回归分析-2.X 简单线性回归
2.1
简单线性回归模型
y与x之间的关系假设
\(y=\beta_0+\beta_1x+\varepsilon\)
\(E(\varepsilon|x)=0\)
\(Var(\varepsilon|x)=\sigma^2~则~Var(y|x)=\sigma^2\) 同方差假定
2.2
回归参数的最小二乘估计
回归系数 \(\beta_0,~\beta_1\) 的估计
残差平方和
\[S(\hat{\beta}_0,\hat{\beta}_1)=\sum^n_{i=1}(y_i-\hat{\beta}_0-\hat{\beta}_1x_i)^2
\]
分别求偏导得到
\[\hat{\beta}_{0}=\bar{y}-\hat{\beta}_{1} \bar{x}
\]\[\hat{\beta}_{1}=\frac{\sum_{i=1}^{n} x_{i} y_{i}-n \cdot \bar{x} \cdot \bar{y}}{\sum_{i=1}^{n} x_{i}^{2}-n \cdot \bar{x}^{2}}=\frac{\sum\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sum\left(x_{i}-\bar{x}\right)^{2}}=\frac{S_{x y}}{S_{x x}}
\]
性质
\[\frac{\partial S}{\partial\beta_0}=\sum(y_i-\hat{\beta}_0-\hat{\beta}_1x_i)=0~\Rightarrow~\sum e_i=0
\]
\[\frac{\partial S}{\partial\beta_1}=\sum(y_i-\hat{\beta}_0-\hat{\beta}_1x_i)x_i=0~\Rightarrow
\]\[\sum e_ix_i=\sum (e_i-\bar{e})x_i=\sum(e_i-\bar{e})(x_i-\bar{x})=0
\]进而知道\(\{e_i\}与\{x_i\}\) 互不相关
\(\sum(e_i-\bar{e})(y_i-\bar{y})=\sum e_iy_i=\sum e_i(\hat{\beta}_0+\hat{\beta}_1x_i)=\hat{\beta}_0\sum e_i+\hat{\beta}_1\sum(e_ix_i)=0\)
因此得出\(\{e_i\}与\{y_i\}\) 互不相关
\(\{e_i\}与\{\hat{y}_i\}\) 互不相关
\(Cov(\bar{y},\hat{\beta}_1)=0\)
\[\begin{aligned}
Cov(\bar{y},\hat{\beta}_1)&=\frac{1}{n}\sum Cov(y_i,\hat{\beta}_1)\\
&=\frac{1}{n}Cov(\sum y_i,\sum c_iy_i)\\
&=\frac{1}{n}\sum (c_i\sigma^2)\\
