Python数据科学手册-Numpy入门
通过Python有效导入、存储和操作内存数据的技巧
数据来源:文档、图像、声音、数值等等,将所有的数据简单的看做数字数组 非常有助于 理解和处理数据
不管数据是何种形式,第一步都是 将这些数据转换成 数值形式 的可分析数据。
Numpy Numerical Python 的简称,
- Numpy 数组和python内置的列表类型 非常相似,随着数组在维度上的变大,Numpy数组更高效
- 导入numpy
import numpy as np
- 理解Python中的数据类型
python易用之处在于动态输入,不需要声明变量类型,是动态推断的。可以将任何类型的数据指定给任何变量
事实就是:Python变量不仅是他们的值,还包括了值得类型 的一些额外信息,
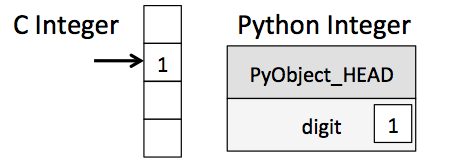
1)python的整型不仅仅是一个整型
标准的Python都是C语言编写的,每一个对象都是一个聪明的伪C语言结构体。该结构体包含其 值还有其他信息,
比如 x = 10000, x是一个指针,指向一个C语言的复合结构体。
查看 c语言 python安装目录\include\longintrepr.h
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
扩展之后
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
}
- ob_refcnt: 是一个引用计数,帮助python内存分配 回收
- ob_type: 变量的类型编码
- ob_size: 数据成员的大小
- ob_digit: python变量表示的实际整型值
因为python的动态类型特性,可以创建一个异构的列表
L = [ True, "2", 3.0, 4]
[type(item) for item in L]
输出:[bool, str, float, int]
灵活具有代价,列表中的每一项必须包含各自的类型信息,引用计数和其他信息。每一项都是一个完整的Python对象。
如果所有变量是同一类型,就有 冗余信息。
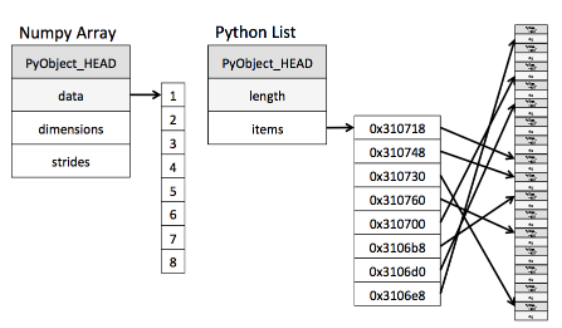
Python中固定类型数组
import array
A = array.array('i', [0,1,2])
A
输出:array('i', [0, 1, 2])
Numpy从Python列表创建数组
np.array([1,2,3,4,5])
输出:array([1, 2, 3, 4, 5])
必须是同一类型的数据。如果类型不匹配会自动向上转换,
明确设置数据类型,加参数dtype
np.array([1,2,3,4],dtype='float32')
