聚类(Clustering)
- 简介
相对于决策树、朴素贝叶斯、SVM等有监督学习,聚类算法属于无监督学习。
有监督学习通常根据数据集的标签进行分类,而无监督学习中,数据集并没有相应的标签,算法仅根据数据集进行划分。
由于具有出色的速度和良好的可扩展性,Kmeans聚类算法算得上是最著名的聚类方法。
- 基本思想
在没有标签的数据集中,所有的数据点都是同一类的。
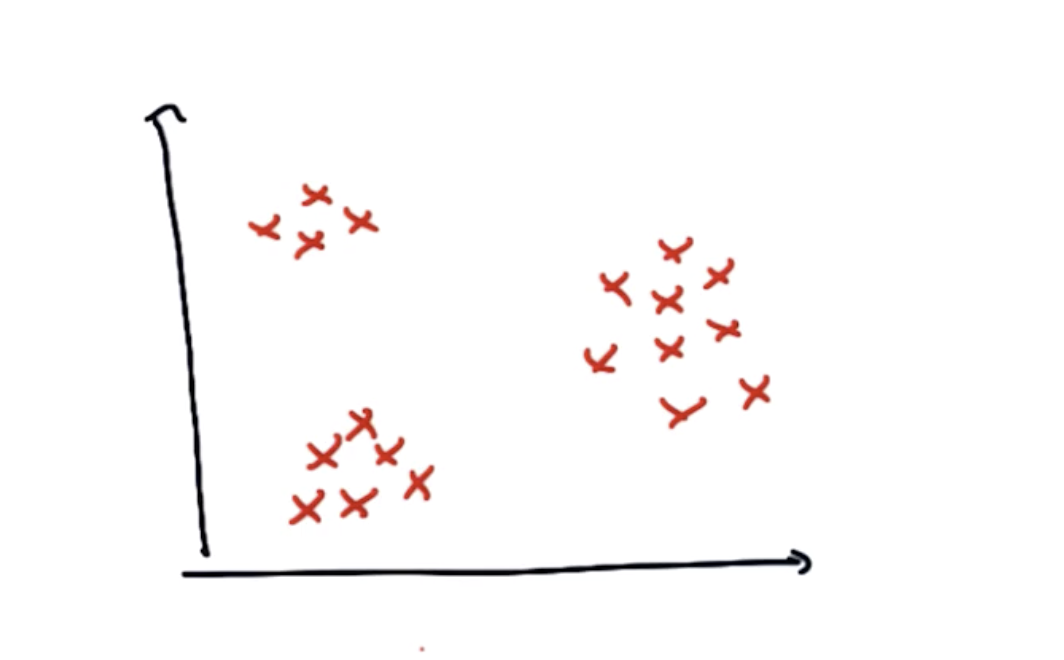
在这张图中,虽然数据都为同一类,但是可以直观的看出,数据集存在簇或聚类。这种数据没有比标签,但能发现其结构的情况,称作非监督学习。
