Java操作Hadoop、Map、Reduce合成
原始数据:
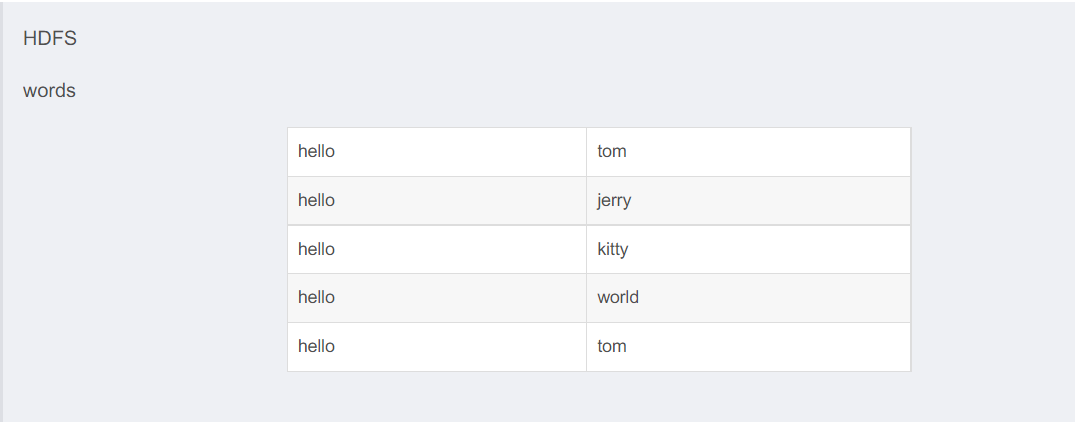
Map阶段
1.每次读一行数据,
2.拆分每行数据,
3.每个单词碰到一次写个1
<0, "hello tom">
<10, "hello jerry">
<22, "hello kitty">
<34, "hello world">
<46, "hello tom">
点击查看代码
/**
* @ClassName:WordCountReduce
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:55
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Text 数据类型:字符串类型 String
* IntWritable reduce阶段的输入类型 int
* Text reduce阶段的输出数据类型 String类型
* IntWritable 输出词频个数 Int型
* @author 暖阳
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* key 输入的 键
* value 输入的 值
* context 上下文对象,用于输出键值对
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context){
try {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("成功!!!");
}
}
}
reduce阶段
1.把单词对应的那些1
2遍历
3求和
<hello, {1,1,1,1,1}>
<jerry, {1}>
<kitty, {1}>
<tom, {1,1}>
<world, {1}>
点击查看代码
/**
* @ClassName:WordCountReduce
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:55
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Text 数据类型:字符串类型 String
* IntWritable reduce阶段的输入类型 int
* Text reduce阶段的输出数据类型 String类型
* IntWritable 输出词频个数 Int型
* @author 暖阳
*/
public class WordCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
/**
* key 输入的 键
* value 输入的 值
* context 上下文对象,用于输出键值对
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context){
try {
int sum=0;
for(IntWritable val:values){
sum+=val.get();
}
context.write(key,new IntWritable(sum));
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("成功!!!");
}
}
}
整合合并
点击查看代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @ClassName:WordCount
* @Description:TODO
* @author:Li Wei Ning
* @Date:2022/4/28 10:54
*/
public class WordCountTest {
public static void main(String[] args) {
try {
/*定义配置*/
Configuration config = new Configuration();
/* config.set("fs.defaultFS", "hdfs://192.168.47.128:9000");*/
/*定义一个工作任务,用于套接map和reduce两个阶段*/
Job job = Job.getInstance(config);
/* 定义工作任务用map*/
job.setMapperClass(WordCountMap.class);
/*定义map的输出key*/
job.setMapOutputKeyClass(Text.class);
/*定义map的输出value*/
job.setMapOutputValueClass(IntWritable.class);
/*定义map的文件路径*/
Path srcPath = new Path("C:/Users/暖阳/Desktop/123.txt");
/*定义map的输入文件*/
FileInputFormat.setInputPaths(job,srcPath);
/* 定义reduce用哪个类*/
job.setReducerClass(WordCountReduce.class);
/*指定reduce的输出key*/
job.setOutputKeyClass(Text.class);
/*指定reduce的输出value*/
job.setOutputValueClass(IntWritable.class);
/* 定义主类*/
job.setJarByClass(WordCountTest.class);
/*定义reduce的输出文件路径*/
Path outPath = new Path("C:/Users/暖阳/Desktop/WordCountTest");
/*输出最终结果文件路径*/
FileOutputFormat.setOutputPath(job, outPath);
/*提交job并关闭程序*/
System.exit(job.waitForCompletion(true) ? 0 : 1);
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("最终的");
}
}
}
输出结果
hello 5
jerry 1
kitty 1
tom 2
world 1
Java操作Hadoop、Map、Reduce合成的更多相关文章
- Hadoop Map/Reduce教程
原文地址:http://hadoop.apache.org/docs/r1.0.4/cn/mapred_tutorial.html 目的 先决条件 概述 输入与输出 例子:WordCount v1.0 ...
