Dropout原理分析
工作流程
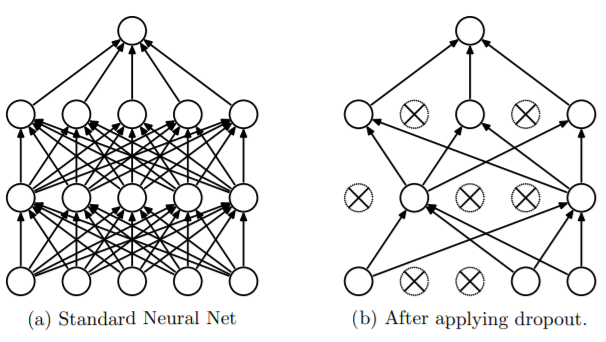
dropout用于解决过拟合,通过在每个batch中删除某些节点(cell)进行训练,从而提高模型训练的效果。
通过随机化一个伯努利分布,然后于输入y进行乘法,将对应位置的cell置零。然后y再去做下一层的前向传播。
r_{j}^{(l)} & \sim \operatorname{Bernoulli}(p) \\
\widetilde{\mathbf{y}}^{(l)} &=\mathbf{r}^{(l)} * \mathbf{y}^{(l)} \\
z_{i}^{(l+1)} &=\mathbf{w}_{i}^{(l+1)} \widetilde{\mathbf{y}}^{l}+b_{i}^{(l+1)} \\
y_{i}^{(l+1)} &=f\left(z_{i}^{(l+1)}\right)
\end{aligned}
\]
这里由于部分cell的缺失,会导致下一层的cell的值偏小,假设一个cell有p的概率被抹除,那么他在网络中发生作用的数学期望是:
E = (1 - p) * x
\]
所以真正用于网络计算的x的大小只有(1-p)x,而在训练时,dropout会被关闭,所有的cell都会被用于计算(为了避免预测结果的随机性,所以不能有dropout这种随机结构参与运算),相对来说,由于所有的cell都参与了运算,那么下一层的值会更大。为了抵消这种差距,在测试时用 \((1-p)x\) 进行计算。这样cell传递到下一层时,可以使下一层和train时保持在同一个量级上。
如果不想在预测时把x乘上(1-p),我们可以在训练时把x进行缩放。即 \(\frac{x}{(1-p)}\),这样在预测时就可以直接用x进行运算,而不用改变x的值。这种方式也被称为 iverse dropout。
实现:
#dropout函数的实现
def dropout(x, level):
import numpy as np
if level < 0. or level >= 1: #level是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
#我们通过binomial函数,生成与x一样的维数向量。binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
#硬币 正面的概率为p,n表示每个神经元试验的次数
#因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
sample=np.random.binomial(n=1,p=retain_prob,size=x.shape)#即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print(sample)
x *=sample#0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0
x /= retain_prob
return x
#对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
为什么可以解决过拟合
dropout通过随机去除cell,使得网络的结果在不断的变化当中。可以认为,最后的模型是在多个模型的基础上综合起来的模型。在处理过拟合问题的时候,常常使用多个模型训练一份数据,最后通过“投票”或者取平均的方式来预测,可以降低过拟合的影响。而dropout的这种“综合”的结果就类似多个模型共同来预测。
减少神经元之间的依赖关系。在神经网络中可能两个神经元相互依赖才能产生比较好的效果。比如一个cell很大而另一个很小,它们的组合却不影响最终的结果,但是这些cell学到的并不是正确的知识。
问题
在学习dropout的算法中关于drop的反向传播还有一些细节值得推敲。理论上来说,dropout是的效果是让一个cell在神经网络中消失,不管是前向传播还是反向传播,都要忽略这个cell的存在。但是关于dropout反向传播的具体操作众说纷纭。很难找到一个明确的说法。
- 由于cell已经被置零,所以在对下一层网络求导时,与之相连的权重的梯度都是零,所以下一层与之相连的权重都不会被更新。
- cell连接前后两个权重,虽然cell之后的权重可以自动根据cell的值来判断梯度。但是与cell相连的前面的权重就不可以这么做了,所以这些权重需要做一个判断,如果是与cell相连的权重,那么就抹除他的误差。
参考资料:
http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf
https://blog.csdn.net/program_developer/article/details/80737724
https://blog.csdn.net/oBrightLamp/article/details/84105097
Dropout原理分析的更多相关文章
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象.在训练神经网络的时候经常会遇到过拟合的问题, ...
