OCR 文字检测(Differentiable Binarization --- DB)
文本检测
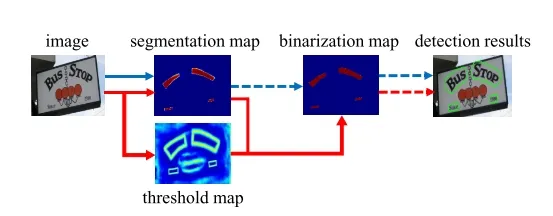
基于分割的做法(如蓝色箭头所示):
传统的pipeline使用固定的阈值对于分割后的热力图进行二值化处理
- 首先,它们设置了固定的阈值,用于将分割网络生成的概率图转换为二进制图像
- 然后,用一些启发式技术(例如像素聚类)用于将像素分组为文本实例
DB的做法(如红色箭头所示):
而本文提出的pipeline会将二值化操作嵌入到分割网络中进行组合优化,会生成与热力图对应的阈值图,通过二者的结合生成最终的二值化操作。
- 在得到 分割map后,与网络生成的threshold map一次联合做可微分二值化得到二值化图,然后再经过后处理得到最终结果。
- 将二值化操作插入到分段网络中以进行联合优化,通过这种方式,可以自适应地预测图像每个位置的阈值,从而可以将像素与前景和背景完全区分开。 但是,标准二值化函数是不可微分的,因此,我们提出了一种二值化的近似函数,称为可微分二值化(DB),当训练时,该函数完全可微分。将一个固定的阈值训练为一个可学习的每个位置的阈值
标签生成
首先看label是如何生成的,网络要学习的目标gt 与 threshold map是怎样的生成和指导网络去训练的,知道threshold_map的label值跟gt的值,我们才能更好地去理解“可微分二值化”是如何实现的;
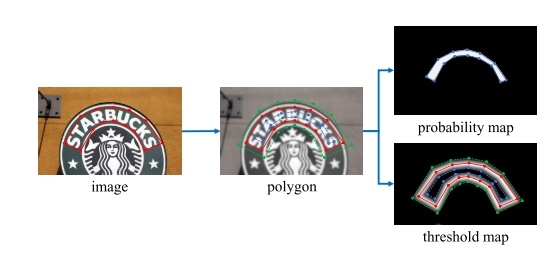
给定一张文字图像,其文本区域的每个多边形由一组线段描述:
\(\ G = \{s_k\}^n_{k = 1}\)
其中,n表示顶点的数量
使用Vatti clipping algorithm (Vati 1992)缩小多边形,对 gt 多边形(polygon) 进行缩放;收缩偏移量(offset of shrinking)\(D\) 可以通过周长 \(L\) 和面积 \(A\) 计算:
\(\ D = \frac {A(1-r^2)}{L}\)
其中,\(r\) 是缩放比例,依经验一般取值为 0.4
- 这样我们就通过 gt polygon 形成 缩小版的 polygon 的gt mask图 probability map(蓝色边界)
- 以同样的 offset D 从多边形polygon \(G\) 拓展到 \(G_d\) ,得到如图中 threshold_map中的(绿色边界)
threshold_map中由 \(G_s\) 到 \(G_d\) 之间形成了一个文字区域的边界。
一组图来可视化图像生成的结果:
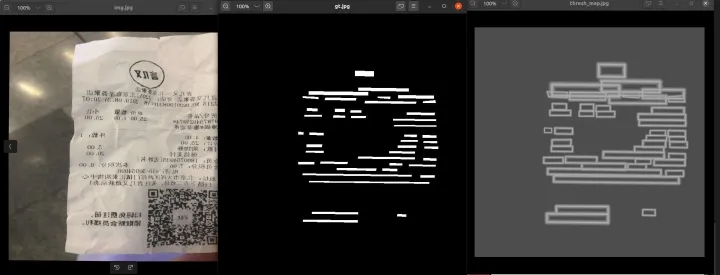
我们可以看到 probability map 的 gt 是一个完全的0,1 mask ,polygon 的缩小区域为1,其他背景区域为0;
但是在threshold_map文字边框值并非0,1;
使用PyCharm的view array 我们能看到threshold_map中文字边框的数值信息:
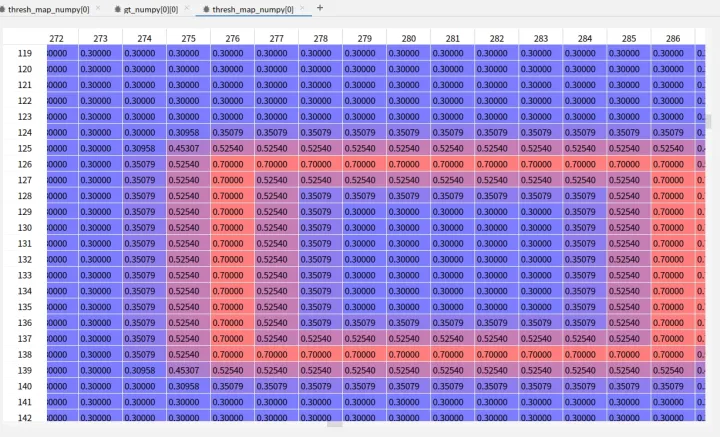
文字最外圈边缘为0.7,靠近中心区域是为0.3的值。(0.3-0.7为预设的阈值最大最小值)。我们可以看到文字边界为阈值最大,然后根据文字实例边缘距离逐渐递减。