&=0
\end{aligned}\]
- OLS是线性估计
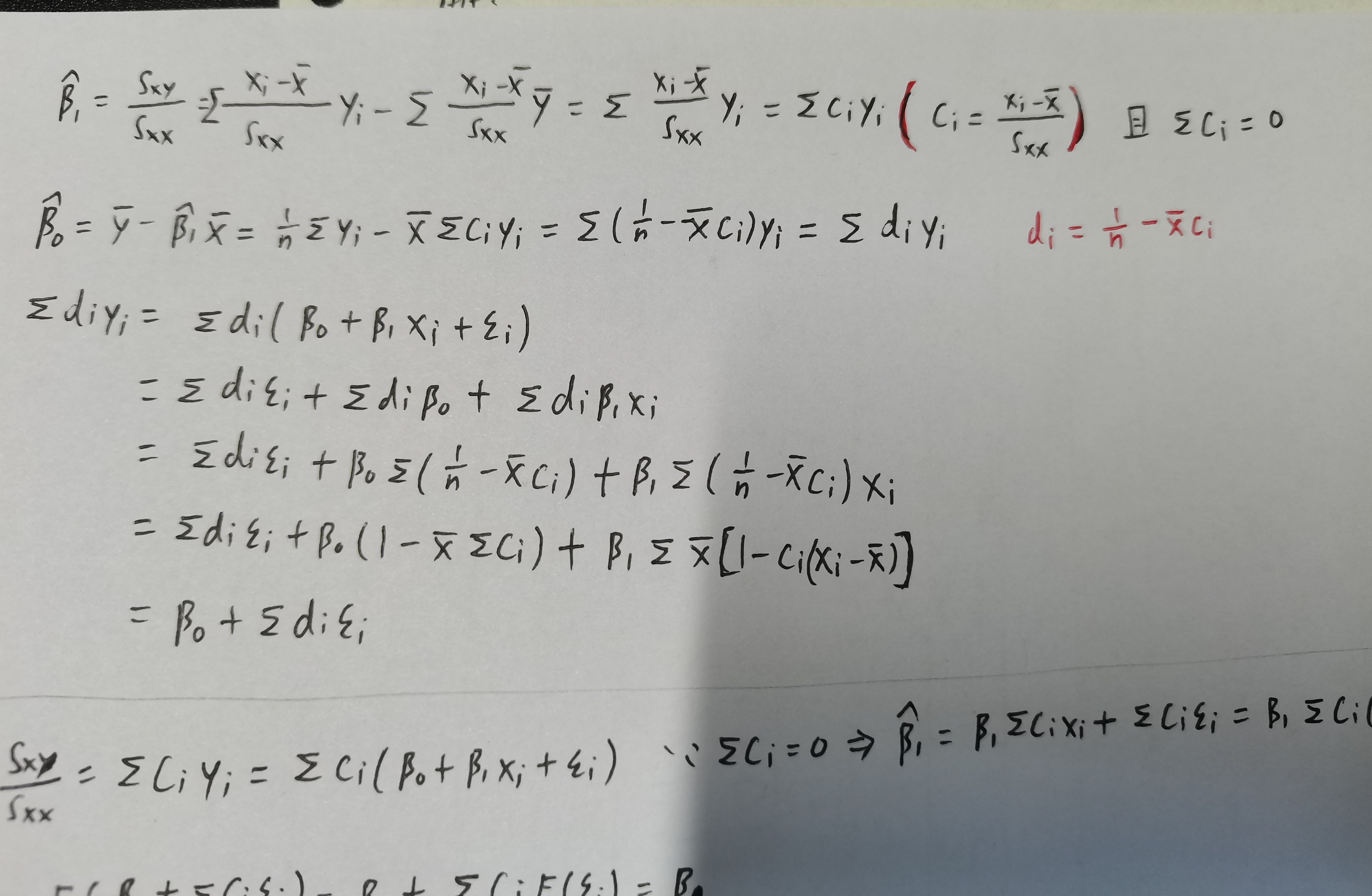
- OLS是无偏估计
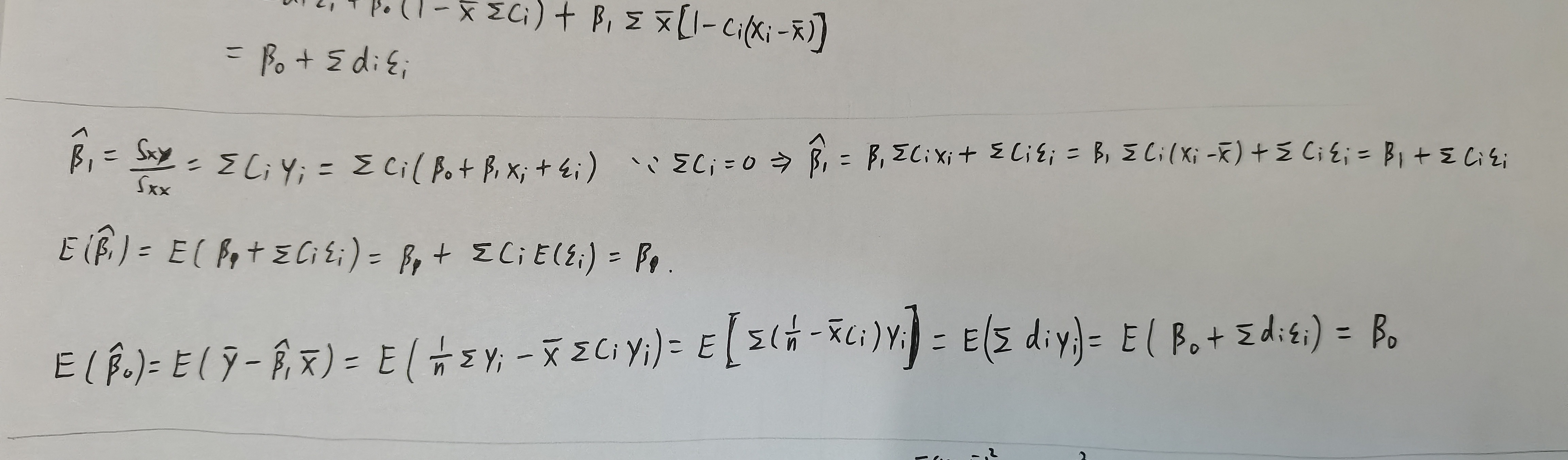
- LS估计的方差可计算为
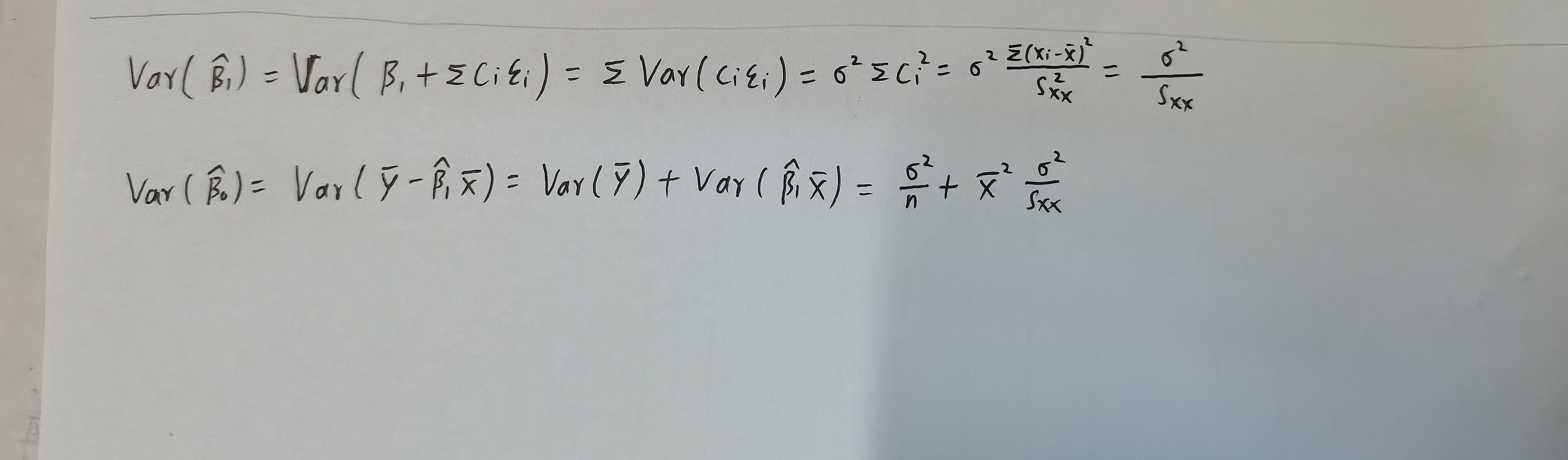
随机误差方差的 \(\sigma^2\) 估计
均方误差
\[\begin{array} aMSE(\theta)=E(\hat{\theta}-\theta)^2=E(\hat{\theta}-E(\hat{\theta})+E(\hat{\theta})-\theta)^2=Var(\hat{\theta})+(bias(\hat{\theta}))^2\\
bias(\hat{\theta})=E(\hat{\theta})-\theta\end{array}\]
定义
\[S S_{\text {Res }}=\sum_{i=1}^{n} e_{i}^{2}=\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}=\sum_{i=1}^{n}\left(y_{i}-\hat{\beta}_{0}-\hat{\beta}_{1} x_{i}\right)^{2}
\]\[\hat{\sigma}^{2}=\frac{S S_{\text {Res }}}{n-2}=M S_{\text {Res }}
\]
在第三章我们将证明 \(E\left(\hat{\sigma}^{2}\right)=\sigma^{2}\)
参数估计的标准误
\[s.e.(\hat{\beta}_1)=\sqrt{\frac{\frac{S S_{\text {res }}}{n-2}}{S_{xx}}}
\]\[s.e.(\hat{\beta}_0)=\sqrt{\frac{\frac{S S_{\text {res }}}{n-2}}{n}+\bar{x}^2\frac{\frac{S S_{\text {res }}}{n-2}}{S_{xx}}}
\]
2.3
斜率与截距的假设检验
OLS 估计的抽样分布
\[\hat{\beta}_{1}=\sum_{i=1}^{n} c_{i} y_{i}=\beta_{1}+\sum_{i=1}^{n} c_{i} \epsilon_{i}, \quad \hat{\beta}_{0}=\sum_{i=1}^{n} d_{i} y_{i}=\beta_{0}+\sum_{i=1}^{n} d_{i} \epsilon_{i}
\]\[\hat{\beta}_{1}\sim N(\beta_1,\frac{\sigma^2}{S_{xx}})~,~ ~ \hat{\beta}_{0}\sim N(\beta_0,\bar{x}^2\frac{\sigma^2}{S_{xx}})
\]
t 检验
由于