输出:array([1., 2., 3., 4.], dtype=float32)
设置多为数组
np.array([list(range(i, i+3)) for i in [2,4,6]])
输出:array([[2, 3, 4],
[4, 5, 6],
[6, 7, 8]])
Numpy从头创建数组
# 创建一个长度为10的数组,数组的只都是0
np.zeros(10, dtype=int)
# 创建一个3*5 的浮点型数组,数组的值都是1
np.ones((3, 5), dtype=float)
# 创建一个3*5 的浮点型数组,数组的值都是4.14
np.full((3,5), 4.14)
# 创建一个线性序列, 从0 开始,到20 ,步长为2
np.arange(0, 20, 2)
# 创建一个5个元素的数组,五个数均匀的分配到0-1
np.linspace(0,1,5)
np.linspace(0,2,5)
# 创建一个3*3的、在0-1均匀分布的随机数组组成的数组
np.random.random((3, 3))
# 创建一个3*3 均值为0,标准差为1 的正态分布的随机数 数组
np.random.normal(0,1,(3,3))
# 创建一个 3*3, [0,10) 区间的随机整型数组
np.random.randint(0, 10, (3, 3))
# 创建一个3 *3 的单位矩阵
np.eye(3)
# 创建三个整型数 组成的 未初始化的数组,初始值是内存空间任意值
np.empty(3)
Numpy标准数据类型
| Data type | Description |
|---|---|
| bool_ | Boolean (True or False) stored as a byte |
| int_ | Default integer type (same as C long; normally either int64 or int32) |
| intc | Identical to C int (normally int32 or int64) |
| intp | Integer used for indexing (same as C ssize_t; normally either int32 or int64) |
| int8 | Byte (-128 to 127) |
| int16 | Integer (-32768 to 32767) |
| int32 | Integer (-2147483648 to 2147483647) |
| int64 | Integer (-9223372036854775808 to 9223372036854775807) |
| uint8 | Unsigned integer (0 to 255) |
| uint16 | Unsigned integer (0 to 65535) |