最基本的聚类算法,也是目前使用最多的聚类算法叫做K-均值(K-Means)。
假设一组数据集为下图:
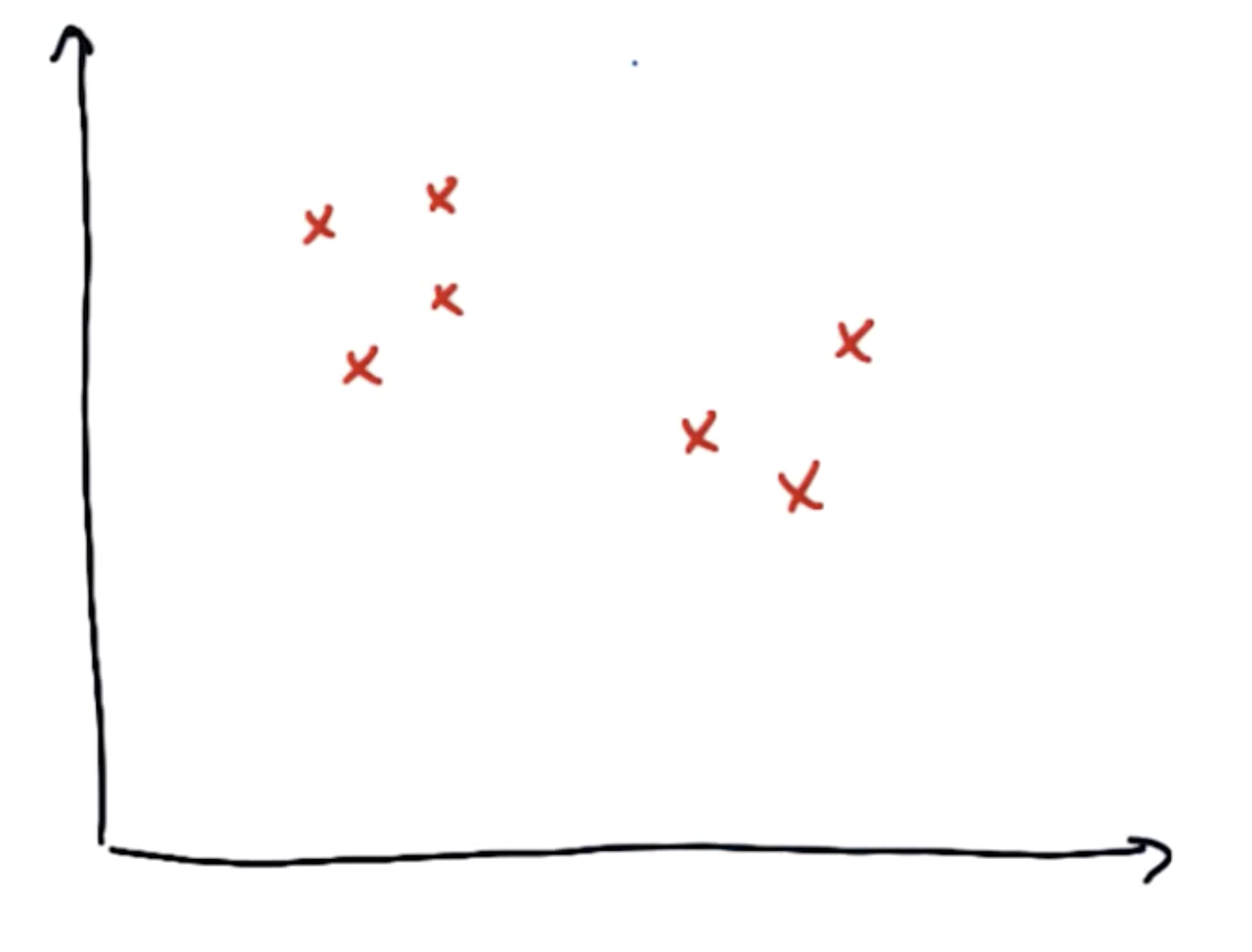
他们应该有两个簇,其中簇的中心如下图:
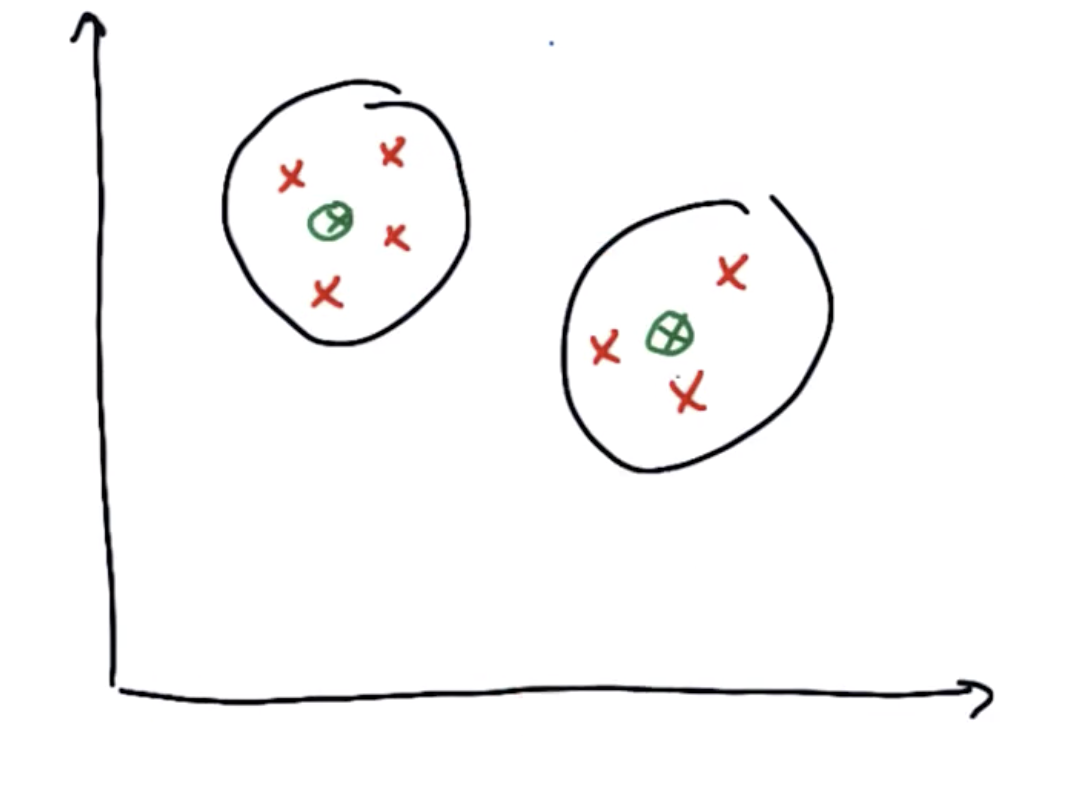
在K-Means算法中,首先随便画出聚类中心,它可以是不正确的:
(假设上方绿点为中心1,下方绿点为中心2)

K-Means算法分为两个步骤:
1、分配
2、优化
进行第一步,对于上图的数据集,首先找出在所有红色点中,距离中心1比距离中心2更近的点