\[t_{0}=\frac{\hat{\beta}_{1}-\beta_{10}}{\hat{\sigma} / \sqrt{S_{x x}}}=\frac{\hat{\beta}_{1}-\beta_{10}}{\hat{\sigma} / \sqrt{S_{x x}}} \frac{\sigma}{\hat{\sigma}}=\frac{Z_{0}}{\sqrt{\frac{SS_{\text {res }}}{(n-2) \sigma^{2}}}}=Z_{0} / \sqrt{\frac{M S_{\text {res }}}{\sigma^{2}}} \sim t(n-2)
\]因此,为了检验两变量间是否有线性关系,将假设斜率 \(\beta_{10}=0\)
t检验统计量为
\[t=\frac{\hat{\beta}_1}{\hat{\sigma}/\sqrt{S_{xx}}}=\frac{\hat{\beta}_1}{s.e.(\hat{\beta}_1)}={\hat{\beta}_1}/{\sqrt{\frac{\frac{S S_{\text {res }}}{n-2}}{S_{xx}}}}
\]
p 值
\[pvalue=P(|t_{n-2}|>|\frac{\hat{\beta}_1}{s.e.(\hat{\beta}_1)}|)
\]
区间估计
参数的置信区间
\(\beta_0~\beta_1\)的置信区间
\[\frac{\hat{\beta}_{1}-\beta_{1}}{s . e .\left(\hat{\beta}_{1}\right)} \sim t({n-2}), \quad \frac{\hat{\beta}_{0}-\beta_{0}}{s . e .\left(\hat{\beta}_{0}\right)} \sim t({n-2})
\]可得 \(\beta_{i}\) 的 \(1-\alpha\) 置信区间为
\[\hat{\beta}_{i} \pm t_{n-2}(1-\alpha / 2) * \text { s.e. }\left(\hat{\beta}_{i}\right)
\]
响应变量均值 \(E(y|x_0)\) 的估计和置信区间
\(\because\)
\(E\left(y \mid x_{0}\right)=\beta_{0}+\beta_{1} x_{0}\)
\(\therefore\)
\(\hat{\mu}_{y \mid x_{0}}=\hat{\beta}_{0}+\hat{\beta}_{1} x_{0}=\bar{y}+\hat{\beta}_{1}\left(x_{0}-\bar{x}\right)\)
而且
\[Var\left(y \mid x_{0}\right)=\sigma^2({\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}})
\]
可知
