selenium + ChromeDriver 实战系列之启信宝(一)
1. 友情链接
2. 爬取思路及流程
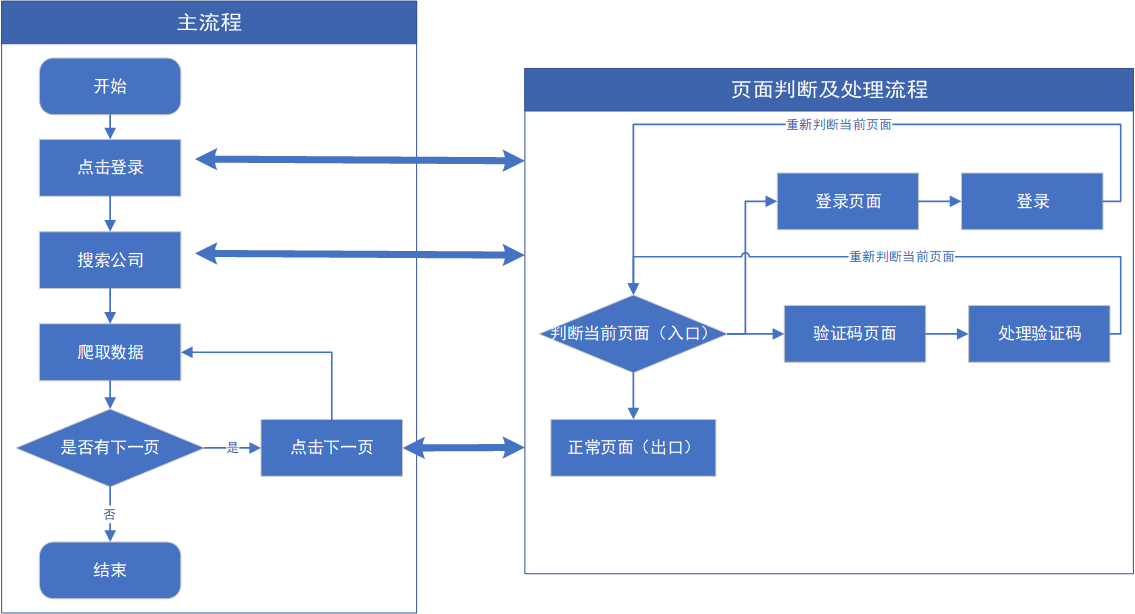
2.1 点击登录
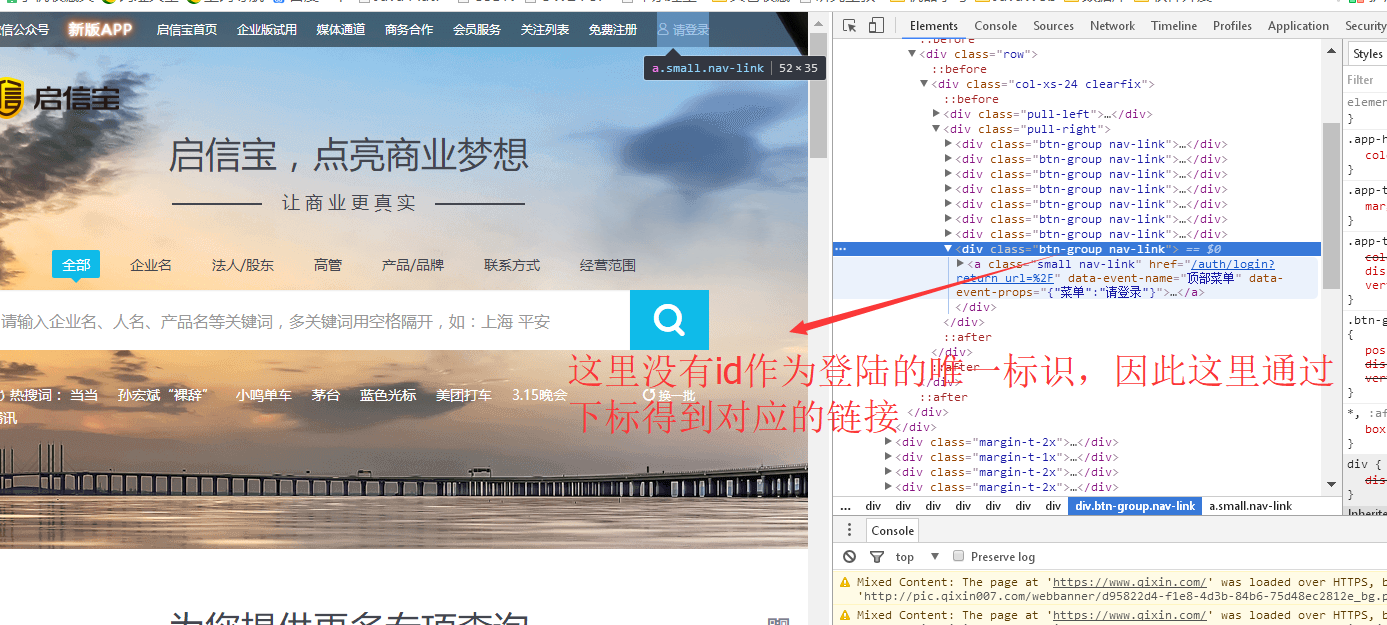
//去登陆页面并且登录
public static void toLoginAndLogin(WebDriver driver) {
//1、去登陆页面
List<WebElement> elements = driver.findElements(By.cssSelector("div.pull-right a"));
//2、通过下标得到对应的登录链接
WebElement loginElement = elements.get(elements.size() - 1);
loginElement.click();
//2、该方法判断当前页面是登录页面,则进行登录
CompanyInfoPageHandle.handleDifferentPage(driver);
}
2.2 搜索公司
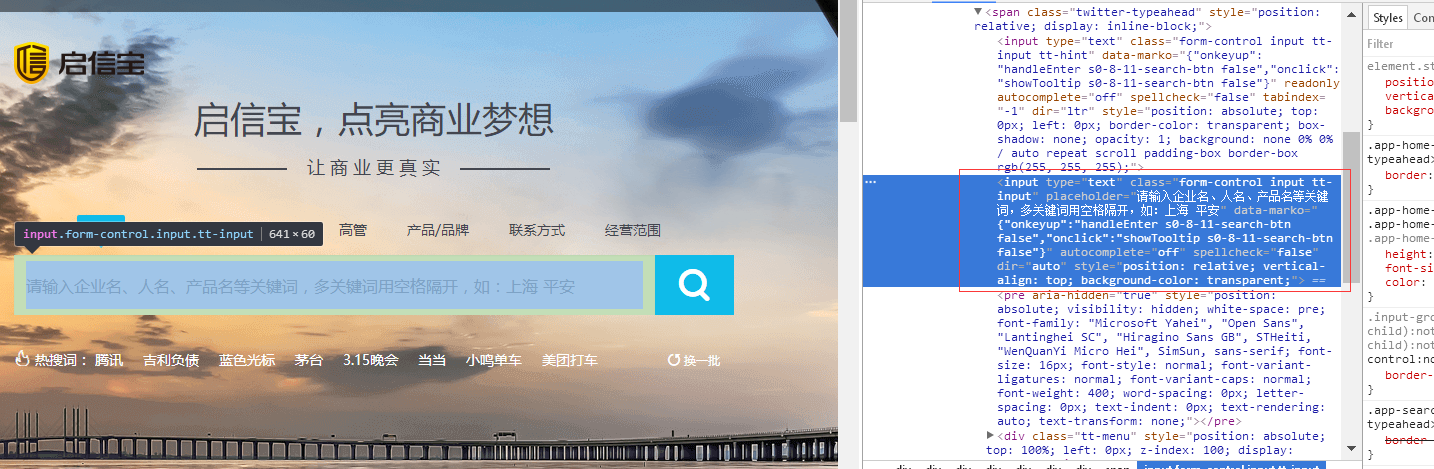
//查询公司名称
public static void searchCompanyName(WebDriver driver, String CompanyName) {
//1、查询公司名称
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//2、选取输入框
WebElement search = driver.findElement(By.cssSelector("input[placeholder=\"请输入企业名、人名、产品名等关键词,多关键词用空格隔开,如:上海 平安\"]"));
search.sendKeys(CompanyName);
//3、选取按钮
WebElement submit = driver.findElement(By.cssSelector("i.input-group-addon.search-btn.icon.icon-search"));
submit.click();
//4、判断当前页面的情况并进行处理
CompanyInfoPageHandle.handleDifferentPage(driver);
}
2.3 爬取当前数据
/**
* 保存信息
* @param driver
* @param companyName
*/
private void saveResult(WebDriver driver, String companyName) {
try {
Thread.sleep(2000);
//1、首先遍历每行的公司信息
List<WebElement> companyElementList = driver.findElements(By.cssSelector("div.col-xs-24.padding-v-1x.margin-0-0x.border-b-b4.company-item"));
//2、保存当前一行公司的信息
for (WebElement companyElement : companyElementList) {//保存信息
try {
List<WebElement> companyInfoElementList = companyElement.findElements(By.cssSelector("div"));
List<String> infoList = new ArrayList<>();