- Hebye 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- Handler系列之原理分析
上一节我们讲解了Handler的基本使用方法,也是平时大家用到的最多的使用方式.那么本节让我们来学习一下Handler的工作原理吧!!! 我们知道Android中我们只能在ui线程(主线程)更新ui信 ...
- Java NIO使用及原理分析(1-4)(转)
转载的原文章也找不到!从以下博客中找到http://blog.csdn.net/wuxianglong/article/details/6604817 转载自:李会军•宁静致远 最近由于工作关系要做一 ...
- 原子类java.util.concurrent.atomic.*原理分析
原子类java.util.concurrent.atomic.*原理分析 在并发编程下,原子操作类的应用可以说是无处不在的.为解决线程安全的读写提供了很大的便利. 原子类保证原子的两个关键的点就是:可 ...
- Android中Input型输入设备驱动原理分析(一)
转自:http://blog.csdn.net/eilianlau/article/details/6969361 话说Android中Event输入设备驱动原理分析还不如说Linux输入子系统呢,反 ...
- 转载:AbstractQueuedSynchronizer的介绍和原理分析
简介 提供了一个基于FIFO队列,可以用于构建锁或者其他相关同步装置的基础框架.该同步器(以下简称同步器)利用了一个int来表示状态,期望它能够成为实现大部分同步需求的基础.使用的方法是继承,子类通过 ...
- Camel运行原理分析
Camel运行原理分析 以一个简单的例子说明一下camel的运行原理,例子本身很简单,目的就是将一个目录下的文件搬运到另一个文件夹,处理器只是将文件(限于文本文件)的内容打印到控制台,首先代码如下: ...
随机推荐
- Canvas 线性图形(四):矩形
函数 CanvasPath.rect(x, y, w, h) 参数名 类型 描述 x Number 矩形起始位置 y Number 矩形起始位置 w Number 矩形宽度 h Number 矩形高度 ...
- 自动化选课(Python + selenium
前几天听到朋友说自己选课事情,突发奇想想要搞这样一个东西,但是由于各种原因只做到以下的完成度,具体的情况也会在解释的最后留下.这个只适用于曲师大的教务系统,因为用的这个系统来进行的一个调试,对于其 ...
- Java源码分析 | CharSequence
本文基于 OracleJDK 11, HotSpot 虚拟机. CharSequence 定义 CharSequence 是 java.lang 包下的一个接口,是 char 值的可读序列, 即其本身 ...
- 【JDBC】学习路径8-连接池
为什么是连接池? 第一.受我们硬件资源的限制,我们的一些资源使用时有限制的比如我们的数据库 连接数和线程数.为了摆脱这些限制,我们就使用了池化技术来将这些资源限制在一定范围内. 第二.我们创建和销毁这 ...
- 如何将原生微信小程序页面改成原生VUE框架的H5页面
项目背景: 公司为了实现小程序与H5页面共同覆盖,全面推广.特此想将已有的小程序进行快速改造上线(二周内),研发出H5版本.目前公司前端技术较为薄弱,现有的技术解决方案还停留在JSP. 问题: 如何将 ...
- Java开发学习(三十二)----Maven多环境配置切换与跳过测试的三种方式
一.多环境开发 我们平常都是在自己的开发环境进行开发, 当开发完成后,需要把开发的功能部署到测试环境供测试人员进行测试使用, 等测试人员测试通过后,我们会将项目部署到生成环境上线使用. 这个时候就有一 ...
- Jmeter中的JSON提取器用法
一.使用前提 一般来说JSON提取器只适用于响应结果中返回的是json数据 二.需求 在下一个接口调用上一个接口的数据,如:请求1返回的结果,处理以后作为请求2的参数使用. 首先需要下载JSON Ex ...
- Kubernetes(K8S)是什么?
概述 Kubernetes,又称为 k8s(首字母为 k.首字母与尾字母之间有 8 个字符.尾字母为 s,所以简称 k8s)或者简称为 "kube" ,是一种可自动实施 Linux ...
- 2.1pip的安装和使用
我们都知道python有海量的第三方库或者说模块,这些库针对不同的应用,发挥不同的作用.我们在实际的项目中,或多或少的都要使用到第三方库,那么如何将他人的库加入到自己的项目中内呢? 打个电话?大哥你好 ...
- Dockerfile文件:设置变量启动的时候传递进去
from openjdk:8-jdk-alpine RUN ln -sf /usr/share/zoneinfo/Asia/shanghai /etc/localtime RUN echo 'Asia ...