- 一步一步跟我学习hadoop(5)----hadoop Map/Reduce教程(2)
Map/Reduce用户界面 本节为用户採用框架要面对的各个环节提供了具体的描写叙述,旨在与帮助用户对实现.配置和调优进行具体的设置.然而,开发时候还是要相应着API进行相关操作. 首先我们须要了解M ...
- Hadoop Map/Reduce
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集.一个Map/Reduce ...
- java 写一个 map reduce 矩阵相乘的案例
1.写一个工具类用来生成 map reduce 实验 所需 input 文件 下面两个是原始文件 matrix1.txt 1 2 -2 0 3 3 4 -3 -2 0 2 3 5 3 -1 2 -4 ...
- Hadoop Map/Reduce的工作流
问题描述 我们的数据分析平台是单一的Map/Reduce过程,由于半年来不断地增加需求,导致了问题已经不是那么地简单,特别是在Reduce阶段,一些大对象会常驻内存.因此越来越顶不住压力了,当前内存问 ...
- Java操作Hadoop集群
mavenhdfsMapReduce 1. 配置maven环境 2. 创建maven项目 2.1 pom.xml 依赖 2.2 单元测试 3. hdfs文件操作 3.1 文件上传和下载 3.2 RPC ...
- Hadoop学习笔记(三):java操作Hadoop
1. 启动hadoop服务. 2. hadoop默认将数据存储带/tmp目录下,如下图: 由于/tmp是linux的临时目录,linux会不定时的对该目录进行清除,因此hadoop可能就会出现意外情况 ...
- Hadoop Map/Reduce 示例程序WordCount
#进入hadoop安装目录 cd /usr/local/hadoop #创建示例文件:input #在里面输入以下内容: #Hello world, Bye world! vim input #在hd ...
- C#、JAVA操作Hadoop(HDFS、Map/Reduce)真实过程概述。组件、源码下载。无法解决:Response status code does not indicate success: 500。
一.Hadoop环境配置概述 三台虚拟机,操作系统为:Ubuntu 16.04. Hadoop版本:2.7.2 NameNode:192.168.72.132 DataNode:192.168.72. ...
随机推荐
- vue集成ckeditor富文本框,怎么获取CKEditor实例?
CKEDITOR 版本5 ,vue集成形式 vue集成ckeditor富文本框,由于不是通过js创建的富文本对象,所以,无法取得实例对象,官方说明 官方在builds-->Getting and ...
- Jpa设置默认值约束
使用SpringDataJpa设置字段的默认值约束的2种方式 // 第一种方式是修改建表时的列定义属性 @Column(columnDefinition = "varchar(35) def ...
- JavaScript 表单事件
表单事件,当用户与表单元素进行交互时发生. 实例: 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <title>表单事件& ...
- 学习GlusterFS(三)
glusterfs,GNU cluster file system,创始人Anand Babu Periasamy,目标:代替开源Lustre和商业产品GPFS,glusterfs是什么: cloud ...
- 学习Kvm(三)
虚拟化(将一个物理硬件平台虚拟成多个) vmware(模拟出一堆硬件设备,每一个硬件设备都是独立平台) 虚拟化要解决的问题(硬件之上的OS,有用户空间.内核空间:vmware虚拟机所模拟出的多个硬件平 ...
- Arthas之实例操作
Arthas之实例操作 1. 静态类属性操作 获取public静态属性 ognl -c 7cd84586 '@com.system.framework.ArtahsDemoClassLoader@pu ...
- Python - 分支循环、可迭代对象与迭代器
- jsp技术之JSLT技术<c:if text="">判断
JSLT的c:if标签 作用:用来进行判断的 语法: <c:if test="判断条件,使用EL表达式进行判断"> 如果判断为true,这里的内容会生效:如果为fals ...
- css3 弹性布局和多列布局
弹性盒子基础 弹性盒子(Flexible Box)是css3中盒子模型的弹性布局,在传统的布局方式上增加了很多灵活性. 定义一个弹性盒子 在父盒子上定义display属性: #box{ display ...
- 【二次元的CSS】—— 用 DIV + CSS3 画大白(详解步骤)
原本自己也想画大白,正巧看到一位同学(github:https://github.com/shiyiwang)也用相同的方法画了. 且细节相当到位.所以我就fork了一下,在此我也分享一下.同时,我也 ...