\[\frac{\hat{\mu}_{y \mid x_{0}}-\mu_{y \mid x_{0}}}{\hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}}} \sim t({n-2})
\]
所以\(E(y|x_0)\) 的置信区间
\[\hat{\mu}_{y \mid x_{0}}\pm t_{n-2}(1-\alpha/2)\hat{\sigma} \sqrt{\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}}
\]
新观测的预测
预测误差为
\[\begin{aligned}\psi&=y_{0}-\hat{y}_{0}\\
&=\beta_{0}+\beta_{1} x_{0}+\epsilon_{0}-(\hat{\beta}_{0}+\hat{\beta}_{1} x_{0})\\
&=(\beta_{0}-\hat{\beta}_{0})+(\beta_{1}-\hat{\beta}_{1}) x_{0}+\epsilon_{0}
\end{aligned}\]
预测方差为
\[\begin{aligned}\operatorname{Var}(\psi)&=\operatorname{Var}(y_{0}-\hat{y}_{0})\\
&=\operatorname{Var}(\hat{\beta}_{0}+\hat{\beta}_{1} x_{0}+\epsilon_{0})\\
&=\sigma^2(1+\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}})
\end{aligned}\]
因此有
\[\frac{\psi-E(\psi)}{\sqrt{\operatorname{Var}(\psi)}}=\frac{y_{0}-\hat{y}_{0}}{\sigma \sqrt{1+\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}}} \sim N(0,1)
\]
所以
\[\frac{y_{0}-\hat{y}_{0}}{\hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}}} \sim t_{n-2}
\]
于是可得 \(1-\alpha\) 预测区间为
\[\hat{y}_{0} \pm t_{n-2}(1-\alpha / 2) \hat{\sigma} \sqrt{1+\frac{1}{n}+\frac{\left(x_{0}-\bar{x}\right)^{2}}{S_{x x}}}
\]
决定系数 \(R^2\)
可以定义
\[\begin{aligned}
S S_{\text {total }}&=\sum_{i=1}^{n}\left(y_{i}-\bar{y}\right)^{2}\\