| uint32 | Unsigned integer (0 to 4294967295) |
| uint64 | Unsigned integer (0 to 18446744073709551615) |
| float_ | Shorthand for float64. |
| float16 | Half precision float: sign bit, 5 bits exponent, 10 bits mantissa |
| float32 | Single precision float: sign bit, 8 bits exponent, 23 bits mantissa |
| float64 | Double precision float: sign bit, 11 bits exponent, 52 bits mantissa |
| complex_ | Shorthand for complex128. |
| complex64 | Complex number, represented by two 32-bit floats |
| complex128 | Complex number, represented by two 64-bit floats |
Numpy数组基础
Python中的数据操作几乎等同于Numpy数组操作,学习获取数据 子数组, 对数组进行分裂,变形, 连接
- 数组的属性
确定数组的大小、形状、存储大小、数据类型 - 数组的索引
获取和实则数组各个元素的值 - 数组的变形
改变给定数组的形状 - 数组的拼接和分裂
将多个数组合并为一个,将一个数组分裂成多个
Numpy数组的属性
- 每个数组有 ndim(数组的维度)、 shape(每个维度的大小)、size(数组的总大小)、dtype(数据类型)、itemsize(每个元素的字节大小) 、 nbytes(数组总字节大小)
np.random.seed(0) # 设置随机数种子
x1 = np.random.randint(10, size=6) # 一维数组 array([5, 0, 3, 3, 7, 9])
x2 = np.random.randint(10, size=(3, 4)) # 二维数组 array([[3, 5, 2, 4], [7, 6, 8, 8],[1, 6, 7, 7]])
x3 = np.random.randint(10, size=(3,4,5)) # 三维数组
print(f"x1 nidim: {x1.ndim} , shape: {x1.shape}, size: {x1.size} ")
print(f"x2 nidim: {x2.ndim} , shape: {x2.shape}, size: {x2.size} ")