for (WebElement companyInfo : companyInfoElementList) {
infoList.add(companyInfo.getText().replace("\n", ""));
}
String result = String.join("\t", infoList);
FileUtils.saveLineAppend(companyName + ".txt", result);
} catch (Exception e) {
continue;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
2.4 页面判断及处理
/**
* 用来判别页面的情况
*/
public class CompanyInfoPageClassification {
/**
* 页面判断的主方法,用来判断当前的页面是什么页面
* @param driver
* @return
*/
public static String PageClassificationMain(WebDriver driver){
if (isVerificationCodePage(driver)){
return "验证码";
}
if (is404Page(driver)){
return "404";
}
if (isLoginPage(driver)){
return "登录";
}
return "正常";
}
/**
* 判断当前页面是否是验证码页面
* @param driver
* @return
*/
private static boolean isVerificationCodePage(WebDriver driver){
List<WebElement> buttonList = driver.findElements(By.cssSelector("button.btn4"));
if (buttonList.size() != 0 && buttonList.get(0).getText().equals("点击按钮进行验证")) {
return true;
} else {
return false;
}
}
/**
* 判断当前页面是否是404
* @param driver
* @return
*/
private static boolean is404Page(WebDriver driver){
List<WebElement> buttonList = driver.findElements(By.cssSelector("div.error-container.error-404"));
if (buttonList.size() != 0 ) {
return true;
} else {
return false;
}
}
/**
* 判断当前页面是否是登录页面
* @param driver
* @return
*/
private static boolean isLoginPage(WebDriver driver){
List<WebElement> buttonList = driver.findElements(By.cssSelector("input[placeholder=\"请输入手机号码\"]"));
if (buttonList.size() != 0 ) {
return true;
} else {
return false;
}
}
}
**
* 根据不同的页面进行不同的处理
*/