&=\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}+\hat{y}_{i}-\bar{y}\right)^{2}\\
&=\sum_{i=1}^{n}\left(y_{i}-\hat{y}_{i}\right)^{2}+\sum_{i=1}^{n}\left(\hat{y}_{i}-\bar{y}\right)^{2}+2 \sum_{i=1}^{n} e_{i}\left(\hat{y}_{i}-\bar{y}\right) \triangleq \text { SSres }+\text { SSreg }
\end{aligned}\]
\[R^{2}=\frac{SS_{reg}}{SS_T}=\frac{S S_{t o t a l}-S S_{r e s}}{S S_{t o t a l}}
\]表明了 y 的样本变异中被 x 解释了的部分
可以推导出下列结论
\[R^{2}=\frac{\hat{\beta}_{1}^{2}}{\hat{\beta}_{1}^{2}+\frac{n-2}{n-1} \cdot \frac{\hat{\sigma}^{2}}{\hat{\sigma}_{x}^{2}}}
\]因此 \(R^{2}\) 较大, 并不意味着斜率 \(\hat{\beta}_{1}\) 就较大;
- 应该谨慎地解释和使用 \(R^{2}\) 。在实际问题里, \(R^{2}\) 作为模型拟合优 度的度量是有缺陷的, 一个典型的问题是, 在多元线性回归模型 里, 加人一个变量总会使得 \(R^{2}\) 升高, 因此用它做标准选择模型 的话, 总是会选取一个最复杂的模型。
- 若 \(R^{2}=1\) ,则完美拟合
- 若 \(R^{2}=0\) ,则两变量无关系
回归分析-2.X 简单线性回归的更多相关文章
- Python回归分析五部曲(一)—简单线性回归
回归最初是遗传学中的一个名词,是由英国生物学家兼统计学家高尔顿首先提出来的,他在研究人类身高的时候发现:高个子回归人类的平均身高,而矮个子则从另一方向回归人类的平均身高: 回归分析整体逻辑 回归分析( ...
- SPSS数据分析—简单线性回归
和相关分析一样,回归分析也可以描述两个变量间的关系,但二者也有所区别,相关分析可以通过相关系数大小描述变量间的紧密程度,而回归分析更进一步,不仅可以描述变量间的紧密程度,还可以定量的描述当一个变量变化 ...
- day-12 python实现简单线性回归和多元线性回归算法
1.问题引入 在统计学中,线性回归是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析.这种函数是一个或多个称为回归系数的模型参数的线性组合.一个带有一个自变 ...
- sklearn学习笔记之简单线性回归
简单线性回归 线性回归是数据挖掘中的基础算法之一,从某种意义上来说,在学习函数的时候已经开始接触线性回归了,只不过那时候并没有涉及到误差项.线性回归的思想其实就是解一组方程,得到回归函数,不过在出现误 ...
