ElasticSearch 实现分词全文检索 - 概述
需求
做一个类似百度的全文搜索功能

所用的技术如下:
- ElasticSearch
- Kibana 管理界面
- IK Analysis 分词器
- SpringBoot
ElasticSearch 简介
ES 是一个使用Java语言并且基于Lucene编写的搜索引擎框架,他提供了分布式的全文搜索功能,提供了一个统一的基于Restful风格的WEB接口,官方客户端也对多种语言都提供了相应的API。
Lucene:Lucene本身就是一个搜索引擎的底层
分布式:ES主要是为了突出他的横向扩展能力。
全文检索:将一段词语进行分词,并且将分出来的单个词语统一放到一个分词库中,在搜索时,根据关键字去分词库中检查,找到匹配的内容。(倒排索引)
Restful 风格的WEB接口:操作ES很简单,只需要发送一个HTTP请求,并且根据请求方式的不同,携带参数,执行相应的功能。
应用广泛:Github, wiki, gold man 用ES每天维护将近10TB的数据。
ES 结构

索引
ES的服务中,可以创建多个索引,每个索引默认被分成5个分片存储(提高查询效率、存储容量),每个分片至少有一个备份分片
备份分片默认不会分担查询效率,当ES检索压力特别大的时候,备份分片才会帮助检索数据
备份的分片必须放在不同的服务器中(集群)

类型
索引可以分多个分版 ,每个分片中有多个type,ES版本不同,类型的创建也不同
7.x 默认不再支持自定投索引类型(默认类型为_doc)

文档
一个type又可以分多个 document 文档 (一个个文档,相当于RDB中的一行行数据),每个文档中有多个field属性
一个MySQL有多个数据库,一个库中有多个表,一张表中存放着多行数据,每行数据中分多个列

列
一个文档包括多个属性,相当于RDB中的字段

ES和Slor
Slor 在查询死数据时(不能改变的数据,不增加、不减少),速度相对ES更快一些。但是数据如果是实时改变时,Solr的查询速度会降低很多,ES的查询效率基本没有变化。
Solr搭建集群时,需要依赖Zookeeper来帮助管理。ES本身就支持集群的搭建,不需要第三方的介入
Solr针对国内的中文文档不多,ES社区火爆,文档健全
ES 对现在云计算和大数据支持特别好
倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。
当用户去查询数据时,会将用户的查询关键字进行分词
然后去分词库中匹配内容,最终得到数据的ID标识
根据ID标识去存放数据的位置拉取到指定的数据
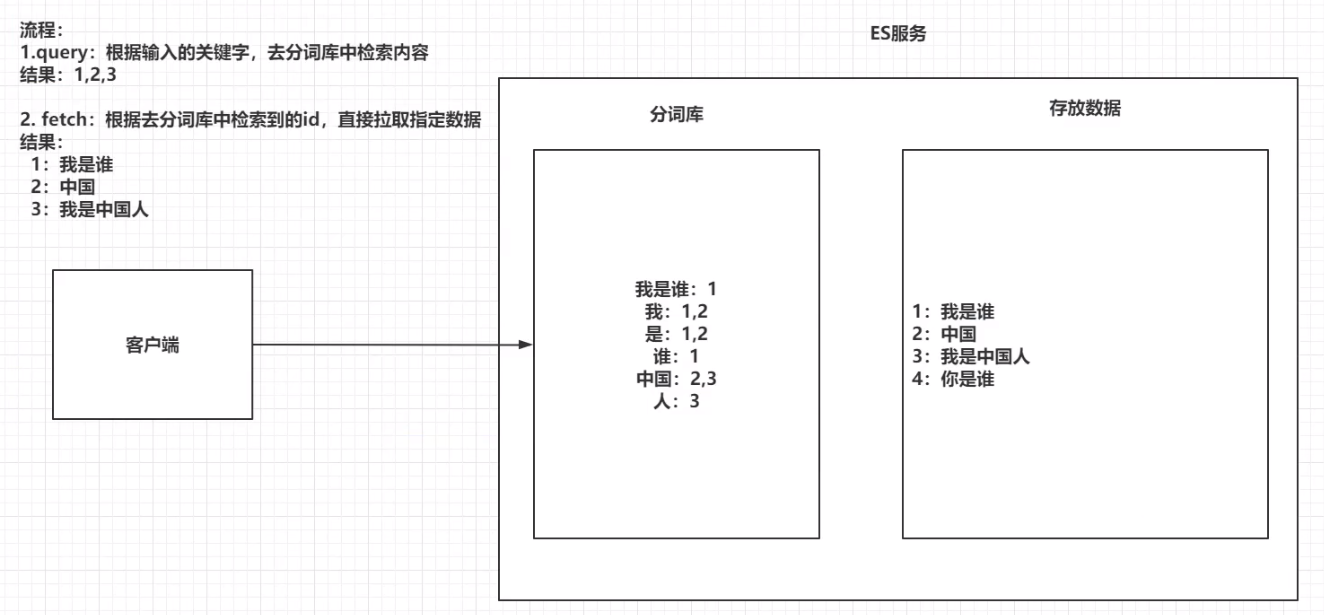
全文检索流程