public class CompanyInfoPageHandle {
public static void handleDifferentPage(WebDriver driver){
try {
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
String pageStatus = CompanyInfoPageClassification.PageClassificationMain(driver);
switch (pageStatus){
case "验证码":
//1、如果是验证码页面那么需要在这里进行处理,例如手动输入验证码。如果验证码比较简单可以使用字符识别的方法
System.out.println("验证码页面");
//2、登录完了之后再判断是什么页面,然后再对当前页面进行处理
handleDifferentPage(driver);
break;
case "登录":
//1、如果是登录页面那就进行登录
login(driver, "用户名","密码");
//2、登录完了之后再判断是什么页面,然后再对当前页面进行处理
handleDifferentPage(driver);
break;
case "404":
break; }
} private static void login(WebDriver driver, String userName, String password){
WebElement phoneElement = driver.findElement(By.cssSelector("input[placeholder=\"请输入手机号码\"]"));
phoneElement.sendKeys(userName);
WebElement passwordElement = driver.findElement(By.cssSelector("input[placeholder=\"请输入密码\"]"));
passwordElement.sendKeys(password);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
List<WebElement> elements2 = driver.findElements(By.cssSelector("div a.btn"));
WebElement login = elements2.get(0);
login.click();
}
}
3. github地址并总结经验
<li><a href="/example" data-marko="{"onclick":"handleClickDebounce s0-9-20 false 0"}">2</a></li>
selenium + ChromeDriver 实战系列之启信宝(一)的更多相关文章
- requests,lxml爬启信宝
首先, 添加requests模块: 然后, 添加lxml模块: 启信宝登录抓包: QiXinBao.py: import requestsfrom lxml import etree loginUrl ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- AspNetCore-MVC实战系列(二)之通过绑定邮箱找回密码
AspNetCore - MVC实战系列目录 . 爱留图网站诞生 . AspNetCore - MVC实战系列(一)之Sqlserver表映射实体模型 . AspNetCore-MVC实战系列(二)之 ...