- 机器学习与Tensorflow(1)——机器学习基本概念、tensorflow实现简单线性回归
一.机器学习基本概念 1.训练集和测试集 训练集(training set/data)/训练样例(training examples): 用来进行训练,也就是产生模型或者算法的数据集 测试集(test ...
- 机器学习(2):简单线性回归 | 一元回归 | 损失计算 | MSE
前文再续书接上一回,机器学习的主要目的,是根据特征进行预测.预测到的信息,叫标签. 从特征映射出标签的诸多算法中,有一个简单的算法,叫简单线性回归.本文介绍简单线性回归的概念. (1)什么是简单线性回 ...
- 机器学习——Day 2 简单线性回归
写在开头 由于某些原因开始了机器学习,为了更好的理解和深入的思考(记录)所以开始写博客. 学习教程来源于github的Avik-Jain的100-Days-Of-MLCode 英文版:https:// ...
- R 语言中的简单线性回归
... sessionInfo() # 查询版本及系统和库等信息 getwd() path <- "E:/RSpace/R_in_Action" setwd(path) rm ...
- 简单线性回归(梯度下降法) python实现
grad_desc .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bord ...
- 简单线性回归(最小二乘法)python实现
简单线性回归(最小二乘法)¶ 0.引入依赖¶ In [7]: import numpy as np import matplotlib.pyplot as plt 1.导入数据¶ In [ ...
随机推荐
- [深度学习] tf.keras入门2-分类
目录 Fashion MNIST数据库 分类模型的建立 模型预测 总体代码 主要介绍基于tf.keras的Fashion MNIST数据库分类, 官方文档地址为:https://tensorflow. ...
- [编程基础] C++多线程入门10-packaged_task示例
原始C++标准仅支持单线程编程.新的C++标准(称为C++11或C++0x)于2011年发布.在C++11中,引入了新的线程库.因此运行本文程序需要C++至少符合C++11标准. 文章目录 10 pa ...
- Springcloud源码学习笔记1—— Zuul网关原理
系列文章目录和关于我 源码基于 spring-cloud-netflix-zuul-2.2.6.RELEASE.jar 需要具备SpringMVC源码功底 推荐学习https://www.cnblog ...
- SwiftUI(一)
macOS 11.4 Xcode 12.5.1 1.新建工程,创建一个swiftui文件 2.创建后有些画布是在下面显示的 3.先来看下效果图 4. CardImageView.swi ...
- 【学习笔记】QT从入门到实战完整版(按钮和信号槽)(1)
介绍说明 学习 QT 的目的只是为了可以实现跨平台的具有GUI 的程序,以前用的 MFC,但是无法应用在嵌入式平台.后来在全志的 Tina 系统中有看到 QT ,因此特地去了解了QT,挺有意思的,UI ...
- Cpp 友元简述
友元函数,友元类 使用友元,主要是易于直接访问数据,但友元本质是以破坏封装性为代价. 下例引用于: <C++程序设计(第2版)> 友元声明位置由程序设计者决定,且不受类中public.pr ...
- spring-in-action-day05-REST
1.创建RESTFUL端点 (1)创建get端点 (2)创建post端点 (3)创建put/patch端点 (4)创建delete端点 2.启用超媒体 3.消费REST端点 3.1使用RestTemp ...
- RabbitMQ.Client.Exceptions.BrokerUnreachableException:“None of the specified endpoints were reachabl
1.问题复现 RabbitMQ新建账户进行具体操作时报如题错误,没有一个指定的端点是可到达的 2.解决办法 ① 控制台命令进入sbin所在文件夹 ② 输入命令设置权限 rabbitmqctl set_ ...
- 2021级《JAVA语言程序设计》上机考试试题10
教学副院长功能页 <%@ page language="java" contentType="text/html; charset=UTF-8" page ...
- Vue3从基础到精通
目录 一.Vue3介绍 1. Vue3的变化 2. Vue2和Vue3的不同之处 二.Vue3创建项目 1.用vue-lci创建步骤 2.用vite创建步骤 三.setup函数 四.ref.react ...