print(f"x3 nidim: {x3.ndim} , shape: {x3.shape}, size: {x3.size} ")
print(f"x1 dtype: {x1.dtype}")
print(f"x1 itemsize: {x1.itemsize}")
print(f"x1 nbytes: {x1.nbytes}")
# 输出如下
x1 nidim: 1 , shape: (6,), size: 6
x2 nidim: 2 , shape: (3, 4), size: 12
x3 nidim: 3 , shape: (3, 4, 5), size: 60
x1 dtype: int32
x1 itemsize: 4
x1 nbytes: 24
数组索引:获取单个元素
索引:从0开始计数
print(x1)
# 第0个元素
x1[0]
# 最后一个元素
x1[-1]
# 多维数组,用逗号分割
print(x2)
x2[0,0]
print(x2[1, 1])
数组切片:获取子数组
就是python里的切片 slice 符号 :
x[start:stop:step]
- 一维子数组
# 一维子数组
x = np.arange(10)
print(x)
x[:5] # 前五个元素
x[5:] # 索引5开始及以后的元素
x[4:7] # 索引4 5 6 的元素, 左闭右开
x[::2] # 每隔一个元素
# 步长值为负数,就是start 和 stop交换。
x[::-1] # 逆序
x[9:5:-1]
# 输出
[0 1 2 3 4 5 6 7 8 9]
array([0, 1, 2, 3, 4])
array([9, 8, 7, 6]) # x[9:5:-1] 的额输出
- 多维子数组,
也是通过逗号 分割。
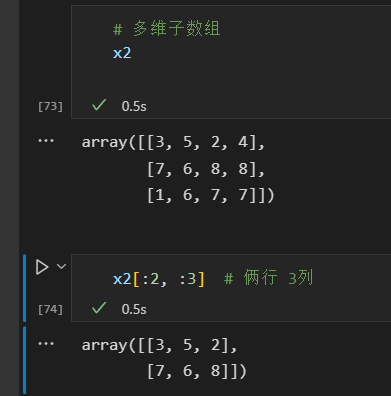
获取数组的行 和 列
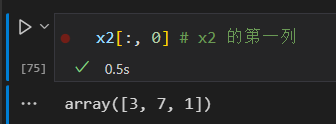
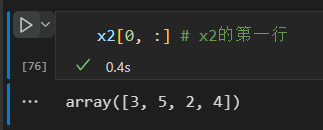
注意:数组切片返回的是数组数据的视图,修改子数组,原来的数组也会被修改。
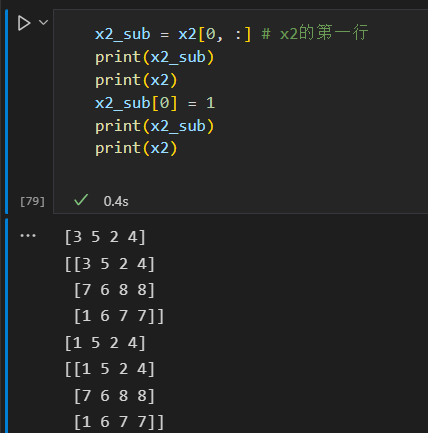
如果要复制,使用copy()方法实现

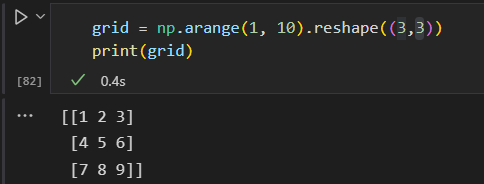
数组的变形
reshape()函数
将1-9 放入一个3*3的矩阵
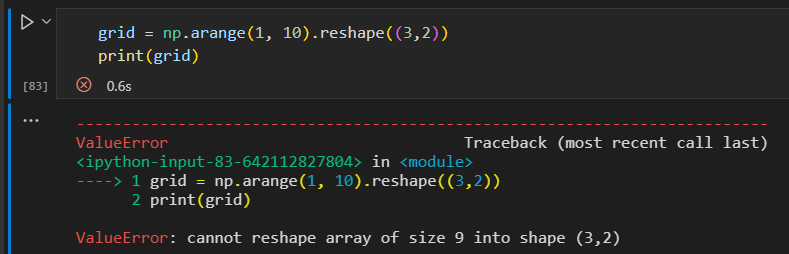
原始数组的大小必须和变形后的数组大小一致
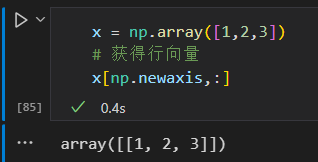
将一个一维数组转变为二维的行或列的矩阵
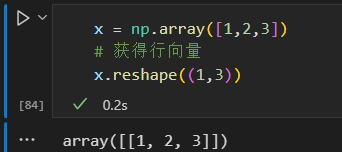
使用newaxis