简单的方法是找出两个中心点的垂直平分线,将红色的点分割为两部分,分别是距离各自中心更近的点
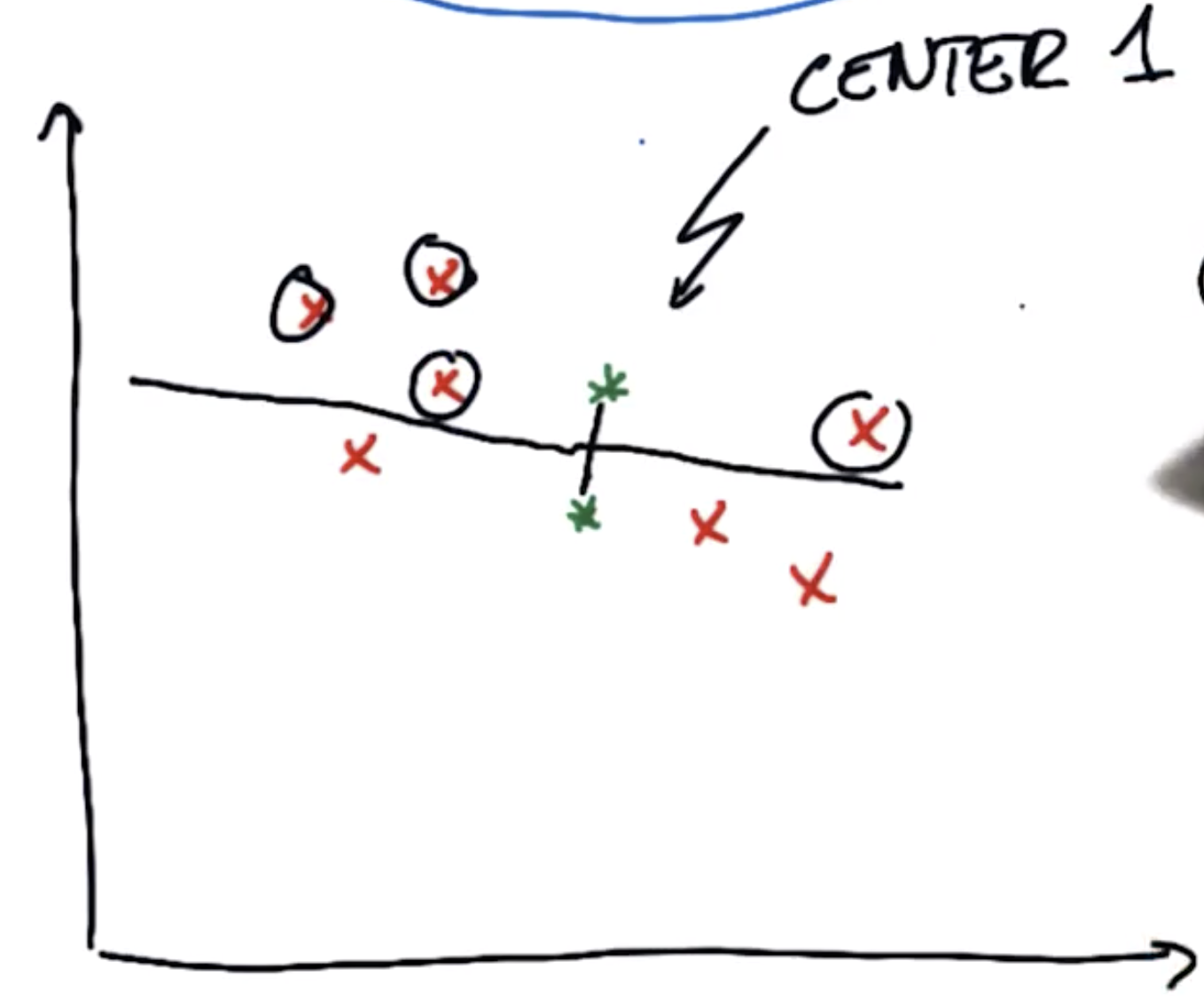
第二步是优化。首先将聚类中心和第一步分配完的点相连接,然后开始优化:移动聚类中心,使得与聚类中心相连接的线的平方和最短。
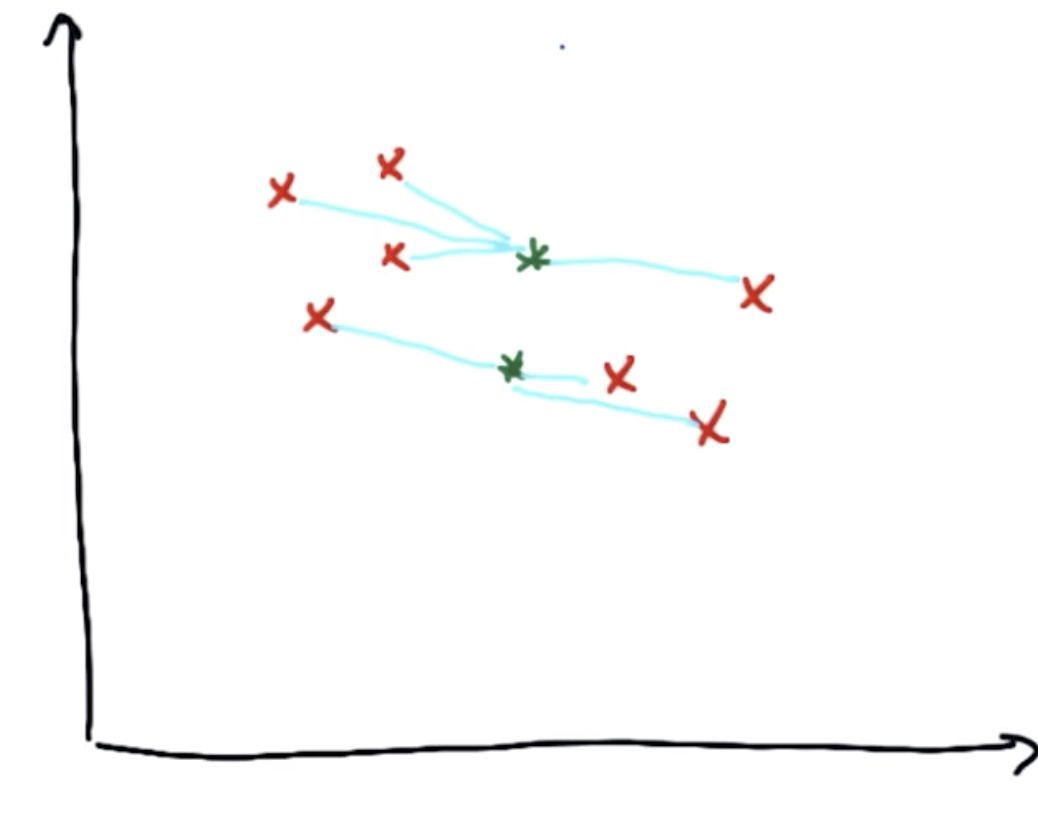
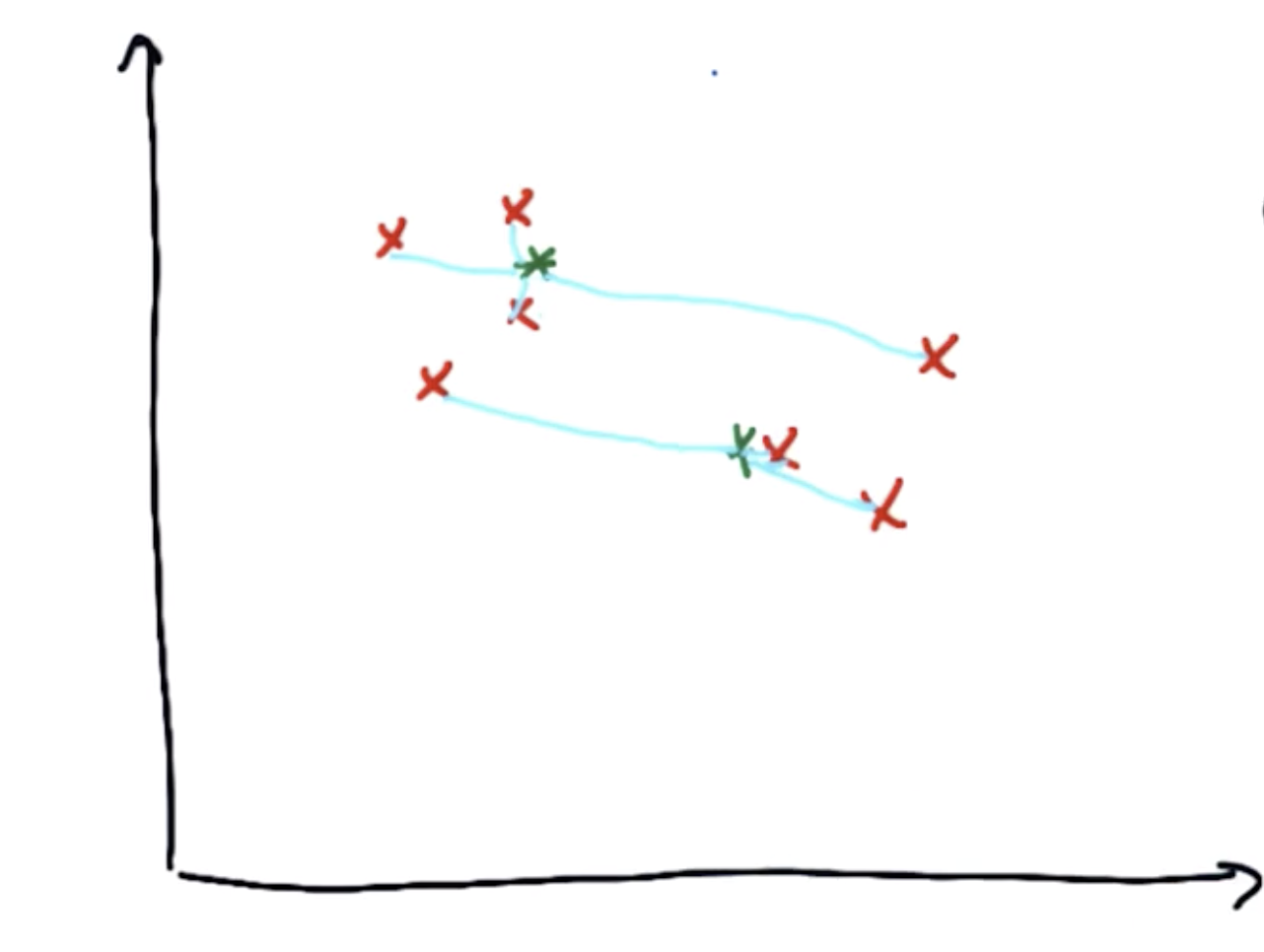
多次进行步骤1和2,即先分配再优化,聚类中心将会逐步移动到数据簇的中心。

- 代码实现
环境:MacOS mojave 10.14.3
Python 3.7.0
使用库:scikit-learn 0.19.2
sklearn.cluster.KMeans官方库:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
>>> from sklearn.cluster import KMeans
>>> import numpy as np
>>> X = np.array([[1, 2], [1, 4], [1, 0],
... [10, 2], [10, 4], [10, 0]]) #输入六个数据点 >>> kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
#确定一共有两个聚类中心 >>> kmeans.labels_
array([1, 1, 1, 0, 0, 0], dtype=int32) >>> kmeans.predict([[0, 0], [12, 3]]) #预测两个新点的聚类分类情况
array([1, 0], dtype=int32) >>> kmeans.cluster_centers_ #输出两个聚类中心的坐标
array([[10., 2.],
[ 1., 2.]])