知道threshold_map的label值跟gt的值,我们才能更好地去理解“可微分二值化”是如何实现的;
获取边界框

整体流程如图所示:
- backbone网络提取图像特征
- 类似FPN网络结构进行图像特征融合后得到两个特征图 probability map 跟 threshold map
- probability map 与threshold map 两个特征图做DB差分操作得到文字区域二分图
- 二分图经过cv2 轮廓得到文字区域信息
首先,图片通过特征金字塔结构的backbone,通过上采样的方式将特征金字塔的输出变换为同一尺寸,并级联(cascade)产生特征F;然后,通过特征图F预测概率图(P — probability_map)和阈值图(T — threshold_map); 最后,通过概率图P和阈值图T生成近似的二值图(B — approximate_binary_map)。
在训练阶段,监督被应用在阈值图、概率图和近似的二值图上,其中后两者共享同一个监督;在推理阶段,则可以从后两者轻松获取边界框。
可微的二值化(Differentiable binarization)
传统的阈值分割做法为:
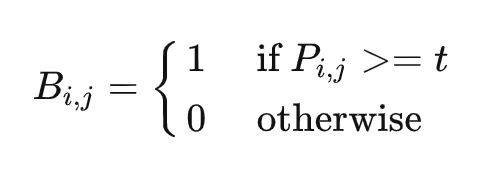
$\ B_{i,j} $ 代表了probability_map中第i行第j列的概率值。这样的做法是硬性将概率大于某个固定阈值的像素作为文字像素,而不能将阈值作为一个可学习的参数对象(因为阈值分割没办法微分进行梯度回传)
可微分的二值化公式:
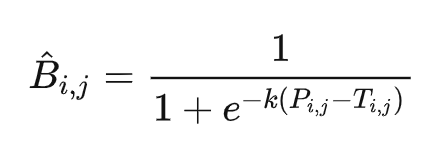
首先,该公式借鉴了sigmod函数的形式(sigmod 函数本身就是将输入映射到0~1之间),所以将概率值 $\ P_{i,j} $ 与阈值 $\ T_{i,j} $ 之间的差值作为sigmod函数的输出,然后再经过放大系数 \(k\), 将其输出无限逼近两个极端 0 或者1;其中,k为放大因子,依经验设定为 50
带有自适应阈值的可微分二值化不仅有助于把文字区域与背景区分开,而且还能把相近的实例分离开来。
我们来根据label generation中的gt 与 threshold_map来分别计算下。经过这个可微分二值化的sigmod函数后,各个区域的像素值会变成什么样子:
文字实例中心区域像素:
- probability map 的gt为 1
- threshold map的gt值为0.3
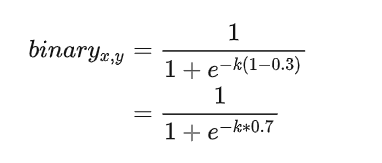
如果不经过放大系数K的放大,那么区域正中心的像素如上图所示经过sigmod函数后趋向于0.6左右的值。但是经过放大系数k后,会往右倾向于1。
文字实例边缘区域像素:
- probability map 的gt为 1
- threshold map的gt值为0.7
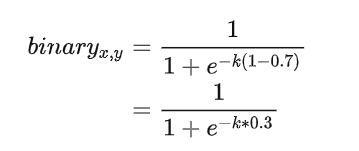
如果不经过放大系数K的放大,那么区域正中心的像素如上图所示经过sigmod函数后趋向于0.5左右的值。但是经过放大系数k后,会往右倾向于1。
文字实例外的像素:
- probability map 的gt为 0