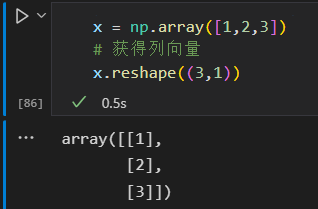
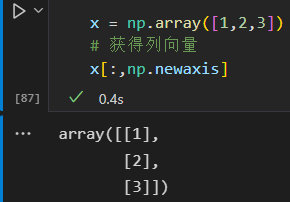
获得列向量
数组拼接和分裂
将多个数组合并为一个,或将一个数组分裂成多个
- 数组的拼接
np.concatenate np.vstack np.hstack
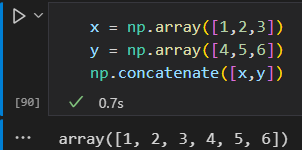
二维数组的拼接
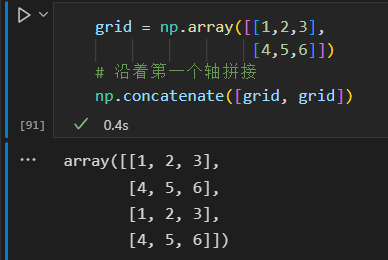
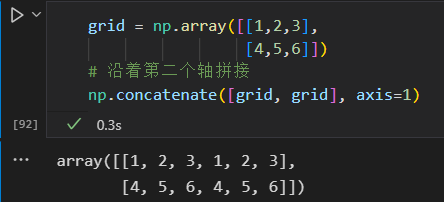
第二个轴
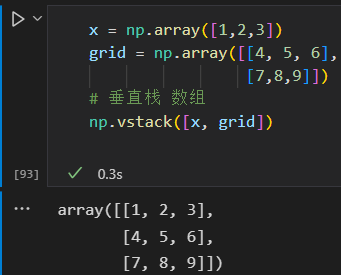
沿着固定维度处理数组时,使用np.vastack(垂直栈)和 np.hstack(水平栈)函数更简洁
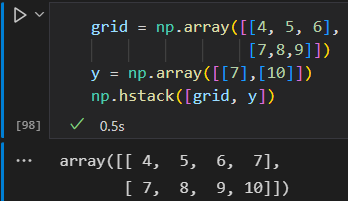
ps:必须一致。
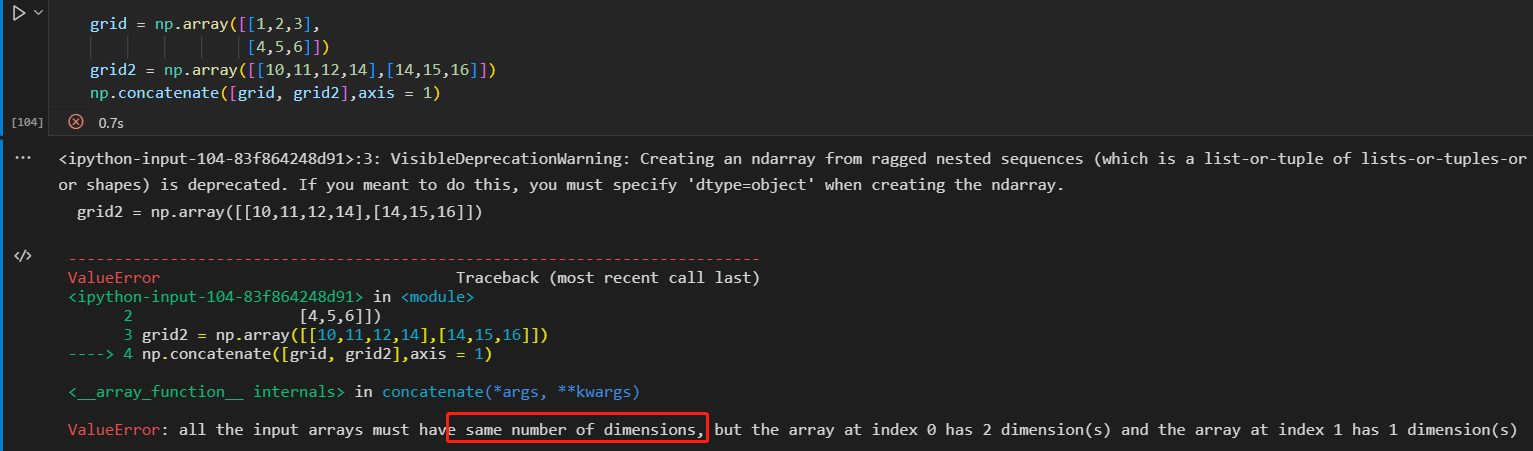
np.dstack 沿着第三个维度拼接数组
- 数组的分裂
np.split np.hsplit np.vsplit
传递参数可以是索引列表,索引列表记录的是分裂点位置

使用axis参数
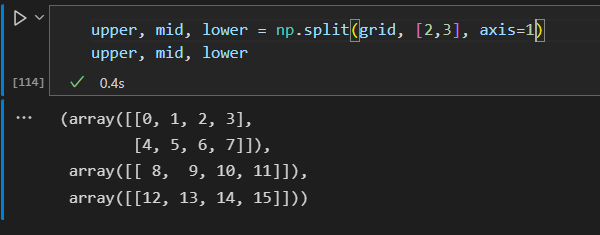
N个分裂点会得到N+1个子数组
np.vsplit 垂直分割
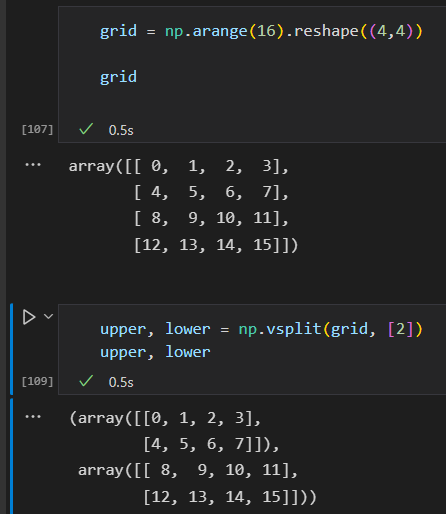
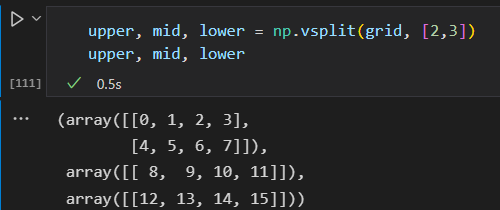
np.hsplit 水平分割
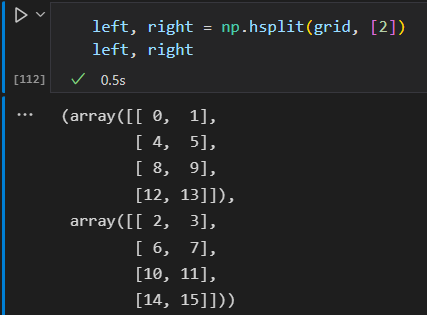
同样,np.dsplit 第三个维度分裂。
Python数据科学手册-Numpy入门的更多相关文章
- Python数据科学手册-Numpy的结构化数组
结构化数组 和 记录数组 为复合的.异构的数据提供了非常有效的存储 (一般使用pandas 的 DataFrame来实现) 传入的dtpye 使用 Numpy数据类型 Character Descri ...
- Python数据科学手册-Numpy数组的排序
1) Numpy中的快速排序: np.sort 和 np.argsort np.sort 是快速排序,算法复杂度 O[ N log N] ,也可以选择归并排序和堆排序 如果不想修改原始输入数组,返 ...
- Python数据科学手册-Numpy数组的计算:比较、掩码和布尔逻辑,花哨的索引
Numpy的通用函数可以用来替代循环, 快速实现数组的逐元素的 运算 同样,使用其他通用函数实现数组的逐元素的 比较 < > 这些运算结果 是一个布尔数据类型的数组. 有6种标准的比较操作 ...