- SQL Server 性能优化实战系列(二)
SQL Server datetime数据类型设计.优化误区 一.场景 在SQL Server 2005中,有一个表TestDatetime,其中Dates这个字段的数据类型是datetime,如果你 ...
- .net core实践系列之短信服务-为什么选择.net core(开篇)
前言 从今天我将会写.net core实战系列,以我最近完成的短信服务作为例子.该系列将会尽量以最短的时间全部发布出来.源码也将优先开源出来给大家. 源码地址:https://github.com/S ...
- Java工程师之Redis实战系列教程前言&目录
系列前言 Java工程师之Redis实战系列教程,同其他教程一样,均是在下学习笔记,本系列主要参考自<Redis-in-action>,将书本中的有趣的例子转化为能解决特定问题的示例程序, ...
- [转]微信小程序之加载更多(分页加载)实例 —— 微信小程序实战系列(2)
本文转自;http://blog.csdn.net/michael_ouyang/article/details/56846185 loadmore 加载更多(分页加载) 当用户打开一个页面时,假设后 ...
- ASP.NET MVC WebApi 返回数据类型序列化控制(json,xml) 用javascript在客户端删除某一个cookie键值对 input点击链接另一个页面,各种操作。 C# 往线程里传参数的方法总结 TCP/IP 协议 用C#+Selenium+ChromeDriver 生成我的咕咚跑步路线地图 (转)值得学习百度开源70+项目
ASP.NET MVC WebApi 返回数据类型序列化控制(json,xml) 我们都知道在使用WebApi的时候Controller会自动将Action的返回值自动进行各种序列化处理(序列化为 ...
随机推荐
- SqlBulkCopy 帮助类
using System;using System.Collections.Generic;using System.Configuration;using System.Data;using Sys ...
- Material Designer的低版本兼容实现 —— ActivityOptionsCompat
http://www.bubuko.com/infodetail-460163.html
- Redis Service
https://raw.githubusercontent.com/MSOpenTech/redis/3.0/Windows%20Service%20Documentation.md
- [Docker] Container & image (docker run)
image: stopped container Run a container: docker run -d --name web -p : nigelpoulton/pluralsight-doc ...
- PyCharm 重构(refactor)快捷键
提取变量(比如一个函数会返回一个变量值):ctrl + alt + v(v:variable) 将某段代码封装为一个函数(函数+函数调用):ctrl + alt + m(m:method)
- iOS QLPreviewController(Quick Look)快速浏览jpg,PDF,world等
#import <QuickLook/QuickLook.h> @interface ViewController ()<QLPreviewControllerDataSource, ...
- 微信小程序唤起其他微信小程序 / 移动应用App唤起小程序
微信小程序唤起其他微信小程序 / 移动应用App唤起小程序 1. 微信小程序唤起微信小程序 小程序唤起其他小程序很简单 先上链接 小程序跳转小程序 Navigator组件 推荐使用 小程序跳转小程序 ...
- 关于JDBC连接数据库时出现的Public Key Retrieval is not allowed错误
问题描述 最近在学习MyBatis框架,参考官方的文档通过配置文件的方式已经实现了通过Configuration配置文件和mapper映射文件访问mysql8数据库,于是想试试不使用XML文件去构建S ...
- 简单的记录一下JavaScript 高级应用
我是一名.net 程序员但是由于公司需求,开发离线app,但是在工作的过程中我发现,周围人在写JavaScript的时候都是面向过程的编码,对于我这.net程序员,遇到这种情况真是六神无主,但是工作中 ...
- 51系列小型操作系统精髓 简单实现6 C语言版待改进
#include "STC12C5A.H" #define TIMER_RELOAD() {TL0=0x00;TH0=0xC4;}//使能T/C 初始10ms #define ...