- 创建ES索引、设置需要分词查询的 field
- 可以通过 canal 对 MySQL binlog 进行数据同步,或者 flink 或者 SpringBoot 直接往ES里添加数据
- 根据业务需求,通过 SpringBoot 进行查询
ElasticSearch 实现分词全文检索 - 概述的更多相关文章
- PHP+mysql数据库开发搜索功能:中英文分词+全文检索(MySQL全文检索+中文分词(SCWS))
PHP+mysql数据库开发类似百度的搜索功能:中英文分词+全文检索 中文分词: a) robbe PHP中文分词扩展: http://www.boyunjian.com/v/softd/robb ...
- ElasticSearch中文分词(IK)
ElasticSearch常用的很受欢迎的是IK,这里稍微介绍下安装过程及测试过程. 1.ElasticSearch官方分词 自带的中文分词器很弱,可以体检下: [zsz@VS-zsz ~]$ c ...
- 实战ELK(8) 安装ElasticSearch中文分词器
安装 方法1 - download pre-build package from here: https://github.com/medcl/elasticsearch-analysis-ik/re ...
- Elasticsearch 中文分词(elasticsearch-analysis-ik) 安装
由于elasticsearch基于lucene,所以天然地就多了许多lucene上的中文分词的支持,比如 IK, Paoding, MMSEG4J等lucene中文分词原理上都能在elasticsea ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- elasticsearch 拼音+ik分词,spring data elasticsearch 拼音分词
elasticsearch 自定义分词器 安装拼音分词器.ik分词器 拼音分词器: https://github.com/medcl/elasticsearch-analysis-pinyin/rel ...
- elasticsearch 中文分词(elasticsearch-analysis-ik)安装
elasticsearch 中文分词(elasticsearch-analysis-ik)安装 下载最新的发布版本 https://github.com/medcl/elasticsearch-ana ...
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
随机推荐
- 如何通过 C#/VB.NET 将 PDF 转为 Word
众所周知,PDF 文档支持特长文件,集成度和安全可靠性都较高,可有效防止他人对 PDF 内容进行更改,所以在工作中深受大家喜爱.但是在工作中,我们不可避免的会对 PDF 文档进行修改或再编辑,这时我们 ...
- 小技巧 EntityFrameworkCore 实现 CodeFirst 通过模型生成数据库表时自动携带模型及字段注释信息
今天分享自己在项目中用到的一个小技巧,就是使用 EntityFrameworkCore 时我们在通过代码去 Update-Database 生成数据库时如何自动将代码模型上的注释和字段上的注释携带到数 ...
- pytest.ini配置文件格式
[pytest] # 命令行参数,用空格分隔 addopts = -v -n=2 # 配置测试用例所在文件夹 testpaths = ./pytest_1 # 配置需要执行的模块文件名称 python ...
- uniapp 微信小程序 改变头部的信号、时间、电池显示颜色
修改前 修改后 修改方法:"navigationBarTextStyle":"white"
- 中国蚁剑 - AntSword
中国蚁剑 - AntSword 中国蚁剑是一种跨平台操作工具,它主要提供给用户用于有效的网络渗透测试以及进行正常运行的网站. 否则任何人不得将网站用于其无效用途以及可能的等目的.自己承担并追究其相关责 ...
- 基本能看懂的C编译器,只有365行!
Fabrice Bellard is a French computer programmer known for writing FFmpeg, QEMU, and the Tiny C Compi ...
- [常用工具] C++环境下Qt的安装
文章目录 1 Qt(C++)版本的选择 2 Qt 安装 2.1 Qt 6.3.1的安装 2.2 Qt 5.14.2的安装 3 Qt 其他版本安装 1 Qt(C++)版本的选择 Qt(C++)是一个跨平 ...
- idea的简单介绍
上一篇博客中只是了解一下java文件是怎么编译的,但是一般来说大家都是使用编程软件来进行开发,我是使用IntelliJ IDEA进行开发的 官网下载IDEA(自行安装哈):地址:https://www ...
- [cocos2d-x]关于菜单项
菜单项的分类 MenuItem:菜单项类,它是一个虚基类,因此必须实现它的子类,再把子类对象赋给父类指针. MenuItemFont:字体菜单项. MenuItemAtlasFont:字体菜单项,和第 ...
- pycharm下载 安装使用
pycharm下载与使用 1.下载 该软件分免费版和收费版 免费版(community):功能少 收费版(professional):30天试用 我们尽量使用收费版本 官网地址:h ...