- threshold map的gt值为0.3
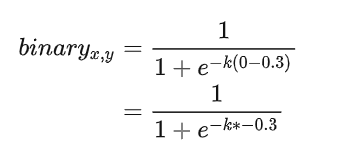
经过放大系数k后,激活值会无限趋近于0; 从而实现二值化效果。
解释了DB利用类似sigmod的函数是如何实现二值化的效果,那么我们来看其梯度的学习性:
传统二值化是一个分段函数,如下图所示:
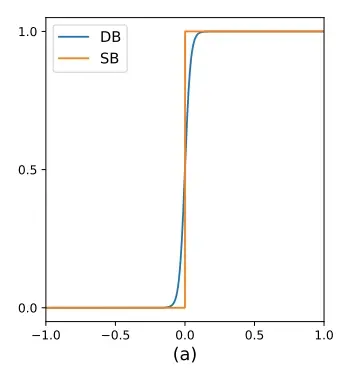
SB:standard binarization其梯度在0值被截断无法进行有效地回传。 DB:differentiable binarization是一个可微分的曲线,可以利用训练数据+优化器的形式进行数据驱动的学习优化。
我们来看其导数公式,假设 \(l_+\) 代表了正样本, \(l_-\) 代表了负样本,则:
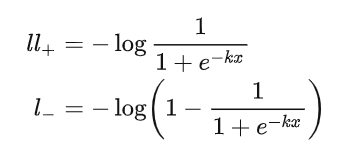
根据链式法则我们可以计算其loss梯度
百度paddle中提供的接口可以实现下面的效果:

摘自:
https://zhuanlan.zhihu.com/p/235377776
https://www.cnblogs.com/monologuesmw/p/13223314.html#top
OCR 文字检测(Differentiable Binarization --- DB)的更多相关文章
- ocr 文字区域检测及识别
ocr 文字区域检测及识别 # coding=utf- from PIL import Image, ImageFilter, ImageEnhance from skimage.filters im ...
- OCR场景文本识别:文字检测+文字识别
一. 应用背景 OCR(Optical Character Recognition)文字识别技术的应用领域主要包括:证件识别.车牌识别.智慧医疗.pdf文档转换为Word.拍照识别.截图识别.网络图片 ...
- 云+社区分享——腾讯云OCR文字识别
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云+社区运营团队发布在腾讯云+社区 前言 2018年3月27日腾讯云云+社区联合腾讯云智能图像团队共同在客户群举办了腾讯云OCR文字识 ...
- 如何精准实现OCR文字识别?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云计算基础发表于云+社区专栏 前言 2018年3月27日腾讯云云+社区联合腾讯云智能图像团队共同在客户群举办了腾讯云OCR文字识别-- ...
- Android OCR文字识别 实时扫描手机号(极速扫描单行文本方案)
身份证识别:https://github.com/wenchaosong/OCR_identify 遇到一个需求,要用手机扫描纸质面单,获取面单上的手机号,最后决定用tesseract这个开源OCR库 ...
- OCR文字识别笔记总结
OCR的全称是Optical Character Recognition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别,交通路牌的识别,车牌的自动识别等等.本 ...