聚类(Clustering)的更多相关文章
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- sklearn:聚类clustering
http://blog.csdn.net/pipisorry/article/details/53185758 不同聚类效果比较 sklearn不同聚类示例比较 A comparison of the ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
第十三章.聚类--Clustering ******************************************************************************** ...
- [C8] 聚类(Clustering)
聚类(Clustering) 非监督学习:简介(Unsupervised Learning: Introduction) 本章节介绍聚类算法,这是我们学习的第一个非监督学习算法--学习无标签数据,而不 ...
- 机器学习(九)-------- 聚类(Clustering) K-均值算法 K-Means
无监督学习 没有标签 聚类(Clustering) 图上的数据看起来可以分成两个分开的点集(称为簇),这就是为聚类算法. 此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者 ...
- 机器学习-聚类(clustering)算法:K-means算法
1. 归类: 聚类(clustering):属于非监督学习(unsupervised learning) 无类别标记(class label) 2. 举例: 3. Kmeans算法 3.1 clust ...
- 聚类clustering
聚类:把相似的东西分到一组,是无监督学习. 聚类算法的分类: (1)基于划分聚类算法(partition clustering):建立数据的不同分割,然后用相同标准评价聚类结果.(比如最小化平方误差和 ...
- 海量数据挖掘MMDS week5: 聚类clustering
http://blog.csdn.net/pipisorry/article/details/49427989 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [综]聚类Clustering
Annie19921223的博客 [转载]用MATLAB做聚类分析 http://blog.sina.com.cn/s/blog_9f8cf10d0101f60p.html Free Mind 漫谈 ...
随机推荐
- [luogu3232 HNOI2013] 游走 (高斯消元 期望)
传送门 题目描述 一个无向连通图,顶点从1编号到N,边从1编号到M. 小Z在该图上进行随机游走,初始时小Z在1号顶点,每一步小Z以相等的概率随机选 择当前顶点的某条边,沿着这条边走到下一个顶点,获得等 ...
- PHP 使用 Kafka 安装拾遗
最近项目开发中需要使用 Kafka 消息队列.经过检索,PHP下面有通用的两种方式来调用 Kafka . php-rdkafka 扩展 以 PHP 扩展的形式进行使用是非常高效的.另外,该项目也提供了 ...
- 基于Linux ALSA音频驱动的wav文件解析及播放程序 2012
本设计思路:先打开一个普通wav音频文件,从定义的文件头前面的44个字节中,取出文件头的定义消息,置于一个文件头的结构体中.然后打开alsa音频驱动,从文件头结构体取出采样精度,声道数,采样频率三个重 ...
- String类常见的方法
类String public final class String extends Object implements Serializable, comparable<String>, ...
- MYSQL数据的安装、配置
linux安装mysql服务分两种安装方法: 1.源码安装,优点是安装包比较小,只有十多M,缺点是安装依赖的库多,安装编译时间长,安装步骤复杂容易出错. 2.使用官方编译好的二进制文件安装,优点是安装 ...
- Cache index coloring for virtual-address dynamic allocators
A method for managing a memory, including obtaining a number of indices and a cache line size of a c ...
- Solr 搜索的过程和所须要的參数
一个典型的搜索处理过程,以及所须要的參数例如以下: qt:指定一个RequestHandler,即/select.缺省是使用DisMax RequestHandler defType:选择一个quer ...
- 杭电(hdu)ACM 4548 美素数
美素数 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others) Total Submis ...
- Spring-SpringJdbcTemlate配置介绍
使用spring的jdbcTemplate进一步操作JDBC 一.普通配置 SpringJdbcTemplate连接数据库并操作数据 1.applicationContext.xml 1.1 建立D ...
- NOI.AC: NOIP2018 全国模拟赛习题练习
闲谈: 最后一个星期还是不浪了,做一下模拟赛(还是有点小虚) #30.candy 题目: 有一个人想买糖吃,有两家商店A,B,A商店中第i个糖果的愉悦度为Ai,B商店中第i个糖果的愉悦度为Bi 给出n ...