- Python数据科学手册-Numpy数组的计算,通用函数
Python的默认实现(CPython)处理某些操作非常慢,因为动态性和解释性, CPython 在每次循环必须左数据类型的检查和函数的调度..在编译是进行这样的操作.就会加快执行速度. 通用函数介绍 ...
- Python数据科学手册-Numpy数组的计算:广播
广播可以简单理解为用于不同大小数组的二元通用函数(加减乘等)的一组规则 二元运算符是对相应元素逐个计算 广播允许这些二元运算符可以用于不同大小的数组 更高维度的数组 更复杂的情况,对俩个数组的同时广播 ...
- 《Python数据科学手册》
<Python数据科学手册>[美]Jake VanderPlas著 陶俊杰译 Absorb what is useful, discard what is not, and add wh ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- 学习《Python数据科学手册》高清中文PDF+高清英文PDF+代码
如果有一定的数据分析与机器学习理论与实践基础,<Python数据科学手册>这本书是绝佳选择. 是对以数据深度需求为中心的科学.研究以及针对计算和统计方法的参考书.很友好实用,结构很清晰.但 ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
随机推荐
- java SWT中Label实时刷新当前时间
同样最近在开发swt的一个项目,业务中的一个功能模块类似百度网盘的上传进度条 0/80. 即已上传0个,总共80个.效果展示要的就是实时刷新,2/80呀,15/80呀,针对这个,就有了这篇文章. 下面 ...
- NC16649 [NOIP2005]校门外的树
NC16649 [NOIP2005]校门外的树 题目 题目描述 某校大门外长度为 \(L\) 的马路上有一排树,每两棵相邻的树之间的间隔都是 \(1\) 米.我们可以把马路看成一个数轴,马路的一端在数 ...
- gslb(global server load balance)技术的一点理解
gslb(global server load balance)技术的一点理解 前言 对于比较大的互联网公司来说,用户可能遍及海内外,此时,为了提升用户体验,公司一般会在离用户较近的地方建立机房,来服 ...
- 使用dnSpy对无源码EXE或DLL进行反编译并且修改
背景 总有一些特殊情况,我们没有源码,但是某个C#程序集dll或者可执行程序exe影响到我们代码的正常运行,我们希望得到源码,能改掉或者修改某些bug,但是苦于没有源码,这个时候可以用dnspy进行源 ...
- Node.js精进(7)——日志
在 Node.js 中,提供了console模块,这是一个简单的调试控制台,其功能类似于浏览器提供的 JavaScript 控制台. 本系列所有的示例源码都已上传至Github,点击此处获取. 一.原 ...
- PTA(BasicLevel)-1014 福尔摩斯的约会
一.问题描述 大侦探福尔摩斯接到一张奇怪的字条:我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm.大侦探很快就明 ...
- Tapdata 携手精诚瑞宝,共拓 Real Time DaaS 蓝海市场
2021年10月22日,深圳钛铂数据有限公司「Tapdata」 与精诚瑞宝计算机系统有限公司「精诚瑞宝」战略合作签约仪式在深圳举行,Tapdata 创始人唐建法先生与精诚瑞宝副总经理余灿雄先生签署 ...
- HashMap设计原理与实现(下篇)200行带你写自己的HashMap!!!
HashMap设计原理与实现(下篇)200行带你写自己的HashMap!!! 我们在上篇文章哈希表的设计原理当中已经大体说明了哈希表的实现原理,在这篇文章当中我们将自己动手实现我们自己的HashMap ...
- 使用JAVA CompletableFuture实现流水线化的并行处理,深度实践总结
大家好,又见面啦. 在项目开发中,后端服务对外提供API接口一般都会关注响应时长.但是某些情况下,由于业务规划逻辑的原因,我们的接口可能会是一个聚合信息处理类的处理逻辑,比如我们从多个不同的地方获取数 ...
- PHP正则替换函数收集
preg_replace() $msg = preg_replace("/<style>.+<\/style>/is", "", $ms ...