- 王晶:华为云OCR文字识别服务技术实践、底层框架及应用场景 | AI ProCon 2019
演讲嘉宾 | 王晶(华为云人工智能高级算法工程师王晶) 出品 | AI科技大本营(ID:rgznai100) 近期,由 CSDN 主办的 2019 中国AI 开发者大会(AI ProCon 2019) ...
- OCR文字识别在计算机视觉的重要性、基本技术和最新进展
[摘要] 主要是文字检测和文字识别作为计算机视觉一部分的重要性,基本知识,面临的挑战,以及部分最新的成果. 人类认识了解世界的信息中91%来自视觉,同样计算机视觉成为机器认知世界的基础,也是人工智能研 ...
- 怎么给OCR文字识别软件重编文档页面号码
ABBYY FineReader Pro for Mac OCR文字识别软件处理文档时,在FineReader文档中,页面的加载顺序即是页面的导入顺序,完成导入之后,文档的所有页面均会被编号,各编号会 ...
- OCR文字设别软件没有权限管理服务器上的许可证怎么办
在使用ABBYY产品,无论是ABBYY FineReader 12,还是ABBYY PDF Transformer+的时候,当你启动许可管理器时,可能会出现"您没有权限管理许可服务器(服务器 ...
随机推荐
- python 调试 qml
1.设置pycharm的parameters -qmljsdebugger=port:10002,block 2.python 启动调试: 点击debug按钮 3.设置qt creater qt cr ...
- 使用react-vite-antd,修改antd主题,报错 [vite] Internal server error: Inline JavaScript is not enabled. Is it set in your options? It is hacky way to make this function will be compiled preferentially by less
一般报错 在官方文档中,没有关于vite中如何使用自定义主题的相关配置,经过查阅 1.安装less yarn add less (已经安装了就不必再安装) 2.首先将App.css改成App.les ...
- webpack之性能优化(webpack4)
在讲解性能优化的方案之前,我们需要了解一下webpack的整个工作流程, 方案一:减少模块解析 也就是省略了构建chunk依赖模块的这几个步骤 如果没有loader对该模块进行处理,该模块的源码就是最 ...
- egret 图片跨域
//图片跨域 egret.ImageLoader.crossOrigin = "anonymous";
- 重构:banner 中 logo 聚合分散动画
1. 效果展示 在线查看 2. 开始前说明 效果实现参考源码:Logo 聚集与散开 原效果代码基于 react jsx 类组件实现.依赖旧,代码冗余. 我将基于此进行重构,重构目标: 基于最新依赖包, ...
- 机器学习(二):感知机+svm习题 感知机手工推导参数更新 svm手推求解二维坐标超平面直线方程
作业1: 输入: 训练数据集 \(T = {(x1; y1); (x2; y2),..., (xN; yN)}\) 其中,\(x \in R^n\), \(y \in Y = \{+1, -1\}\) ...
- 自己动手从零写桌面操作系统GrapeOS系列教程——18.外设和IO
学习操作系统原理最好的方法是自己写一个简单的操作系统. 一.外设和I/O接口 前面我们介绍过冯·诺依曼结构包含5部分,其中输入设备和输出设备统称为外部设备,简称外设.常见的外设有鼠标.键盘.显示器.硬 ...
- 使用EFCore的Code First和MySql数据库迁移
1. 感慨一下 随着.net core的持续更新和升级,至少对于从事.net开发的人员和即将踏入这个领域的人来说,我相信大家的热情还是持续高涨的.国内的.net开发生态相比于之前来说,还是大有所好转的 ...
- ACM-NEFUOJ-P209湖南修路
思路 prim的最小生成树,套上肝就完事了 代码 #include<iostream> #include<cstdio> #include<string.h> #d ...
- day60:Linux压缩与打包&用户管理&用户提权sudo&grep,sed,awk,sort,uniq
目录 1.文件管理-压缩与打包 2.用户管理 用户怎么查 如何创建用户 创建的用户信息都存储在哪? 用户存储密码的文件 如何为用户设定密码? 3.用户组 4.用户提权相关 5.Extra:额外补充 文 ...