绝树有点像,但是不一样.那个是DAG,这个是有向图.简单步骤就是先求出来dfs序,然后求出半支配点(?),然后通过这个求支配点. 算法不是很理解,先放在这. 题干: 题目背 ...
- LuoguP4246 [SHOI2008]堵塞的交通
https://zybuluo.com/ysner/note/1125078 题面 给一个网格,每次把相邻两点连通性改为\(1\)或\(0\),询问两点是否联通. 解析 线段树神题... 码量巨大,细 ...
- 【废弃】【WIP】JavaScript 函数
创建: 2017/10/09 更新: 2017/11/03 加上[wip] 废弃: 2019/02/19 重构此篇.原文归入废弃 增加[废弃中]标签与总体任务 结束: 2019/03/12 完成废弃 ...
- hibernate基础简单入门1---helloword
1:目录结果 2:实体类(student.java) package com.www.entity; public class Student { private int id; private St ...
- Another lottery
http://acm.hdu.edu.cn/showproblem.php?pid=2985 题意:有n个人每个人可以买m轮彩票,每轮可以买尽可能多的彩票.如果该彩票在i轮被抽到,则该人可以获得2^i ...
- P3309 [SDOI2014]向量集
传送门 达成成就:一人独霸三页提交 自己写的莫名其妙MLE死都不知道怎么回事,照着题解打一直RE一个点最后发现竟然是凸包上一个点求错了--四个半小时就一直用来调代码了-- 那么我们只要维护好这个凸壳, ...
- [Swift通天遁地]八、媒体与动画-(9)快速实现复合、Label、延续、延时、重复、缓冲、弹性动画
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- Unity - 简单实例化的应用
项目描述:每帧实例化一个随机颜色的物体(Cube),坐标在某范围内随机:且物体每帧都会缩小,当缩小到一定的尺寸时,就销毁物体 代码描述: public class CubeSpawner : Mono ...
- [Luogu 1052] noip 05 过河
[Luogu 1052] noip 05 过河 题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧.在桥上有一些石子,青蛙很讨厌踩在这些石子上.由于桥的长度和青蛙一次跳过的距离都是 ...
- Linux命令(004) -- watch
对Linux系统的操作过程中,经常会遇到重复执行同一命令,以观察其结果变化的情况.惯用的方法是:上下键加回车,或是Ctr+p然后回车.今天我们来了解一下watch命令,它可以帮助我们周期性的执行一个命 ...